本文主要介绍了数据处理方面的内容,希望大家仔细阅读。
一、数据分析
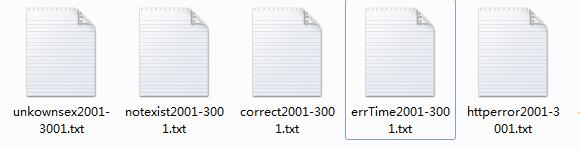
得到了以下列字符串开头的文本数据,我们需要进行处理

二、回滚
我们需要对httperror的数据进行再处理
因为代码的原因,具体可见本系列文章(二),会导致文本里面同一个id连续出现几次httperror记录:
//httperror265001_266001.txt
265002 httperror
265002 httperror
265002 httperror
265002 httperror
265003 httperror
265003 httperror
265003 httperror
265003 httperror
所以我们在代码里要考虑这种情形,不能每一行的id都进行处理,是判断是否重复的id。
java里面有缓存方法可以避免频繁读取硬盘上的文件,python其实也有,可以见这篇文章。
def main():
reload(sys)
sys.setdefaultencoding(‘utf-8′)
global sexre,timere,notexistre,url1,url2,file1,file2,file3,file4,startnum,endnum,file5
sexre = re.compile(u’em>\u6027\u522b(.*?)\u4e0a\u6b21\u6d3b\u52a8\u65f6\u95f4(.*?))\u62b1\u6b49\uff0c\u60a8\u6307\u5b9a\u7684\u7528\u6237\u7a7a\u95f4\u4e0d\u5b58\u5728