用python 做策略回测,耗时很长。40万条数据花了快一个小时。想问下,通常50万数量级的数据的回测用时多少?(简单策略,一支股票一年的tick差不多40万) 有什么加速办法?—————————————————————————————–分割线首先真诚感谢各位帮助。回馈知乎,附上我最后的处理方法。本人最后使用了cython 来处理python 中for loop 的部分, 运行时间缩短显著。建议无法对数据实行整列计算,而只能选择loop, 逐个数据递推,来生成一列数据的情况。可以使用cython处理loop部分。 直接上图,下面是一个生成列的小测试,分别计算两种方法效率。用时相差2个数量级。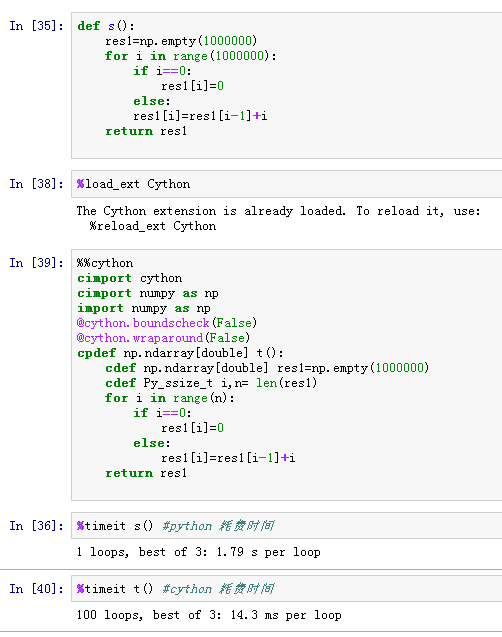 回复内容:
回复内容:
少用for,尽量用numpy/pandas的向量化方法。少用自己写的python方法,先看看numpy /pandas是不是已有现成的功能。有几个numpy 的加速包,比如numexpr.安装intel mkl.最后,可以讲关键部分用c/c++实现。如果无法避开python的for,建议使用numba来提速,理想情况下可以达到和numpy向量化差不多的速度。我只能帮你到这里了||-_-
我觉得多少是你的算法有问题。在排除算法问题后可以用pypy尝试加速一下。
2016.4.19做的回测,80万条数据用了3分半跑完(四进程)。用python想降低回测时延,可以从下面几个角度下功夫:1.有几个cpu核开几个进程,记得不是线程是进程。2.在数据结构和算法上下功夫。3.在cpu cache命中率上下功夫,loop时操作的数据尽可能在内存上紧凑,不要在loop里遍历pandas的列,因为这会导致cache命中率大幅降低。而cpu访问内存的时延远在访问cache之上。楼主回测时延高问题应该就出在这里。可以把pandas的列转换成list再在loop中使用。
可以考虑先用更大的barsize,再优化你的程序,各种加速等等。
楼主做的tick级的回测,一次几只股票回测几年?
如果楼主长期做类似工作,且不是专业码农,最低成本的办法还是:1.升级高频cpu(假设楼主你就简单写写,不做并行计算,python毕竟全局解释锁)2.原代码大量用数据库就上ssd/内存表,大量读磁盘就用ramdisk,如果原代码就已经一次性载入内存就忽视这一条。3.用pypy,cython等不修改代码的优化方式。总结:先根据先有代码优化硬件,然后使用不需要修改(少修改)代码的优化方式。一般来说,硬件比人工便宜。如果这还不能解决问题,再用各种奇淫巧技。
先做profile,在耗时较多的地方,通常是for循环,用cython替换
没代码,没算法,没数据,没profile谈什么优化
python 算很快的了 题主用过matlab 就知道什么叫做慢了 实在不行换sas呗 40万条简单运算估计也就10-20min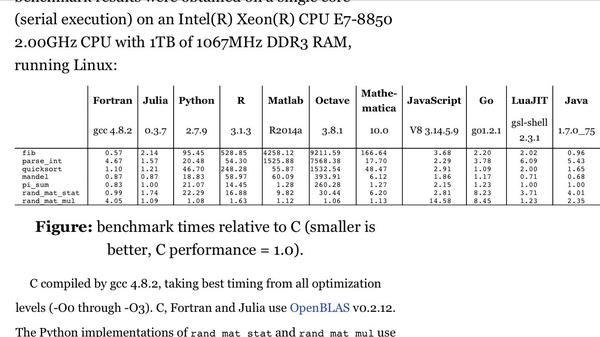

之前用过pandas处理过阿里巴巴大数据比赛的1000万行数据,反正速度是比较快的每次操作都是只有十几秒,可能做的方式不一样比较简单的操作吧,不过你那个的确稍微慢了点