0.这个问题虽说是找寻“奇技淫巧”,但其实是想抛砖引玉1.如果想把自己认为或好玩或强大的python使用技巧拿出来跟大家分享,可否稍微详细的讲解一下回复内容:
从 python 2.3 开始,sys 包有一个属性,叫 meta_path 。可以通过给 sys.meta_path 注册一个 finder 对象,改变 import 的行为。甚至可以实现这样的功能:通过 import 来导入一个 json 文件中的数据。举个例子,有一个 tester.json 文件,里面的内容是:
{
“hello”: “world”,
“this”: {
“can”: {
“be”: “nested”
}
}
}
更新一个最近发现的技巧,一行代码实现多线程/多进程,来源于python开发者微信公众号。首先来看下代码:import urllib2 from multiprocessing.dummy import pool as threadpool urls = [ ‘http://www.python.org’, ‘http://www.python.org/about/’, ‘http://www.onlamp.com/pub/a/python/2003 ]pool = threadpool(4) results = pool.map(urllib2.urlopen, urls)pool.close() pool.join() 对,你没有看错,只要一行代码就可以把普通的任务变成并行任务。不用手动管理线程,一切都由map自动完成。这里演示的是多线程,如果要多进程的话只需把 from multiprocessing.dummy 改成 from multiprocessing ,就是这么任性!以下为这个库的详细介绍:在 python 中有个两个库包含了 map 函数: multiprocessing 和它鲜为人知的子库 multiprocessing.dummy.这里多扯两句: multiprocessing.dummy? mltiprocessing 库的线程版克隆?这是虾米?即便在 multiprocessing 库的官方文档里关于这一子库也只有一句相关描述。而这句描述译成人话基本就是说:”嘛,有这么个东西,你知道就成.”相信我,这个库被严重低估了!dummy 是 multiprocessing 模块的完整克隆,唯一的不同在于 multiprocessing 作用于进程,而 dummy 模块作用于线程(因此也包括了 python 所有常见的多线程限制)。所以替换使用这两个库异常容易。你可以针对 io 密集型任务和 cpu 密集型任务来选择不同的库。原文链接 : http://mp.weixin.qq.com/s?__biz=mza4mjeynta5mw==&mhttps://pic2.zhimg.com/2b9d0cab6dc3f600be7f9c8250117c4d_b.jpg” data-rawwidth=”648″ data-rawheight=”242″ width=”648″ data-original=”https://pic2.zhimg.com/2b9d0cab6dc3f600be7f9c8250117c4d_r.jpg”> 在python中,下滑杠代表上一次运行的结果。不要问我为什么,我也不知道。这个奇技淫巧是我在查scapy的资料的时候意外发现的,网上关于这个技巧的资料似乎也很少,嗯。(顺便提一下,scapy是个非常强大的库,几乎涵盖了所有网络相关的功能,推荐学习。)再来说一个吧,关于动态修改代码的。直接上代码:
在python中,下滑杠代表上一次运行的结果。不要问我为什么,我也不知道。这个奇技淫巧是我在查scapy的资料的时候意外发现的,网上关于这个技巧的资料似乎也很少,嗯。(顺便提一下,scapy是个非常强大的库,几乎涵盖了所有网络相关的功能,推荐学习。)再来说一个吧,关于动态修改代码的。直接上代码:
# socket.py
#
import sys
del sys.modules[‘socket’] # 从内存中删除当前的socket包
import sys
import time
import logging
import types
path = sys.path[0]
sys.path.pop(0)
import socket # 导入真正的socket包
sys.path.insert(0, path)
# 动态path类方法
def re_class_method(_class, method_name, re_method):
method = getattr(_class, method_name)
info = sys.version_info
if info[0] >= 3: # py2和py3的语法略有不同,需要做下判断。
setattr(_class, method_name,
types.methodtype(lambda *args, **kwds: re_method(method, *args, **kwds), _class))
else:
setattr(_class, method_name,
types.methodtype(lambda *args, **kwds: re_method(method, *args, **kwds), none, _class))
# 动态path实例方法
def re_self_method(self, method_name, re_method):
method = getattr(self, method_name)
setattr(self, method_name, types.methodtype(lambda *args, **kwds: re_method(method, *args, **kwds), self, self))
# 需要修改的类方法
def re_accept(old_method, self, *args, **kwds):
return_value = old_method(self, *args, **kwds)
#do something
return return_value
# 需要修改的实例方法
def re_recvfrom(old_method, self, *args, **kwds):
return_value = old_method(*args, **kwds)
# do something
return return_value
# 需要修改的类方法(无返回值)
def re_bind(old_method, self, *args, **kwds):
re_self_method(self, ‘recvfrom’, re_recvfrom) #把self实例的recvfrom方法替换成re_recvfrom
#do something
old_method(self, *args, **kwds)
setattr(socket.socket, ‘_list_client_ip’, {}) # 绑定类属性(socket不能动态绑定实例属性,只好绑定类属性了)
re_class_method(socket.socket, ‘bind’, re_bind) #把socket类的bind方法替换成re_bind
re_class_method(socket.socket, ‘accept’, re_accept) #把socket类的accept方法替换成re_accept
也有一个 python 的奇技淫巧分享给大家,让 python 的 2+2=5:
in [1]: import ctypes
in [2]: ctypes.memmove(id(4), id(5), 24)
out[2]: 15679760
in [3]: 2 + 2
out[3]: 5
刚好看到个
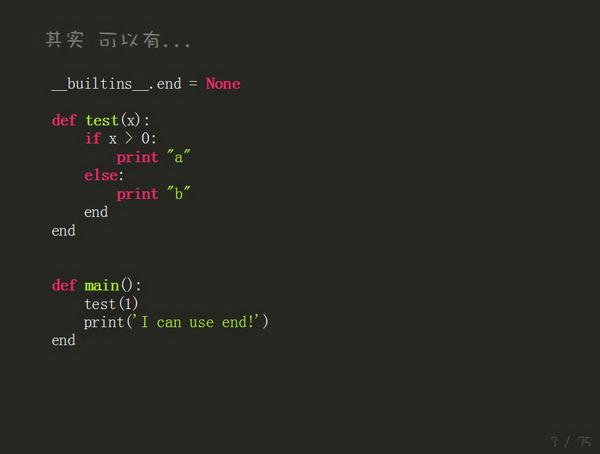 来自于 来自于 python高级编程 作者是 @董伟明 说明在分享一个准备给公司讲python高级编程的slide 这里还有对应的视频讲解====================================================================另外一个感觉就是这个库了ajalt/fuckitpy · github 中间的实现挺厉害的,访问源码逐行加入try: finally
来自于 来自于 python高级编程 作者是 @董伟明 说明在分享一个准备给公司讲python高级编程的slide 这里还有对应的视频讲解====================================================================另外一个感觉就是这个库了ajalt/fuckitpy · github 中间的实现挺厉害的,访问源码逐行加入try: finally
python没有什么奇技淫巧吧。。。hidden features of python 这个链接上有很多小例子比如for else值得说下。不break的话就执行else
for i in range(10):
if i == 10:
break
print(i)
else:
print(’10不在里面!’)
其实 pyc 文件很简单:
>>> import dis, marshal
>>> with open(‘hello.pyc’, ‘rb’) as f:
… f.seek(8)
… dis.dis(marshal.load(f))
昨天刚在 stackoverflow 看到的,break 多层循环:python – breaking out of nested loops
for x in xrange(10):
for y in xrange(10):
print x*y
if x*y > 50:
break
else:
continue # executed if the loop ended normally (no break)
break # executed if ‘continue’ was skipped (break)
可配置单例,从tornado学来的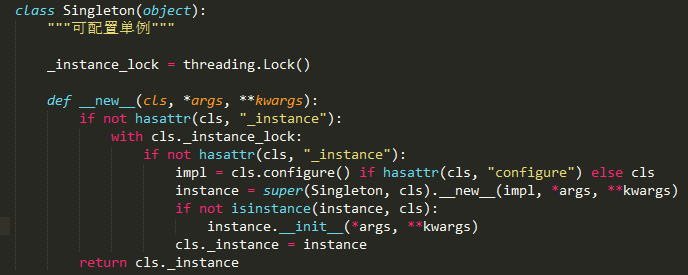
stack overflow上有一个多人编辑整理的答案,非常全而且经常更新:hidden features of python收藏这个页面,顺便给我的回答点个赞同啊。
1. 元类(metaclass)pypy的源码里有个pair和extendabletype
“””
two magic tricks for classes:
class x:
__metaclass__ = extendabletype
…
# in some other file…
class __extend__(x):
… # and here you can add new methods and class attributes to x
mostly useful together with the second trick, which lets you build
methods whose ‘self’ is a pair of objects instead of just one:
class __extend__(pairtype(x, y)):
attribute = 42
def method((x, y), other, arguments):
…
pair(x, y).attribute
pair(x, y).method(other, arguments)
this finds methods and class attributes based on the actual
class of both objects that go into the pair(), with the usual
rules of method/attribute overriding in (pairs of) subclasses.
for more information, see test_pairtype.
“””
class extendabletype(type):
“””a type with a syntax trick: ‘class __extend__(t)’ actually extends
the definition of ‘t’ instead of creating a new subclass.”””
def __new__(cls, name, bases, dict):
if name == ‘__extend__’:
for cls in bases:
for key, value in dict.items():
if key == ‘__module__’:
continue
# xxx do we need to provide something more for pickling?
setattr(cls, key, value)
return none
else:
return super(extendabletype, cls).__new__(cls, name, bases, dict)
def pair(a, b):
“””return a pair object.”””
tp = pairtype(a.__class__, b.__class__)
return tp((a, b)) # tp is a subclass of tuple
pairtypecache = {}
def pairtype(cls1, cls2):
“””type(pair(a,b)) is pairtype(a.__class__, b.__class__).”””
try:
pair = pairtypecache[cls1, cls2]
except keyerror:
name = ‘pairtype(%s, %s)’ % (cls1.__name__, cls2.__name__)
bases1 = [pairtype(base1, cls2) for base1 in cls1.__bases__]
bases2 = [pairtype(cls1, base2) for base2 in cls2.__bases__]
bases = tuple(bases1 + bases2) or (tuple,) # ‘tuple’: ultimate base
pair = pairtypecache[cls1, cls2] = extendabletype(name, bases, {})
return pair