我现有有一个工作,需要从新浪新闻网站中获取数据,包括,标题,正文,和参与人数。 如图所示想得到 820,但是动态产生的。该新闻的url为 陕西眉县发红头文件:官员卖水泥买房纳入考核我有话说这段代码产生的参与人数820,使用什么工具来获取?我想使用简单点的,可以完成上述工作的代码或 模块?谢谢大家回复内容:
如图所示想得到 820,但是动态产生的。该新闻的url为 陕西眉县发红头文件:官员卖水泥买房纳入考核我有话说这段代码产生的参与人数820,使用什么工具来获取?我想使用简单点的,可以完成上述工作的代码或 模块?谢谢大家回复内容:
楼上给的没错。像这种情况一般是异步请求json或者jsonp,直接监控network就行了:以chrome浏览器为例。1.右键页面-审查元素-network,切换到network面板,刷新页面。然后浏览器和web后端的通信会被记录下来。
 排除掉图片,css等。要获取当前新闻的评论数,浏览器发送给服务器的请求里面一定会有一个和当前新闻id有关的参数,(当然理论上也有通过referer来实现id传递的,但是毕竟太奇葩,不予考虑)。所以1. 如果method为get,在name里面一定有一个特殊的字符串,用来标识要请求的是哪个新闻的评论。2. 或者method为post,那么在post的参数里面会有一个能标识当前新闻的参数:
排除掉图片,css等。要获取当前新闻的评论数,浏览器发送给服务器的请求里面一定会有一个和当前新闻id有关的参数,(当然理论上也有通过referer来实现id传递的,但是毕竟太奇葩,不予考虑)。所以1. 如果method为get,在name里面一定有一个特殊的字符串,用来标识要请求的是哪个新闻的评论。2. 或者method为post,那么在post的参数里面会有一个能标识当前新闻的参数: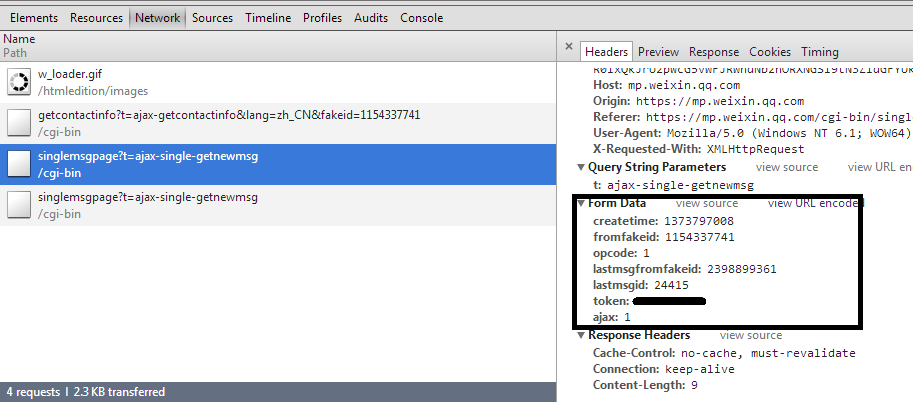 这是微信公众平台获取聊天信息的action,fromfakeid就是聊天对方的id。这是微信公众平台获取聊天信息的action,fromfakeid就是聊天对方的id。如果要用post方法获取某个新闻的评论数,在这里也会有一个参数用来标识出这个新闻。(比如“175827642839”)。然后一个个排查,图片css均不考虑,那么很容易就能找到http://comment5.news.sina.com.cn/page/info?format=js&channel=gn&newscount”: {“qreply”: 706, “total”: 823, “show”: 95},你要找的就在这里。可以直接从字符串里面截取到total,或者去掉js头部的“var data =”。得到一个json字符串,解析成对象也能获取total 。在新闻页面的源码里面找“1-1-27642839” 可以找到“newsid:’1-1-27642839′,”分析过程基本结束。然后,你可以:1.分析新闻页代码,得到newsid2.请求http://comment5.news.sina.com.cn/page/info?format=js&newsid=“newsid”3.解析获取到的js
这是微信公众平台获取聊天信息的action,fromfakeid就是聊天对方的id。这是微信公众平台获取聊天信息的action,fromfakeid就是聊天对方的id。如果要用post方法获取某个新闻的评论数,在这里也会有一个参数用来标识出这个新闻。(比如“175827642839”)。然后一个个排查,图片css均不考虑,那么很容易就能找到http://comment5.news.sina.com.cn/page/info?format=js&channel=gn&newscount”: {“qreply”: 706, “total”: 823, “show”: 95},你要找的就在这里。可以直接从字符串里面截取到total,或者去掉js头部的“var data =”。得到一个json字符串,解析成对象也能获取total 。在新闻页面的源码里面找“1-1-27642839” 可以找到“newsid:’1-1-27642839′,”分析过程基本结束。然后,你可以:1.分析新闻页代码,得到newsid2.请求http://comment5.news.sina.com.cn/page/info?format=js&newsid=“newsid”3.解析获取到的js
import selenium
from selenium import webdriver
from selenium.common.exceptions import nosuchelementexception
from selenium.webdriver.common.keys import keys
import time
browser = webdriver.firefox() # get local session of firefox
browser.get(“http://news.sina.com.cn/c/2013-07-11/175827642839.shtml “) # load page
time.sleep(5) # let the page load
try:
element = browser.find_element_by_xpath(“//span[contains(@class,’f_red’)]”) # get element on page
print element.text # get element text
except nosuchelementexception:
assert 0, “can’t find f_red”
browser.close()
>>> from selenium import webdriver
>>> c = webdriver.chrome()
>>> c.get(‘http://news.sina.com.cn/c/2013-07-11/175827642839.shtml’)
>>> comment = c.find_element_by_id(‘media_comment’)
>>> count = comment.find_element_by_class_name(‘f_red’)
>>> count.text
u’823′
我曾今使用python类库webkitgtk来解析网页,抽取html结构,获取数据,不过webkitgtk安装和使用过程略蛋疼,而且需要安装特定的版本,才可以操作获取数据。
您好,我看了您的硕士毕业论文,我也对这个论文推荐这个主题很感兴趣,但是我没能看懂您在lda基础上改进的tv-idf这个算法,利用4-2公式算不出您在4-3表中的tv-ipf的值,您能解释或者把具体的计算过程给我看一下吗?谢谢
使用 ghost.py 模块,模拟浏览器打开网页,获取的网页就是动态生成的。