一、准备工作与代码实例
(1)安装pil:下载后是一个exe,直接双击安装,它会自动安装到c:\python27\lib\site-packages中去,
(2)pytesser:下载解压后直接放c:\python27\lib\site-packages(根据你安装的python路径而不同),同时,新建一个pytheeer.pth,内容就写pytesser,注意这里的内容一定要和pytesser这个文件夹同名,意思就是pytesser文件夹,pytesser.pth,及内容都要一样!
(3)tesseract ocr engine下载:下载后解压,tessdata文件夹,用其替换掉pytesser解压后的tessdata文件夹即可。
二、验证
(1)原理:
验证码图像处理
验证码图像识别技术主要是操作图片内的像素点,通过对图片的像素点进行一系列的操作,最后输出验证码图像内的每个字符的文本矩阵。
1、读取图片
2、图片降噪
3、图片切割
4、图像文本输出
(2)验证字符识别
验证码内的字符识别主要以机器学习的分类算法来完成,目前我所利用的字符识别的算法为knn(k邻近算法)和svm (支持向量机算法),后面我 会对这两个算法的适用场景进行详细描述。
1、获取字符矩阵
2、矩阵进入分类算法
3、输出结果
要验证的图片如下:
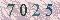
(3)、简单的命令:
from pytesser import *
image = image.open(‘1.jpg’) # open image object using pil
print image_to_string(image) # run tesseract.exe on image
然后运行:
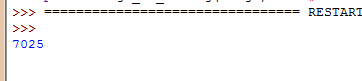
或者直接:
print image_file_to_string(‘fnord.tif’)
同样能输出结果!
(4)、复杂一点的
上面的只能对一些比较简单的做处理,一
原理:彩色转灰度,灰度转二值,二值图像识别
# 验证码识别,此程序只能识别数据验证码
import image
import imageenhance
import imagefilter
import sys
from pytesser import *
# 二值化
threshold = 140
table = []
for i in range(256):
if i < threshold:
table.append(0)
else:
table.append(1)
#由于都是数字
#对于识别成字母的 采用该表进行修正
rep={'o':'0',
'i':'1','l':'1',
'z':'2',
's':'8'
};
def getverify1(name):
#打开图片
im = image.open(name)
#转化到灰度图
imgry = im.convert('l')
#保存图像
imgry.save('g'+name)
#二值化,采用阈值分割法,threshold为分割点
out = imgry.point(table,'1')
out.save('b'+name)
#识别
text = image_to_string(out)
#识别对吗
text = text.strip()
text = text.upper();
for r in rep:
text = text.replace(r,rep[r])
#out.save(text+'.jpg')
print text
return text
getverify1('1.jpg') #注意这里的图片要和此文件在同一个目录,要不就传绝对路径也行
运行后效果:
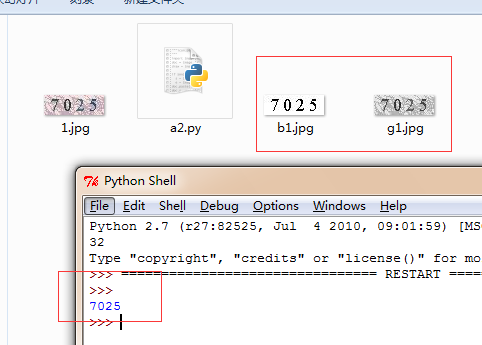
以上就是本文的全部内容,希望对大家的学习有所帮助。