源自:python (programming language): what are the best python scripts you’ve ever written?想看到更多的更酷的东西 :- | 回复内容:
我们公司办公环境是window,开发环境是unix(可以近似认为所有人工作在同一台机器上,大部分人的目录权限都是755。。。),为了防止开发代码流出到外网,windows与unix之间没有网络连接,我们只能远程登陆到一个跳转服务器再远程登陆到unix上,如果有unix网内的文件需要传出到windows网中,需要领导严格审批(反方向没问题,有专用ftp服务器)。对于通信专业毕业的我,最不能忍受的场景就是没有建立起双向通信。于是,为了可以将unix网内的数据传出来,我用python将二进制数据转化为图像,每个像素点可以表示3个字节,再将图像外围增加宽度为1的黑色边框,外面再增加宽度为1像素的白色边框,作为图像边界的标识符。这样,我在windows下截图,用python进行逆操作,数据就完好的解出来了!这样一次至少可以传1mb多的文件(屏幕越大传的越多),7z压缩一下,可以传很多文本了。如果需要传更多,还可以搞成动画。。。脚本一共只有几十行,却大大提高了我后来工作的效率。python好爽,我爱python!
说两个和知乎相关的。因为我本人并不认可“问题是大家的”的观点,对每个人都可以编辑问题这个设定表示接受但不认同。所以每次看到有好事者把问题原题改得面目全非的时候,感觉就像吃了死苍蝇一样恶心。(虽然有问题日志,但是大多数群众不会去看。)终于有一天,我被某人恶心得受不了了,就用python写了一个脚本:对于某个问题,每10秒刷新一次,当发现有人把问题改动得和设想的不一样,那就再自动改回来——这不是什么过激手段,也只不过利用规则而已。这个脚本至今用过两次,看日志,着实恶心到了几个所谓“公共编辑计划”的同学——想象下,偷偷摸摸凌晨两三点修改问题,不到10秒就被改回原样,那种抓狂的表情。另一个例子,我本人喜欢关注妹子,所以关注的人很多,这样带来几个问题:一个是tl太杂,一个是逼格不够高。所以需要定时清理一下。于是写脚本抓取了所以关注人的性别、问题数、赞同数、近期活跃时间等等特征,然后提取一百个作为训练数据,人工标注是否需要取关,再使用线性模型训练,判断哪些关注的价值比较低,好定期清理。(目前还没有清理过,因为还在对关注者价值机器学习的结果进行评估。)作为程序员,自娱自乐还是有些意思的,python干这些很顺手。
想起以前和沈游侠聊天的一个笑话代码开始 true, false = false, true然后开始写 python 程序
谢邀。当年玩 http://projecteuler.net/ 的时候写过一些很鸡贼的小脚本,有兴趣可以看看 https://github.com/riobard/project-euler/blob/master/euler.py
python 在线编辑器这是我用 python 写的一个可以在网页上编写并执行 python 代码的编辑器。支持基本的语法和模块。但出于安全考虑(当然也因为没怎么去完善),功能还比较受限。写代码的时候可以自动补全,不过这是js的事情,跟python无关。两年多前写的,最近又稍微优化了一下,增加了几个语法和模块的支持。另外增加了几十个教学例程。做这个的目的是想方便公众号读者在微信里面直接试验代码。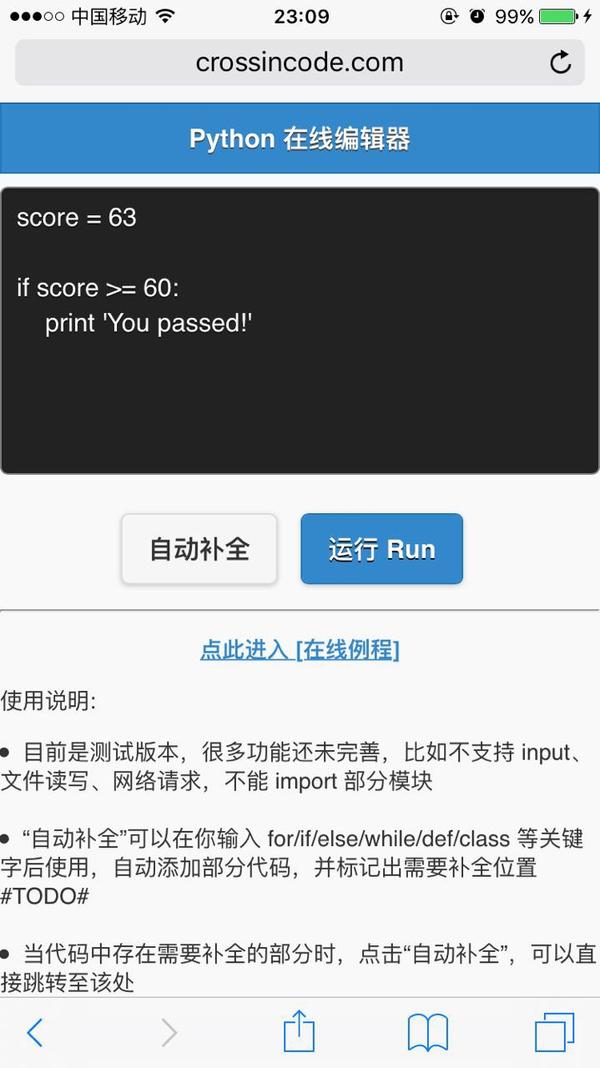

不到两百行代码实现goagent
github – larva-lang/larva-lang: the larva programming language
确认安装好urllib2和webscraping库,然后粘贴此代码到pythonide里运行,过一会儿打开d盘的f.txt 你懂的!
# -*- coding: utf-8 -*-
__author__ = ‘ftium4.com’
#导入urllib2库,用于获取网页
import urllib2
#使用开源库webscraping库的xpath模块
from webscraping import xpath,common
def get_data(url):
req = urllib2.request(url)
req.add_header(‘user-agent’, ‘mozilla/5.0 (windows; u; windows nt 5.1; zh-cn; rv:1.8.1.14) gecko/20080404 (foxplus) firefox/2.0.0.14’)
#获得响应
reponse = urllib2.urlopen(req)
#将响应的内容存入html变量
html = reponse.read()
#以下抓取页面的番号和片名
title = xpath.search(html, ‘//p[@]/a[1]/@title’)
return title
#创建文本用于保存采集结果
f=open(r’d:\f.txt’,’w’)
for p in range(1,494):
url = r’http://dmm18.net/index.php?pageno_b=%s’%p
print url
title = get_data(url)
for item1 in title:
#将采集结果写入文本中
f.write(str(item1)+’\n’)
print item1
f.close()
写过一个迅雷云播推送到xbmc上播放的脚本,很简单,也没什么技术含量,但是对于喜欢看电影的人,真的是一大福利啊,免费使用迅雷云播,通过xbmc用大电视看高清脚本地址https://gist.github.com/zhu327/987f3fc288ca55939e73xbmc是在树莓派上用的,一般720p+外挂字幕毫无压力,另外附上树莓派用xbmc心得一篇http://bozpy.sinaapp.com/blog/13
输入动漫名(模糊匹配)和集数,直接获取到下载url,贴到迅雷马上使用http://www.kylen314.com/archives/5729