回复内容:
c++ stl中的标准规定:* map, 有序* unordered_map,无序,这个就是用散列表实现
谈谈hashmap和map的区别,我们知道hashmap是平均o(1),map是平均o(lnn)的,实践上是不是hashmap一定优于map呢?这里面有几个因素要考虑:hashmap的内存效率比map差,这是显而易见的map的查找效率实践上是非常高的,如在1m数据中查找一个元素,需要多少次比较呢?20次。map的查找效率比hashmap稳定。hashmap查找时候要算hash,这个最坏时间复杂度是o(m)(m是key字符串的长度),如果你的key非常非常非常非常非常非常……长,基于比较的map通常只使用头几个字符进行比较,而hashmap要o(m)地算出hash内存布局会影响内存局部性,对性能会有影响
补一句,红黑树意味着对于键值它是有序存储,当你需要查找某一范围的键值时,非常方便。用时依然为(logn)。反之,若使用哈希,你将不得不去遍历整个值空间,用时(n)。
大多数时候,我们并不需要这个“有序”,即使在某些特殊情况下,我们需要的“有序”,也不是“动态且有序”,这里有个 0开销支持排序的 gold_hash_map,通用,并且比 std::unordered_xxx 和 google 的 spasre_xxx, dense_xxx 更快更省内存
标准规定map的元素必须是有序的,在满足标准的情况下,才能考虑效率。用散列表不能保证元素是有序的,所以不能用。
map,速度稳定,而且有序;hashtable,时而比map快一点,时而比map慢无数倍。挑食(找不到好的hash),易受骗(故意的数据碰撞)。非实时性场合,可以选择hashtable,因为从统计学上看它比map快;实时性场合,只能选map,因为他不会像hashtable那样有时慢得离谱。
侯捷老师在《stl源码剖析》一书的第5章提到了:hash table (散列表)及其衍生容器相当重要.它们未被纳入c++标准的原因是,提案太迟了。下一代c++标准程序库很有可能会纳入它们。在sgi stl中提供了hash table(散列表),以及以此hash table为底层机制而完成的hash_set (散列集合)、hash_map (散列映射表)、hash_multiset (散列多键集合)、hash_multimap(散列多键映射表)。在新的c++ stl中也引入了unorder_map。关于map与unordered_map的时间复杂度(查找)与空间复杂度请看stack overflow的答案c++ – is there any advantage of using map over unordered_map in case of trivial keys?
 答案主要是:1、map是有序的,unordered_map是无序的2、两者之间的查找速度不同(log(n)和n)3、由于hash要控制负载率在0-1之间,所以unordered_map消耗空间更大。具体的时间与空间消耗:
答案主要是:1、map是有序的,unordered_map是无序的2、两者之间的查找速度不同(log(n)和n)3、由于hash要控制负载率在0-1之间,所以unordered_map消耗空间更大。具体的时间与空间消耗: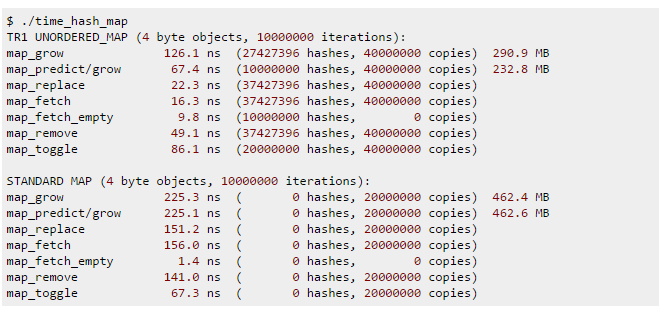
hash是普通dictionary抽象数据类型的一种实现,rbt是ordered dictionary抽象数据类型的一种实现。普通dictionary只支持search、insert、delete,ordered dictionary除了那三个操作外,还支持一些导航类的操作,如和一个给定key最邻近的key,最大key、最小key这些操作。两种dictionary的实现各有适用场景。
可能当初定c++标准库的时候,hash table还不流行。现在11的标准库加入了基于hash的unordered_set和unordered_map。另外,光看所谓的算法复杂度是不够的。log时间也许是一个很小的系数,而常数时间也许是一个很大的系数。
 试一下这几个函数,下次你对顺序没有要求时,你就会想用哈希而不是红黑树了试一下这几个函数,下次你对顺序没有要求时,你就会想用哈希而不是红黑树了
试一下这几个函数,下次你对顺序没有要求时,你就会想用哈希而不是红黑树了试一下这几个函数,下次你对顺序没有要求时,你就会想用哈希而不是红黑树了