用python加“验证码”为关键词在baidu里搜一下,可以找到很多关于验证码识别的文章。我大体看了一下,主要方法有几类:一类是通过对图片进行处理,然后利用字库特征匹配的方法,一类是图片处理后建立字符对应字典,还有一类是直接利用ocr模块进行识别。不管是用什么方法,都需要首先对图片进行处理,于是试着对下面的验证码进行分析。
一、图片处理
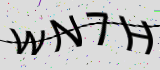
这个验证码中主要的影响因素是中间的曲线,首先考虑去掉图片中的曲线。考虑了两种算法:
第一种是首先取到曲线头的位置,即x=0时,黑点的位置。然后向后移动x的取值,观察每个x下黑点的位置,判断前后两个相邻黑点之间的距离,如果距离在一定范围内,可以基本判断该点是曲线上的点,最后将曲线上的点全部绘成白色。试了一下这种方法,结果得到的图片效果很一般,曲线不能完全去除,而且容量将字符的线条去除。
第二种考虑用单位面积内点的密度来进行计算。于是首先计算单位面积内点的个数,将单位面积内点个数少于某一指定数的面积去除,剩余的部分基本上就是验证码字符的部分。本例中,为了便于操作,取了5*5做为单位范围,并调整单位面积内点的标准密度为11。处理后的效果:
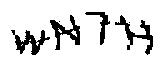
二、字符验证
这里我使用的方法是利用pytesser进行ocr识别,但由于这类验证码字符的不规则性,使得验证结果的准确性并不是很高。具体哪位大牛,有什么好的办法,希望能给指点一下。
三、准备工作与代码实例
1、pil、pytesser、tesseract
(1)安装pil:下载地址:http://www.pythonware.com/products/pil/
(2)pytesser:下载地址:http://code.google.com/p/pytesser/,下载解压后直接放在代码相同的文件夹下,即可使用。
(3)tesseract ocr engine下载:http://code.google.com/p/tesseract-ocr/,下载后解压,找到tessdata文件夹,用其替换掉pytesser解压后的tessdata文件夹即可。
2、具体代码
#encoding=utf-8
###利用点的密度计算
import image,imageenhance,imagefilter,imagedraw
import sys
from pytesser import *
#计算范围内点的个数
def numpoint(im):
w,h = im.size
data = list( im.getdata() )
mumpoint=0
for x in range(w):
for y in range(h):
if data[ y*w + x ] !=255:#255是白色
mumpoint+=1
return mumpoint
#计算5*5范围内点的密度
def pointmidu(im):
w,h = im.size
p=[]
for y in range(0,h,5):
for x in range(0,w,5):
box = (x,y, x+5,y+5)
im1=im.crop(box)
a=numpoint(im1)
if a