一、tensorflow的常用函数:
import tensorflow as tf
import numpy as np
1.1、数据的呈现(Variable():定义变量):
x=np.array([[1,1,1],[1,-8,1],[1,1,1]])
w=tf.Variable(initial_value=x)
w=tf.Variable(tf.zeros([3,3]))
init=tf.global_variables_initializer()
withtf.Session() as sess:
sess.run(init)
print(sess.run(w))
1.2、数据的加减运算(add():加;multiply():乘):
a=tf.placeholder(tf.int16)
b=tf.placeholder(tf.int16)
add=tf.add(a,b)
mul=tf.multiply(a,b)
withtf.Session() as sess:
print(“a+b=”, sess.run(add,feed_dict={a:2, b:3}))
print(“a*b=”, sess.run(mul,feed_dict={a:2, b:3}))
1.3、矩阵相乘(matmul)运算:
a=tf.Variable(tf.ones([3,3]))
b=tf.Variable(tf.ones([3,3]))
product=tf.matmul(tf.multiply(5.0,a),tf.multiply(4.0,b))
init=tf.initialize_all_variables()
withtf.Session() as sess:
sess.run(init)
print(sess.run(product))
1.4、argmax的练习:获取最大值的下标向量
a=tf.get_variable(name=’a’,shape=[3,4],dtype=tf.float32,initializer=tf.random_uniform_initializer(minval=-1,maxval=1))
# 最大值所在的下标向量
b=tf.argmax(input=a,axis=0)
c=tf.argmax(input=a,dimension=1)
sess=tf.InteractiveSession()
sess.run(tf.initialize_all_variables())
print(sess.run(a))
print(sess.run(b))
print(sess.run(c))
1.5、创建全一/全零矩阵:
tf.ones(shape,type=tf.float32,name=None)
tf.ones([2, 3], int32) ==> [[1, 1, 1], [1, 1, 1]]
tf.zeros(shape,type=tf.float32,name=None)
tf.zeros([2, 3], int32) ==> [[0, 0, 0],[0, 0, 0]]
1.7、tf.ones_like(tensor,dype=None,name=None)
新建一个与给定的tensor类型大小一致的tensor,其所有元素为1。
# ‘tensor’ is [[1, 2, 3], [4, 5, 6]]
tf.ones_like(tensor) ==> [[1, 1, 1], [1, 1, 1]]
1.8、tf.zeros_like(tensor,dype=None,name=None)
新建一个与给定的tensor类型大小一致的tensor,其所有元素为0。
# ‘tensor’ is [[1, 2, 3], [4, 5, 6]]
tf.ones_like(tensor) ==> [[0, 0, 0],[0, 0, 0]]
1.9、tf.fill(dim,value,name=None)
创建一个形状大小为dim的tensor,其初始值为value
# Output tensor has shape [2, 3].
fill([2, 3], 9) ==> [[9, 9, 9]
[9, 9, 9]]
1.10、tf.constant(value,dtype=None,shape=None,name=’Const’)
创建一个常量tensor,先给出value,可以设定其shape
# Constant 1-D Tensor populated with value list.
tensor = tf.constant([1, 2, 3, 4, 5, 6, 7]) => [1 2 3 4 5 67]
# Constant 2-D tensor populated with scalarvalue -1.
tensor = tf.constant(-1.0, shape=[2, 3]) => [[-1. -1. -1.] [-1.-1. -1.]
1.11、tf.linspace(start,stop,num,name=None)
返回一个tensor,该tensor中的数值在start到stop区间之间取等差数列(包含start和stop),如果num>1则差值为(stop-start)/(num-1),以保证最后一个元素的值为stop。
其中,start和stop必须为tf.float32或tf.float64。num的类型为int。
tf.linspace(10.0, 12.0, 3, name=”linspace”) => [ 10.011.0 12.0]
1.12、tf.range(start,limit=None,delta=1,name=’range’)
返回一个tensor等差数列,该tensor中的数值在start到limit之间,不包括limit,delta是等差数列的差值。
start,limit和delta都是int32类型。
# ‘start’ is 3
# ‘limit’ is 18
# ‘delta’ is 3
tf.range(start, limit, delta) ==> [3, 6, 9, 12, 15]
# ‘limit’ is 5 start is 0
tf.range(start, limit) ==> [0, 1, 2, 3, 4]
1.13、tf.random_normal(shape,mean=0.0,stddev=1.0,dtype=tf.float32,seed=None,name=None)
返回一个tensor其中的元素的值服从正态分布。
seed: A Python integer. Used to create a random seed for thedistribution.See set_random_seed forbehavior。
1.14、tf.truncated_normal(shape, mean=0.0, stddev=1.0, dtype=tf.float32,seed=None, name=None)
返回一个tensor其中的元素服从截断正态分布(?概念不懂,留疑)
1.15、tf.random_uniform(shape,minval=0,maxval=None,dtype=tf.float32,seed=None,name=None)
返回一个形状为shape的tensor,其中的元素服从minval和maxval之间的均匀分布。
1.16、tf.random_shuffle(value,seed=None,name=None)
对value(是一个tensor)的第一维进行随机化。
[[1,2], [[2,3],
[2,3], ==> [1,2],
[3,4]] [3,4]]
1.17、tf.set_random_seed(seed)
设置产生随机数的种子。
二、常规神经网络(NN):
import tensorflow as tf
import tensorflow.examples.tutorials.mnist.input_data as input_data
mnist=input_data.read_data_sets(“Mnist_data/”, one_hot=True)
# val_data=mnist.validation.images
# val_label=mnist.validation.labels
#print(“______________________________”)
# print(mnist.train.images.shape)
# print(mnist.train.labels.shape)
# print(mnist.validation.images.shape)
# print(mnist.validation.labels.shape)
# print(mnist.test.images.shape)
# print(mnist.test.labels.shape)
# print(val_data)
# print(val_label)
# print(“==============================”)
x = tf.placeholder(tf.float32, [None,784])
y_actual = tf.placeholder(tf.float32, shape=[None,10])
W = tf.Variable(tf.zeros([784,10]))
b = tf.Variable(tf.zeros([10]))
y_predict = tf.nn.softmax(tf.matmul(x, W)+b)
cross_entropy=tf.reduce_mean(-tf.reduce_sum(y_actual*tf.log(y_predict),reduction_indices=1))
train_step=tf.train.GradientDescentOptimizer(0.01).minimize(cross_entropy)
correct_prediction=tf.equal(tf.argmax(y_predict,1),tf.argmax(y_actual, 1))
accuracy=tf.reduce_mean(tf.cast(correct_prediction,“float”))
init = tf.initialize_all_variables()
with tf.Session() assess:
sess.run(init)
fori in range(1000):
batch_xs, batch_ys = mnist.train.next_batch(100)
sess.run(train_step, feed_dict={x:batch_xs, y_actual:batch_ys})
if(i%100==0):
print(“accuracy:” ,sess.run(accuracy, feed_dict={x:mnist.test.images,y_actual:mnist.test.labels}))
三、线性网络模型:
import tensorflow as tf
import numpy as np
# 用numpy随机生成100个数:
x_data=np.float32(np.random.rand(2,100))
y_data=np.dot([0.100,0.200], x_data)+0.300
# 构造一个线性模型:
b=tf.Variable(tf.zeros([1]))
W=tf.Variable(tf.random_uniform([1,2],-1.0, 1.0))
y=tf.matmul(W, x_data)+b
# 最小化方差
loss=tf.reduce_mean(tf.square(y-y_data))
optimizer=tf.train.GradientDescentOptimizer(0.5)
train = optimizer.minimize(loss)
# 初始化变量
init=tf.initialize_all_variables()
# 启动图
sess=tf.Session()
sess.run(init)
# 拟合平面
for step inrange(0, 201):
sess.run(train)
ifstep % 20 == 0:
print(step,sess.run(W), sess.run(b))
四、CNN卷积神经网络:
# -*- coding: utf-8 -*-
“””
Created on ThuSep 8 15:29:48 2016
@author: root
“””
import tensorflow as tf
import tensorflow.examples.tutorials.mnist.input_data asinput_data
mnist = input_data.read_data_sets(“MNIST_data/”, one_hot=True)
x = tf.placeholder(tf.float32, [None,784])
y_actual = tf.placeholder(tf.float32, shape=[None,10])
# 定义实际x与y的值。
# placeholder中shape是参数的形状,默认为none,即一维数据,[2,3]表示为两行三列;[none,3]表示3列,行不定。
def weight_variable(shape):
initial = tf.truncated_normal(shape, stddev=0.1)
returntf.Variable(initial)
# 截尾正态分布,保留[mean-2*stddev, mean+2*stddev]范围内的随机数。用于初始化所有的权值,用做卷积核。
def bias_variable(shape):
initial = tf.constant(0.1,shape=shape)
returntf.Variable(initial)
# 创建常量0.1;用于初始化所有的偏置项,即b,用作偏置。
def conv2d(x,W):
returntf.nn.conv2d(x, W, strides=[1,1, 1,1], padding=‘SAME’)
# 定义一个函数,用于构建卷积层;
# x为input;w为卷积核;strides是卷积时图像每一维的步长;padding为不同的卷积方式;
def max_pool(x):
returntf.nn.max_pool(x, ksize=[1,2, 2,1], strides=[1,2, 2,1], padding=‘SAME’)
# 定义一个函数,用于构建池化层,池化层是为了获取特征比较明显的值,一般会取最大值max,有时也会取平均值mean。
# ksize=[1,2,2,1]:shape为[batch,height,width, channels]设为1个池化,池化矩阵的大小为2*2,有1个通道。
# strides是表示步长[1,2,2,1]:水平步长为2,垂直步长为2,strides[0]与strides[3]皆为1。
x_image = tf.reshape(x, [-1,28,28,1])
# 在reshape方法中-1维度表示为自动计算此维度,将x按照28*28进行图片转换,转换成一个大包下一个小包中28行28列的四维数组;
W_conv1 = weight_variable([5,5, 1,32])
# 构建一定形状的截尾正态分布,用做第一个卷积核;
b_conv1 = bias_variable([32])
# 构建一维的偏置量。
h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1)+ b_conv1)
# 将卷积后的结果进行relu函数运算,通过激活函数进行激活。
h_pool1 = max_pool(h_conv1)
# 将激活函数之后的结果进行池化,降低矩阵的维度。
W_conv2 = weight_variable([5,5, 32,64])
# 构建第二个卷积核;
b_conv2 = bias_variable([64])
# 第二个卷积核的偏置;
h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2)+ b_conv2)
# 第二次进行激活函数运算;
h_pool2 = max_pool(h_conv2)
# 第二次进行池化运算,输出一个2*2的矩阵,步长是2*2;
W_fc1 = weight_variable([7* 7 * 64,1024])
# 构建新的卷积核,用来进行全连接层运算,通过这个卷积核,将最后一个池化层的输出数据转化为一维的向量1*1024。
b_fc1 = bias_variable([1024])
# 构建1*1024的偏置;
h_pool2_flat = tf.reshape(h_pool2, [-1,7*7*64])
# 对 h_pool2第二个池化层结果进行变形。
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat,W_fc1) + b_fc1)
# 将矩阵相乘,并进行relu函数的激活。
keep_prob = tf.placeholder(“float”)
# 定义一个占位符。
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)
# 是防止过拟合的,使输入tensor中某些元素变为0,其他没变为零的元素变为原来的1/keep_prob大小,
# 形成防止过拟合之后的矩阵。
W_fc2 = weight_variable([1024,10])
b_fc2 = bias_variable([10])
y_predict=tf.nn.softmax(tf.matmul(h_fc1_drop,W_fc2) + b_fc2)
# 用softmax进行激励函数运算,得到预期结果;
# 在每次进行加和运算之后,需要用到激活函数进行转换,激活函数是用来做非线性变换的,因为sum出的线性函数自身在分类中存在有限性。
cross_entropy =-tf.reduce_sum(y_actual*tf.log(y_predict))
# 求交叉熵,用来检测运算结果的熵值大小。
train_step =tf.train.GradientDescentOptimizer(1e–3).minimize(cross_entropy)
# 通过训练获取到最小交叉熵的数据,训练权重参数。
correct_prediction =tf.equal(tf.argmax(y_predict,1),tf.argmax(y_actual,1))
accuracy =tf.reduce_mean(tf.cast(correct_prediction, “float”))
# 计算模型的精确度。
sess=tf.InteractiveSession()
sess.run(tf.initialize_all_variables())
for i inrange(20000):
batch = mnist.train.next_batch(50)
ifi%100 == 0:
train_acc = accuracy.eval(feed_dict={x:batch[0],y_actual: batch[1], keep_prob: 1.0})
# 用括号中的参数,带入accuracy中,进行精确度计算。
print(‘step’,i,‘training accuracy’,train_acc)
train_step.run(feed_dict={x: batch[0],y_actual: batch[1], keep_prob: 0.5})
# 训练参数,形成最优模型。
test_acc=accuracy.eval(feed_dict={x:mnist.test.images, y_actual: mnist.test.labels, keep_prob: 1.0})
print(“test accuracy”,test_acc)
Ø 解析:
1)卷积层运算:
# -*- coding: utf-8 -*-
importtensorflow as tf
# 构建一个两维的数组,命名为k。
k=tf.constant([[1,0,1],[2,1,0],[0,0,1]],dtype=tf.float32, name=‘k’)
# 构建一个两维的数组,命名为i。
i=tf.constant([[4,3,1,0],[2,1,0,1],[1,2,4,1],[3,1,0,2]],dtype=tf.float32, name=‘i’)
# 定义一个卷积核,将上面的k形状转化为[3,3,1,1]:长3宽3,1个通道,1个核。
kernel=tf.reshape(k,[3,3,1,1],name=‘kernel’)
# 定义一个原始图像,将上面的i形状转化为[1,4,4,1]:1张图片,长4宽4,1个通道。
image=tf.reshape(i, [1,4,4,1],name=‘image’)
# 用kernel对image做卷积,[1,1,1,1]:每个方向上的滑动步长,此时为四维,故四个方向上的滑动步长全部为1,
sss=tf.nn.conv2d(image, kernel, [1,1,1,1],“VALID”)
# 从数组的形状中删除单维条目,即把shape为1的维度去掉,一个降维的过程,得到一个二维的。
res=tf.squeeze(sss)
with tf.Session() assess:
print(sess.run(k))
print(sess.run(sss))
print(sess.run(res))
五、LSTM & GRU
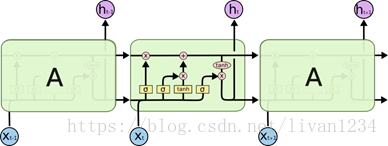
tensorflow提供了LSTM实现的一个basic版本,不包含lstm的一些高级扩展,同时也提供了一个标准接口,其中包含了lstm的扩展。分别为:tf.nn.rnn_cell.BasicLSTMCell(), tf.nn.rnn_cell.LSTMCell()
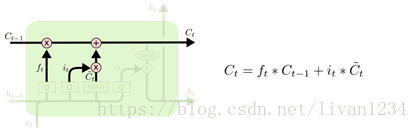
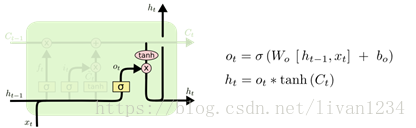
盗用一下Understanding LSTM Networks上的图
图一
图二
图三
tensorflow中的BasicLSTMCell()是完全按照这个结构进行设计的
#tf.nn.rnn_cell.BasicLSTMCell(num_units,forget_bias, input_size, state_is_tupe=Flase, activation=tanh)
cell =tf.nn.rnn_cell.BasicLSTMCell(num_units, forget_bias=1.0, input_size=None,state_is_tupe=Flase, activation=tanh)
#num_units:图一中ht的维数,如果num_units=10,那么ht就是10维行向量
#forget_bias:还不清楚这个是干嘛的
#input_size:[batch_size,max_time, size]。假设要输入一句话,这句话的长度是不固定的,max_time就代表最长的那句话是多长,size表示你打算用多长的向量代表一个word,即embedding_size(embedding_size和size的值不一定要一样)
#state_is_tuple:true的话,返回的状态是一个tuple:(c=array([[]]), h=array([[]]):其中c代表Ct的最后时间的输出,h代表Ht最后时间的输出,h是等于最后一个时间的output的
#图三向上指的ht称为output
#此函数返回一个lstm_cell,即图一中的一个A
如果你想要设计一个多层的LSTM网络,你就会用到tf.nn.rnn_cell.MultiRNNCell(cells, state_is_tuple=False),这里多层的意思上向上堆叠,而不是按时间展开
lstm_cell = tf.nn.rnn_cell.MultiRNNCells(cells,state_is_tuple=False)
#cells:一个cell列表,将列表中的cell一个个堆叠起来,如果使用cells=[cell]*4的话,就是四曾,每层cell输入输出结构相同
#如果state_is_tuple:则返回的是 n-tuple,其中n=len(cells): tuple:(c=[batch_size, num_units],h=[batch_size,num_units])
这是,网络已经搭好了,tensorflow提供了一个非常方便的方法来生成初始化网络的state
initial_state =lstm_cell.zero_state(batch_size, dtype=)
#返回[batch_size, 2*len(cells)],或者[batch_size, s]
#这个函数只是用来生成初始化值的
现在进行时间展开,有两种方法:
法一:
使用现成的接口:
tf.nn.dynamic_rnn(cell, inputs,sequence_length=None, initial_state=None,dtype=None,time_major=False)
#此函数会通过,inputs中的max_time将网络按时间展开
#cell:将上面的lstm_cell传入就可以
#inputs:[batch_size,max_time, size]如果time_major=Flase. [max_time,batch_size, size]如果time_major=True
#sequence_length:是一个list,如果你要输入三句话,且三句话的长度分别是5,10,25,那么sequence_length=[5,10,25]
#返回:(outputs, states):output,[batch_size, max_time, num_units]如果time_major=False。 [max_time,batch_size,num_units]如果time_major=True。states:[batch_size, 2*len(cells)]或[batch_size,s]
#outputs输出的是最上面一层的输出,states保存的是最后一个时间输出的states
法二
outputs = []
states = initial_states
with tf.variable_scope(“RNN”):
fortime_step in range(max_time):
if time_step>0:tf.get_variable_scope().reuse_variables()#LSTM同一曾参数共享,
(cell_out, state) = lstm_cell(inputs[:,time_step,:], state)
outputs.append(cell_out)
已经得到输出了,就可以计算loss了,根据你自己的训练目的确定loss函数
GRU结构图
来自Understanding LSTM Networks
图四
tenforflow提供了tf.nn.rnn_cell.GRUCell()构建一个GRU单元
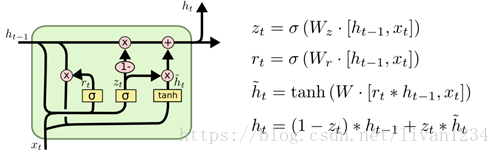
cell = tenforflow提供了tf.nn.rnn_cell.GRUCell(num_units, input_size=None, activation=tanh)
#参考lstm cell 使用
六、常用方法补充:
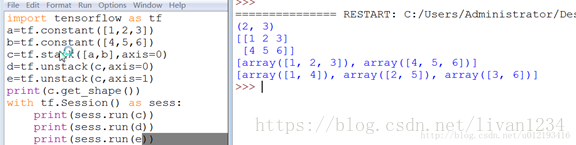
tf.unstack()
将给定的R维张量拆分成R-1维张量
将value根据axis分解成num个张量,返回的值是list类型,如果没有指定num则根据axis推断出!
DEMO:
| 1
2 3 4 5 6 7 8 9 10 11 12 13 |
import tensorflow as tf
a = tf.constant([3,2,4,5,6]) b = tf.constant([1,6,7,8,0]) c = tf.stack([a,b],axis=0) d = tf.stack([a,b],axis=1) e = tf.unstack([a,b],axis=0) f = tf.unstack([a,b],axis=1)
with tf.Session() as sess: print(sess.run(c)) print(sess.run(d)) print(sess.run(e)) print(sess.run(f)) |
输出:
[[3 2 4 5 6]
[1 6 7 8 0]]
——————–
[[3 1]
[2 6]
[4 7]
[5 8]
[6 0]]
———————-
[array([3, 2, 4, 5, 6]), array([1, 6, 7, 8, 0])]
———————-
[array([3, 1]), array([2, 6]), array([4, 7]), array([5, 8]), array([6, 0])]
七、tf.nn.softmax_cross_entropy_with_logits的用法:
在计算loss的时候,最常见的一句话就是tf.nn.softmax_cross_entropy_with_logits,那么它到底是怎么做的呢?
首先明确一点,loss是代价值,也就是我们要最小化的值.
tf.nn.softmax_cross_entropy_with_logits(logits,labels, name=None)
除去name参数用以指定该操作的name,与方法有关的一共两个参数:
第一个参数logits:就是神经网络最后一层的输出,如果有batch的话,它的大小就是[batchsize,num_classes],单样本的话,大小就是num_classes
第二个参数labels:实际的标签,大小同上
具体的执行流程大概分为两步:
第一步是先对网络最后一层的输出做一个softmax,这一步通常是求取输出属于某一类的概率,对于单样本而言,输出就是一个num_classes大小的向量([Y1,Y2,Y3…]其中Y1,Y2,Y3…分别代表了是属于该类的概率)
至于为什么是用的这个公式?这里不介绍了,涉及到比较多的理论证明
第二步是softmax的输出向量[Y1,Y2,Y3…]和样本的实际标签做一个交叉熵,公式如下:
其中,指代实际的标签中第i个的值(用mnist数据举例,如果是3,那么标签是[0,0,0,1,0,0,0,0,0,0],除了第4个值为1,其他全为0)
就是softmax的输出向量[Y1,Y2,Y3…]中,第i个元素的值
显而易见,预测越准确,结果的值越小(别忘了前面还有负号),最后求一个平均,得到我们想要的loss
注意!!!这个函数的返回值并不是一个数,而是一个向量,如果要求交叉熵,我们要再做一步tf.reduce_sum操作,就是对向量里面所有元素求和,最后才得到 ,如果求loss,则要做一步tf.reduce_mean操作,对向量求均值!
最后上代码:
import tensorflow as tf
#our NN’s output
logits=tf.constant([[1.0,2.0,3.0],[1.0,2.0,3.0],[1.0,2.0,3.0]])
#step1:do softmax
y=tf.nn.softmax(logits)
#true label
y_=tf.constant([[0.0,0.0,1.0],[0.0,0.0,1.0],[0.0,0.0,1.0]])
#step2:do cross_entropy
cross_entropy =-tf.reduce_sum(y_*tf.log(y))
#do cross_entropy just one step
cross_entropy2=tf.reduce_sum(tf.nn.softmax_cross_entropy_with_logits(logits,y_))#dont forget tf.reduce_sum()!!
with tf.Session() as sess:
softmax=sess.run(y)
c_e = sess.run(cross_entropy)
c_e2 = sess.run(cross_entropy2)
print(“step1:softmax result=”)
print(softmax)
print(“step2:cross_entropy result=”)
print(c_e)
print(“Function(softmax_cross_entropy_with_logits)result=”)
print(c_e2)
输出结果是:
step1:softmax result=
[[ 0.09003057 0.24472848 0.66524094]
[0.09003057 0.24472848 0.66524094]
[0.09003057 0.24472848 0.66524094]]
step2:cross_entropy result=
1.22282
Function(softmax_cross_entropy_with_logits)result=
1.2228
最后大家可以试试e^1/(e^1+e^2+e^3)是不是0.09003057,发现确实一样!!这也证明了我们的输出是符合公式逻辑的
八、RNN应用:
Ø RNN案例(一)
# -*- coding: utf-8 -*-
import tensorflow as tf
importtensorflow.examples.tutorials.mnist.input_data as input_data
mnist =input_data.read_data_sets(“MNIST_data/”, one_hot=True)
lr = 0.001
training_iters = 100000
batch_size = 128
n_inputs = 28
n_steps = 28
n_hidden_units = 128
n_classes = 10
# 生成两个占位符;
x = tf.placeholder(tf.float32, [None,n_steps, n_inputs])
y = tf.placeholder(tf.float32, [None,n_classes])
weights = {
# 随机生成一个符合正态图形的矩阵,作为in和out的初始值。
‘in’:tf.Variable(tf.random_normal([n_inputs, n_hidden_units])),
‘out’:tf.Variable(tf.random_normal(n_hidden_units, n_classes)),
}
biases = {
‘in’:tf.Variable(tf.constant(0.1, shape=[n_hidden_units, ])),
‘out’:tf.Variable(tf.constant(0.1, shape=[n_classes, ])),
}
def RNN(X, weights, biases):
# 第一步:输入的x为三维数据,因此需要进行相应的维度变换;转换成2维,然后与w、b进行交易,运算完成后,再将x转换成三维;
X=tf.reshape(X, [-1, n_inputs])
X_in = tf.matmul(X, weights[‘in’])+biases[‘in’]
X_in = tf.reshape(X_in, [-1, n_steps, n_hidden_units])
# 第二步:即构建cell的初始值,并进行建模运算;
#n_hidden_units:是ht的维数,表示128维行向量;state_is_tuple表示tuple形式,返回一个lstm的单元,即一个ht。
lstm_cell = tf.contrib.rnn.BasicLSTMCell(n_hidden_units,forget_bias=1.0, state_is_tuple=True)
# 将LSTM的状态初始化全为0数组,batch_size给出一个batch大小。
init_state = lstm_cell.zero_state(batch_size, dtype=tf.float32)
# 运算一个神经单元的输出值与状态,动态构建RNN模型,在这个模型中实现ht与x的结合。
outputs, final_state = tf.nn.dynamic_rnn(lstm_cell, X_in,initial_state=init_state, time_major=False)
# 第三步:将输出值进行格式转换,然后运算输出,即可。
# 矩阵的转置,[0,1,2]为正常顺序[高,长,列],想要更换哪个就更换哪个的顺序即可,并实现矩阵解析。
outputs = tf.unstack(tf.transpose(outputs, [1,0,2]))
results = tf.matmul(outputs[-1], weights[‘out’]) + biases[‘out’]
return results
# 创建一个模型,然后进行测试。
pred = RNN(x, weights, biases)
# softmax_cross_entropy_with_logits:将神经网络最后一层的输出值pred与实际标签y作比较,然后计算全局平均值,即为损失。
cost =tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(pred, y))
# 用梯度下降优化,下降速率为0.001。
train_op =tf.train.AdamOptimizer(lr).minimize(cost)
# 计算准确度。
correct_pred = tf.equal(tf.argmax(pred, 1),tf.argmax(y, 1))
accuracy =tf.reduce_mean(tf.cast(correct_pred, tf.float32))
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
step = 0
while step*batch_size < training_iters:
batch_xs, batch_ys = mnist.train.next_batch(batch_size)
batch_xs = batch_xs.reshape([batch_size, n_steps, n_inputs])
sess.run([train_op], feed_dict={
x:batch_xs,
y:batch_ys,
})
if step % 20 ==0:
print(sess.run(accuracy, feed_dict={
x:batch_xs,
y:batch_ys,
}))
step += 1
Ø RNN案例(二)
# num_epochs = 100
# total_series_length = 50000
# truncated_backprop_length = 15
# state_size = 4
# num_classes = 2
# echo_step = 3
# batch_size = 5
# num_batches =total_series_length//batch_size//truncated_backprop_length
#
# def generateData():
# x= np.array(np.random.choice(2, total_series_length, p=[0.5, 0.5]))
# y= np.roll(x, echo_step)
# y[0:echo_step] = 0
#
# x= x.reshape((batch_size, -1)) # Thefirst index changing slowest, subseries as rows
# y= y.reshape((batch_size, -1))
#
# return (x, y)
#
# batchX_placeholder =tf.placeholder(tf.float32, [batch_size, truncated_backprop_length])
# batchY_placeholder =tf.placeholder(tf.int32, [batch_size, truncated_backprop_length])
#
# init_state = tf.placeholder(tf.float32,[batch_size, state_size])
#
# W =tf.Variable(np.random.rand(state_size+1, state_size), dtype=tf.float32)
# b = tf.Variable(np.zeros((1,state_size)),dtype=tf.float32)
#
# W2 = tf.Variable(np.random.rand(state_size,num_classes),dtype=tf.float32)
# b2 = tf.Variable(np.zeros((1,num_classes)),dtype=tf.float32)
#
# # Unpack columns
# inputs_series =tf.unstack(batchX_placeholder, axis=1)
# labels_series =tf.unstack(batchY_placeholder, axis=1)
#
# # Forward pass
# current_state = init_state
# states_series = []
# for current_input in inputs_series:
# current_input = tf.reshape(current_input, [batch_size, 1])
# input_and_state_concatenated = tf.concat(1, [current_input,current_state]) # Increasing number ofcolumns
#
# next_state = tf.tanh(tf.matmul(input_and_state_concatenated, W) +b) # Broadcasted addition
# states_series.append(next_state)
# current_state = next_state
#
# logits_series = [tf.matmul(state, W2) + b2for state in states_series] #Broadcasted addition
# predictions_series = [tf.nn.softmax(logits)for logits in logits_series]
#
# losses =[tf.nn.sparse_softmax_cross_entropy_with_logits(logits, labels) for logits,labels in zip(logits_series,labels_series)]
# total_loss = tf.reduce_mean(losses)
#
# train_step =tf.train.AdagradOptimizer(0.3).minimize(total_loss)
# def plot(loss_list, predictions_series,batchX, batchY):
# plt.subplot(2, 3, 1)
# plt.cla()
# plt.plot(loss_list)
#
# for batch_series_idx in range(5):
# one_hot_output_series = np.array(predictions_series)[:, batch_series_idx,:]
# single_output_series = np.array([(1 if out[0] < 0.5 else 0) for outin one_hot_output_series])
#
# plt.subplot(2, 3, batch_series_idx + 2)
# plt.cla()
# plt.axis([0, truncated_backprop_length, 0, 2])
# left_offset = range(truncated_backprop_length)
# plt.bar(left_offset, batchX[batch_series_idx, :], width=1,color=”blue”)
# plt.bar(left_offset, batchY[batch_series_idx, :] * 0.5, width=1,color=”red”)
# plt.bar(left_offset, single_output_series * 0.3, width=1,color=”green”)
#
# plt.draw()
# plt.pause(0.0001)
#
# with tf.Session() as sess:
# sess.run(tf.initialize_all_variables())
# plt.ion()
# plt.figure()
# plt.show()
# loss_list = []
#
# for epoch_idx in range(num_epochs):
# x,y = generateData()
# _current_state = np.zeros((batch_size, state_size))
# print(“New data, epoch”, epoch_idx)
#
# for batch_idx in range(num_batches):
# start_idx = batch_idx * truncated_backprop_length
# end_idx = start_idx + truncated_backprop_length
#
# batchX = x[:,start_idx:end_idx]
# batchY = y[:,start_idx:end_idx]
#
# _total_loss, _train_step, _current_state, _predictions_series =sess.run(
# [total_loss, train_step, current_state, predictions_series],
# feed_dict={
# batchX_placeholder:batchX,
# batchY_placeholder:batchY,
# init_state:_current_state
# })
# loss_list.append(_total_loss)
# if batch_idx%100 == 0:
# print(“Step”,batch_idx, “Loss”, _total_loss)
# plot(loss_list, _predictions_series, batchX, batchY)
# plt.ioff()
# plt.show()
Ø LSTM_RNN案例(三):
# -*-coding: utf-8 -*-
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
from asn1crypto._ffi import null
BATCH_START=0 #建立batch data的时候的index
TIME_STEPS=20 #backpropagation throughtime的time_steps
BATCH_SIZE=50 #
INPUT_SIZE=1 #sin数据输入size
OUTPUT_SIZE=1 #cos数据输入size
CELL_SIZE=10 #RNN的hiden unit size
LR=0.006 #学习率
# 定义一个生成数据的get_batch的function:
def get_batch():
global BATCH_START, TIME_STEPS
xs=np.arange(BATCH_START,BATCH_START+TIME_STEPS*BATCH_SIZE)
.reshape((BATCH_SIZE,TIME_STEPS))/(10*np.pi)
seq=np.sin(xs)
res=np.cos(xs)
BATCH_START+=TIME_STEPS
# np.newaxis:在功能上等价于none;
return [seq[:,:,np.newaxis],res[:,:,np.newaxis],xs]
class LSTMRNN(object):
def __init__(self, n_steps, input_size, output_size, cell_size,batch_size):
self.n_steps=n_steps
self.input_size=input_size
self.output_size=output_size
self.cell_size=cell_size
self.batch_size=batch_size
# 构建命名空间,在inputs命名空间下的xs和ys与其他空间下的xs和ys是不冲突的,一般与variable一起用。
with tf.name_scope(‘inputs’):
self.xs=tf.placeholder(tf.float32,[None, n_steps, input_size], name=‘xs‘)
self.ys=tf.placeholder(tf.float32,[None, n_steps, output_size], name=‘ys‘)
# variable_scope与get_variable()一起用,实现变量共享,指向同一个内存空间。
with tf.variable_scope(‘in_hidden’):
self.add_input_layer()
with tf.variable_scope(‘LSTM_cell’):
self.add_cell()
with tf.variable_scope(‘out_hidden’):
self.add_output_layer()
with tf.name_scope(‘cost’):
self.compute_cost()
with tf.name_scope(‘train’):
self.train_op=tf.train.AdamOptimizer(LR).minimize(self.cost)
def add_input_layer(self,):
l_in_x = tf.reshape(self.xs, [-1, self.input_size], name=‘2_2D’)
Ws_in=self._weight_variable([self.input_size, self.cell_size])
bs_in=self._bias_variable([self.cell_size,])
with tf.name_scope(‘Wx_plus_b’):
l_in_y=tf.matmul(l_in_x,Ws_in)+bs_in
self.l_in_y=tf.reshape(l_in_y,[-1, self.n_steps, self.cell_size],name=‘2_3D’)
def add_cell(self):
lstm_cell=tf.contrib.rnn.BasicLSTMCell(self.cell_size,forget_bias=1.0, state_is_tuple=True)
with tf.name_scope(‘initial_state’):
self.cell_init_state=lstm_cell.zero_state(self.batch_size,dtype=tf.float32)
self.cell_outputs,self.cell_final_state=tf.nn.dynamic_rnn(lstm_cell, self.l_in_y,initial_state=self.cell_init_state, time_major=False)
def add_output_layer(self):
l_out_x=tf.reshape(self.cell_outputs,[-1, self.cell_size], name=‘2_2D’)
Ws_out=self._weight_variable([self.cell_size,self.output_size])
bs_out=self._bias_variable([self.output_size,])
with tf.name_scope(‘Wx_plus_b’):
self.pred=tf.matmul(l_out_x,Ws_out)+bs_out
# 求交叉熵
def compute_cost(self):
losses=tf.contrib.legacy_seq2seq.sequence_loss_by_example(
[tf.reshape(self.pred, [-1], name=‘reshape_pred’)],
[tf.reshape(self.ys, [-1], name=‘reshape_target’)],
[tf.ones([self.batch_size*self.n_steps],dtype=tf.float32)],
average_across_timesteps=True,
softmax_loss_function=self.ms_error,
name=‘losses’
)
with tf.name_scope(‘average_cost’):
self.cost=tf.div(
tf.reduce_sum(losses, name=‘losses_sum’),
self.batch_size,
name=‘average_cost’,
)
tf.summary.scalar(‘cost’,self.cost)
def ms_error(self,labels,logits):
#求方差
return tf.square(tf.subtract(labels,logits))
def _weight_variable(self, shape, name=‘weights’):
initializer=tf.random_normal_initializer(mean=0, stddev=1.,)
return tf.get_variable(shape=shape,initializer=initializer, name=name)
def _bias_variable(self, shape, name=‘biases’):
initializer=tf.constant_initializer(0, 1)
return tf.get_variable(name=name, shape=shape,initializer=initializer)
if __name__==‘__main__’:
model=LSTMRNN(TIME_STEPS, INPUT_SIZE,OUTPUT_SIZE, CELL_SIZE, BATCH_SIZE)
sess=tf.Session()
sess.run(tf.global_variables_initializer())
state=null
for i in range(200):
seq, res, xs=get_batch()
if i == 0:
feed_dict={
model.xs:seq,
model.ys:res,
}
else:
feed_dict={
model.xs:seq,
model.ys:res,
model.cell_init_state:state
}
_, cost, state, pred=sess.run(
[model.train_op, model.cost,model.cell_final_state, model.pred],
feed_dict=feed_dict)
if i%20==0:
print(‘cost:’,round(cost, 4))
九、使用flags定义命令行参数
import tensorflow as tf
第一个是参数名称,第二个参数是默认值,第三个是参数描述
tf.app.flags.DEFINE_string(‘str_name’, ‘def_v_1’,“descrip1”)
tf.app.flags.DEFINE_integer(‘int_name’, 10,“descript2”)
tf.app.flags.DEFINE_boolean(‘bool_name’, False, “descript3”)
FLAGS = tf.app.flags.FLAGS
#必须带参数,否则:‘TypeError: main() takes no arguments (1given)’; main的参数名随意定义,无要求
defmain(_):
# 在这个函数中添加脚本所需要处理的内容。
print(FLAGS.str_name)
print(FLAGS.int_name)
print(FLAGS.bool_name)
if __name__ == ‘__main__’:
tf.app.run() #执行main函数
注:
FLAGS命令是指编写一个脚本文件,在执行这个脚本时添加相应的参数;
如(上面文件叫tt.py):
python tt.py –str_name test_str–int_name 99 –bool_name True
十、tensor变换:
#对于2-D
# Tensor变换主要是对矩阵进行相应的运算工作,包涵的方法主要有:reduce_……(a, axis)系列;如果不加axis的话都是针对整个矩阵进行运算。
tf.reduce_sum(a, 1)#对axis1
tf.reduce_mean(a,0) #每列均值
第二个参数是axis,如果为0的话,res[i]=∑ja[j,i]res[i]=∑ja[j,i]即(res[i]=∑a[:,i]res[i]=∑a[:,i]), 如果是1的话,res[i]=∑ja[i,j]res[i]=∑ja[i,j]
NOTE:返回的都是行向量,(axis等于几,就是对那维操作,i.e.:沿着那维操作, 其它维度保留)
#关于concat,可以用来进行降维 3D->2D , 2D->1D
tf.concat(concat_dim, data)
#arr = np.zeros([2,3,4,5,6])
In [6]: arr2.shape
Out[6]: (2, 3, 4, 5)
In [7]: np.concatenate(arr2, 0).shape
Out[7]: (6, 4, 5) 🙁2*3, 4, 5)
In [9]: np.concatenate(arr2, 1).shape
Out[9]: (3, 8, 5) 🙁3, 2*4, 5)
#tf.concat()
t1 = [[1, 2, 3], [4, 5, 6]]
t2 = [[7, 8, 9], [10, 11, 12]]
# 将t1, t2进行concat,axis为0,等价于将shape=[2,2, 3]的Tensor concat成
#shape=[4, 3]的tensor。在新生成的Tensor中tensor[:2,:]代表之前的t1
#tensor[2:,:]是之前的t2
tf.concat(0, [t1, t2]) ==> [[1, 2, 3], [4, 5, 6], [7, 8, 9], [10, 11, 12]]
# 将t1, t2进行concat,axis为1,等价于将shape=[2,2, 3]的Tensor concat成
#shape=[2, 6]的tensor。在新生成的Tensor中tensor[:,:3]代表之前的t1
#tensor[:,3:]是之前的t2
tf.concat(1, [t1, t2]) ==> [[1, 2, 3, 7, 8, 9], [4, 5, 6, 10, 11, 12]]
concat是将list中的向量给连接起来,axis表示将那维的数据连接起来,而其他维的结构保持不变
#squeeze 降维维度为1的降掉
tf.squeeze(arr, [])
降维,将维度为1的降掉
arr = tf.Variable(tf.truncated_normal([3,4,1,6,1], stddev=0.1))
arr2 = tf.squeeze(arr, [2,4])
arr3 = tf.squeeze(arr) #降掉所以是1的维
# split(dimension, num_split, input):dimension的意思就是输入张量的哪一个维度,如果是0就表示对第0维度进行切割。num_split就是切割的数量,如果是2就表示输入张量被切成2份,每一份是一个列表。
tf.split(split_dim, num_split, value, name=‘split’)
# ‘value’ is a tensor with shape [5, 30]
# Split ‘value’ into 3 tensors along dimension 1
split0, split1, split2 = tf.split(1, 3, value)
tf.shape(split0) ==> [5, 10]
#embedding: embedding_lookup是按照向量获取矩阵中的值,[0,2,3,1]是取第0,2,3,1个向量。
mat = np.array([1,2,3,4,5,6,7,8,9]).reshape((3,-1))
ids = [[1,2], [0,1]]
res = tf.nn.embedding_lookup(mat, ids)
res.eval()
array([[[4, 5, 6],
[7, 8, 9]],
[[1, 2, 3],
[4, 5, 6]]])
# expand_dims:扩展维度,如果想用广播特性的话,经常会用到这个函数
# ‘t’ is a tensor of shape [2]
#一次扩展一维
shape(tf.expand_dims(t, 0)) ==> [1, 2]
shape(tf.expand_dims(t, 1)) ==> [2, 1]
shape(tf.expand_dims(t, –1)) ==> [2, 1]
# ‘t2’ is a tensor of shape [2, 3, 5]
shape(tf.expand_dims(t2, 0)) ==> [1, 2, 3, 5]
shape(tf.expand_dims(t2, 2)) ==> [2, 3, 1, 5]
shape(tf.expand_dims(t2, 3)) ==> [2, 3, 5, 1]
tf.slice(input_, begin, size, name=None)
这个函数的作用是从输入数据input中提取出一块切片
o 切片的尺寸是size,切片的开始位置是begin。
o 切片的尺寸size表示输出tensor的数据维度,其中size[i]表示在第i维度上面的元素个数。
o 开始位置begin表示切片相对于输入数据input_的每一个偏移量
import tensorflow as tf
import numpy as np
sess = tf.Session()
input=tf.constant([[[1, 1, 1], [2, 2, 2]], [[3, 3, 3], [4, 4, 4]], [[5, 5, 5], [6, 6, 6]]])
data = tf.slice(input, [1, 0, 0], [1, 1, 3])
print(sess.run(data))
“””[1,0,0]表示第一维偏移了1 则是从[[[3, 3, 3],[4, 4, 4]],[[5, 5, 5], [6, 6, 6]]]中选取数据然后选取第一维的第一个,第二维的第一个数据,第三维的三个数据“””
# [[[3 3 3]]]
#array([[ 6, 7],
# [11, 12]])
理解tf.slice()最好是从返回值上去理解,现在假设input的shape是[a1, a2, a3], begin的值是[b1, b2, b3],size的值是[s1, s2, s3],那么tf.slice()返回的值就是 input[b1:b1+s1,b2:b2+s2, b3:b3+s3]。
如果 si=−1si=−1 ,那么 返回值就是 input[b1:b1+s1,…,bi: ,…]
注意:input[1:2] 取不到input[2]
tf.stack()
tf.stack(values, axis=0, name=’stack’)
tf.stack()这是一个矩阵拼接的函数,tf.unstack()则是一个矩阵分解的函数
将 a list of R 维的Tensor堆成 R+1维的Tensor。
Given a list of length N of tensors of shape (A, B, C);
if axis == 0 then the output tensor will have the shape (N, A, B, C)
这时 res[i,:,:,:] 就是原 list中的第 i 个 tensor
if axis == 1 thenthe output tensor will have the shape (A, N, B, C).
这时 res[:,i,:,:] 就是原list中的第 i 个 tensor
Etc.
# ‘x’ is [1, 4]
# ‘y’ is [2, 5]
# ‘z’ is [3, 6]
stack([x, y, z]) => [[1, 4], [2, 5], [3, 6]] # Pack along first dim.
stack([x, y, z], axis=1) => [[1, 2, 3], [4, 5, 6]]
tf.gather():按照指定的下标集合从axis=0中抽取子集
tf.gather(params, indices, validate_indices=None,name=None)
· tf.slice(input_,begin, size, name=None):按照指定的下标范围抽取连续区域的子集
· tf.gather(params,indices, validate_indices=None, name=None):按照指定的下标集合从axis=0中抽取子集,适合抽取不连续区域的子集
input = [[[1, 1, 1], [2, 2, 2]], [[3, 3, 3], [4, 4, 4]], [[5, 5, 5], [6, 6, 6]]]tf.slice(input, [1, 0, 0], [1, 1, 3]) ==> [[[3, 3, 3]]]tf.slice(input, [1, 0, 0], [1, 2, 3]) ==> [[[3, 3, 3], [4, 4, 4]]]tf.slice(input, [1, 0, 0], [2, 1, 3]) ==> [[[3, 3, 3]], [[5, 5, 5]]]tf.gather(input, [0, 2]) ==> [[[1, 1, 1], [2, 2, 2]], [[5, 5, 5], [6, 6, 6]]]indices must be an integer tensor of any dimension(usually 0-D or 1-D).
Produces an output tensor with shape indices.shape +params.shape[1:]
# Scalar indices, 会降维
output[:, …, :] = params[indices, :, … :]
# Vector indices
output[i, :, …, :] = params[indices[i], :, … :]
# Higher rank indices,会升维
output[i, …, j, :, … :] = params[indices[i, …, j],:, …, :]
tf.pad
tf.pad(tensor, paddings, mode=“CONSTANT”, name=None)
· tensor: 任意shape的tensor,维度 Dn
· paddings: [Dn, 2] 的 Tensor, Padding后tensor的某维上的长度变为padding[D,0]+tensor.dim_size(D)+padding[D,1]
· mode: CONSTANT表示填0, REFLECT表示反射填充,SYMMETRIC表示对称填充。
· 函数原型:
tf.pad
pad(tensor, paddings, mode=’CONSTANT’, name=None)
(输入数据,填充的模式,填充的内容,名称)
· 这里紧紧解释paddings的含义:
它是一个Nx2的列表,
在输入维度n上,则paddings[n,0] 表示该维度内容前面加0的个数, 如对矩阵来说,就是行的最上面或列最左边加几排0
paddings[n, 1] 表示该维度内容后加0的个数。
· 举个例子:
输入 tensor 形如
[[ 1, 2],
[1, 2]]
而paddings = [[1, 1], [1, 1]] ([[上,下],[左,右]])
Tensor=[[1,2],[1,2]]
Paddings=[[1,1],[1,1]]
Init=tf.global_variables_initializer()
Withtf.Session() as sess:
Sess.run(init)
Print(sess.run(tf.pad(tensor,paddings, mode=’CONSTANT’)))
则结果为:
[[0, 0, 0, 0],
[0, 1, 2, 0],
[0, 1, 2, 0],
[0, 0, 0, 0]]
十一、损失函数:
损失函数的运算规则:

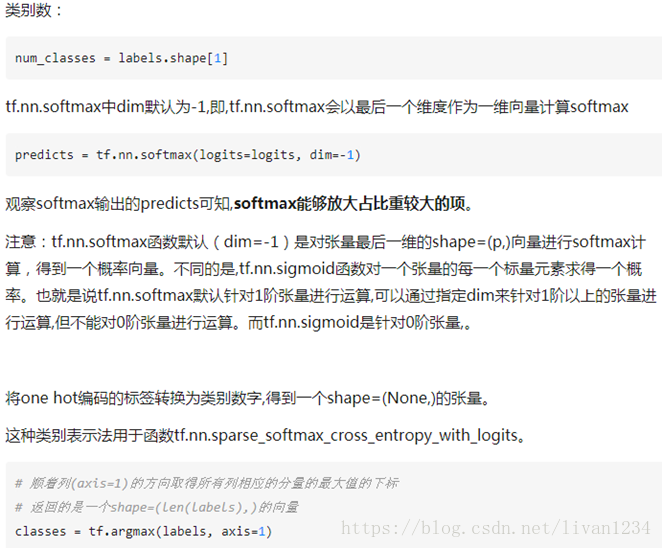
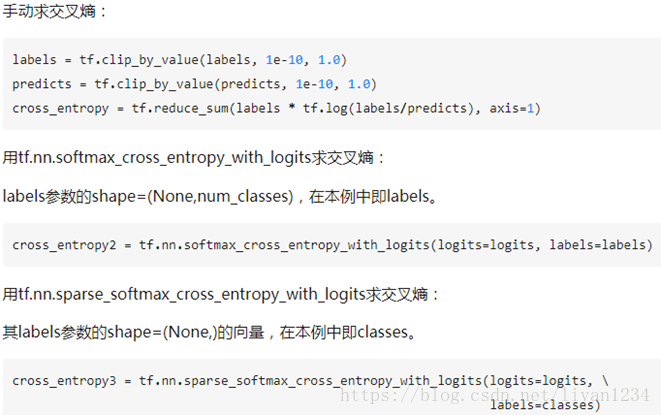



tf.nn.softmax_cross_entropy_with_logits(logits, labels, name=None)除去name参数用以指定该操作的name,与方法有关的一共两个参数:第一个参数logits:就是神经网络最后一层的输出,如果有batch的话,它的大小就是[batchsize,num_classes],单样本的话,大小就是num_classes第二个参数labels:实际的标签,大小同上具体的执行流程大概分为两步:第一步是先对网络最后一层的输出做一个softmax,这一步通常是求取输出属于某一类的概率,对于单样本而言,输出就是一个num_classes大小的向量([Y1,Y2,Y3...]其中Y1,Y2,Y3...分别代表了是属于该类的概率)。第二步是softmax的输出向量[Y1,Y2,Y3...]和样本的实际标签做一个交叉熵。第三步是求一个平均,得到我们想要的loss最后上代码:import tensorflow as tf #our NN's output logits=tf.constant([[1.0,2.0,3.0],[1.0,2.0,3.0],[1.0,2.0,3.0]]) #step1:do softmax y=tf.nn.softmax(logits) #true label y_=tf.constant([[0.0,0.0,1.0],[0.0,0.0,1.0],[0.0,0.0,1.0]]) #step2:do cross_entropy cross_entropy = -tf.reduce_sum(y_*tf.log(y)) #do cross_entropy just one step cross_entropy2=tf.reduce_sum(tf.nn.softmax_cross_entropy_with_logits(logits, y_))#dont forget tf.reduce_sum()!! with tf.Session() as sess: softmax=sess.run(y) c_e = sess.run(cross_entropy) c_e2 = sess.run(cross_entropy2) print("step1:softmax result=") print(softmax) print("step2:cross_entropy result=") print(c_e) print("Function(softmax_cross_entropy_with_logits) result=") print(c_e2) 输出结果是:step1:softmax result= [[ 0.09003057 0.24472848 0.66524094] [ 0.09003057 0.24472848 0.66524094] [ 0.09003057 0.24472848 0.66524094]] step2:cross_entropy result= 1.22282 Function(softmax_cross_entropy_with_logits) result= 1.2228 交叉熵可在神经网络(机器学习)中作为损失函数,p表示真实标记的分布,q则为训练后的模型的预测标记分布,交叉熵损失函数可以衡量p与q的相似性。交叉熵作为损失函数还有一个好处是使用sigmoid函数在梯度下降时能避免均方误差损失函数学习速率降低的问题,因为学习速率可以被输出的误差所控制。tensorflow中自带的函数可以轻松的实现交叉熵的计算。tf.nn.softmax_cross_entropy_with_logits(_sentinel=None, labels=None, logits=None, dim=-1, name=None)Computes softmax cross entropy between logits and labels.注意:如果labels的每一行是one-hot表示,也就是只有一个地方为1,其他地方为0,可以使用tf.sparse_softmax_cross_entropy_with_logits()警告:1. 这个操作的输入logits是未经缩放的,该操作内部会对logits使用softmax操作2. 参数labels,logits必须有相同的形状 [batch_size, num_classes] 和相同的类型(float16, float32, float64)中的一种参数:_sentinel: 一般不使用labels: labels的每一行labels[i]必须为一个概率分布logits: 未缩放的对数概率dims: 类的维度,默认-1,也就是最后一维name: 该操作的名称返回值:长度为batch_size的一维Tensor下面用个小例子来看看该函数的用法import tensorflow as tflabels = [[0.2,0.3,0.5], [0.1,0.6,0.3]]logits = [[2,0.5,1], [0.1,1,3]]logits_scaled = tf.nn.softmax(logits)result1 = tf.nn.softmax_cross_entropy_with_logits(labels=labels, logits=logits)result2 = -tf.reduce_sum(labels*tf.log(logits_scaled),1)result3 = tf.nn.softmax_cross_entropy_with_logits(labels=labels, logits=logits_scaled)with tf.Session() as sess: print sess.run(result1) print sess.run(result2) print sess.run(result3)>>>[ 1.41436887 1.66425455]>>>[ 1.41436887 1.66425455]>>>[ 1.17185783 1.17571414]上述例子中,labels的每一行是一个概率分布,而logits未经缩放(每行加起来不为1),我们用定义法计算得到交叉熵result2,和套用tf.nn.softmax_cross_entropy_with_logits()得到相同的结果, 但是将缩放后的logits_scaled输tf.nn.softmax_cross_entropy_with_logits(), 却得到错误的结果,所以一定要注意,这个操作的输入logits是未经缩放的下面来看tf.nn.sparse_softmax_cross_entropy_with_logits(_sentinel=None, labels=None, logits=None, name=None)这个函数与上一个函数十分类似,唯一的区别在于labels.注意:对于此操作,给定标签的概率被认为是排他的。labels的每一行为真实类别的索引警告:1. 这个操作的输入logits同样是是未经缩放的,该操作内部会对logits使用softmax操作2. 参数logits的形状 [batch_size, num_classes] 和labels的形状[batch_size]返回值:长度为batch_size的一维Tensor, 和label的形状相同,和logits的类型相同import tensorflow as tflabels = [0,2]logits = [[2,0.5,1], [0.1,1,3]]logits_scaled = tf.nn.softmax(logits)result1 = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=labels, logits=logits)with tf.Session() as sess: print sess.run(result1)>>>[ 0.46436879 0.17425454]tf.nn.sparse_softmax_cross_entropy_with_logits(logits,labels, name=None)
def sparse_softmax_cross_entropy_with_logits(logits, labels, name=None):#logits是最后一层的z(输入)#A common use case is to have logits of shape `[batch_size, num_classes]` and#labels of shape `[batch_size]`. But higher dimensions are supported.#Each entry in `labels` must be an index in `[0, num_classes)`#输出:loss [batch_size]tf. nn.softmax_cross_entropy_with_logits(logits,targets, dim=-1, name=None)
def softmax_cross_entropy_with_logits(logits, targets, dim=-1, name=None):#`logits` and `labels` must have the same shape `[batch_size, num_classes]`#return loss:[batch_size], 里面保存是batch中每个样本的cross entropytf.nn.sigmoid_cross_entropy_with_logits(logits,targets, name=None)
def sigmoid_cross_entropy_with_logits(logits, targets, name=None):#logits:[batch_size, num_classes],targets:[batch_size, size].logits作为用最后一层的输入就好,不需要进行sigmoid运算,函数内部进行了sigmoid操作。#输出loss [batch_size, num_classes]。。。说的是logits,其实内部实现是relutf.nn.nce_loss(nce_weights,nce_biases, embed, train_labels, num_sampled, vocabulary_size)
def nce_loss(nce_weights, nce_biases, embed, train_labels, num_sampled, vocabulary_size):#word2vec中用到了这个函数#weights: A `Tensor` of shape `[num_classes, dim]`, or a list of `Tensor`# objects whose concatenation along dimension 0 has shape# [num_classes, dim]. The (possibly-partitioned) class embeddings.#biases: A `Tensor` of shape `[num_classes]`. The class biases.#inputs: A `Tensor` of shape `[batch_size, dim]`. The forward# activations of the input network.#labels: A `Tensor` of type `int64` and shape `[batch_size,# num_true]`. The target classes.#num_sampled: An `int`. The number of classes to randomly sample per batch.#num_classes: An `int`. The number of possible classes.#num_true: An `int`. The number of target classes per training example.tf.nn.sequence_loss_by_example(logits,targets, weights, average_across_timesteps=True, softmax_loss_function=None,name=None):
def sequence_loss_by_example(logits, targets, weights, average_across_timesteps=True, softmax_loss_function=None, name=None):#logits: List of 2D Tensors of shape [batch_size x num_decoder_symbols].#targets: List of 1D batch-sized int32 Tensors of the same length as logits.#weights: List of 1D batch-sized float-Tensors of the same length as logits.#return:log_pers 形状是 [batch_size]. for logit, target, weight in zip(logits, targets, weights):ifsoftmax_loss_functionisNone:
# TODO(irving,ebrevdo): This reshape is needed because # sequence_loss_by_example is called with scalars sometimes, which # violates our general scalar strictness policy.target = array_ops.reshape(target, [-1])
crossent = nn_ops.sparse_softmax_cross_entropy_with_logits( logit, target)else:
crossent = softmax_loss_function(logit, target) log_perp_list.append(crossent * weight) log_perps = math_ops.add_n(log_perp_list)ifaverage_across_timesteps:
total_size = math_ops.add_n(weights) total_size +=1e-12# Just to avoid division by 0 for all-0 weights.
log_perps /= total_sizereturnlog_perps
关于weights:形状应该是[T, batch_size] ,如果input包含填充的数据,对应的weights置0,其余置1。这样就可以保证,填充的数据不会进行梯度下降。
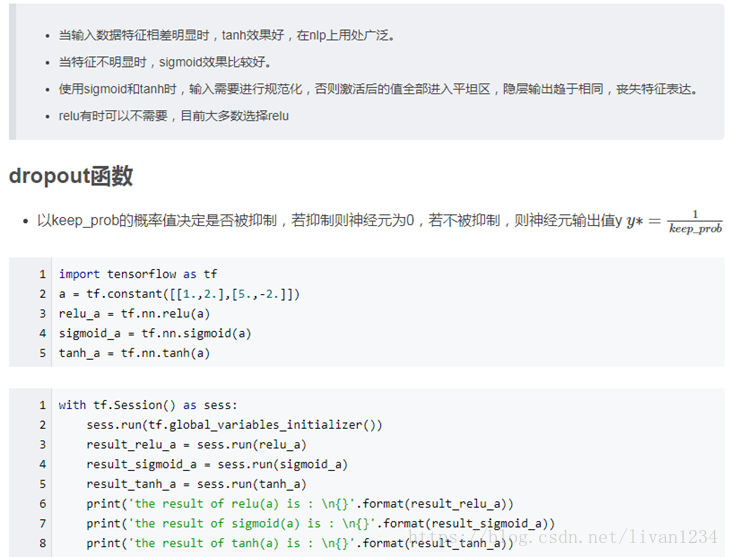
十二、激活函数:


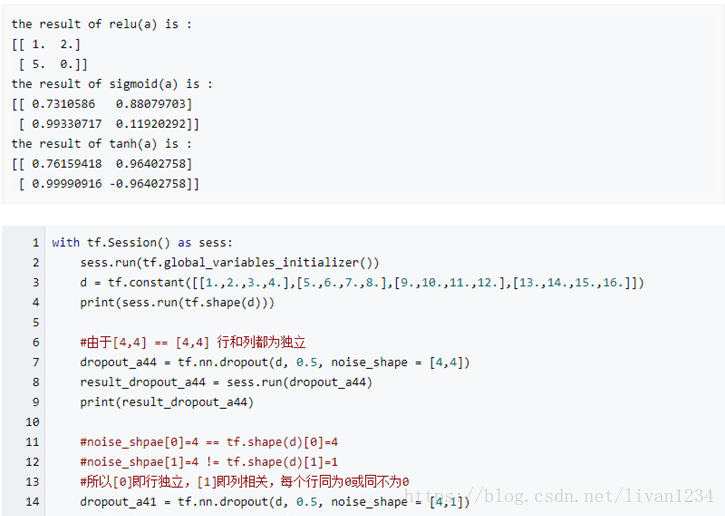

Dropout 技术:Dropout是一个同正则化完全不同的技术,与L1和L2范式正则化不同。dropout并不会修改代价函数而是修改深度网络本身。在我描述dropout的工作机制和dropout导致何种结果前,让我们假设我们正在训练如下一个网络。
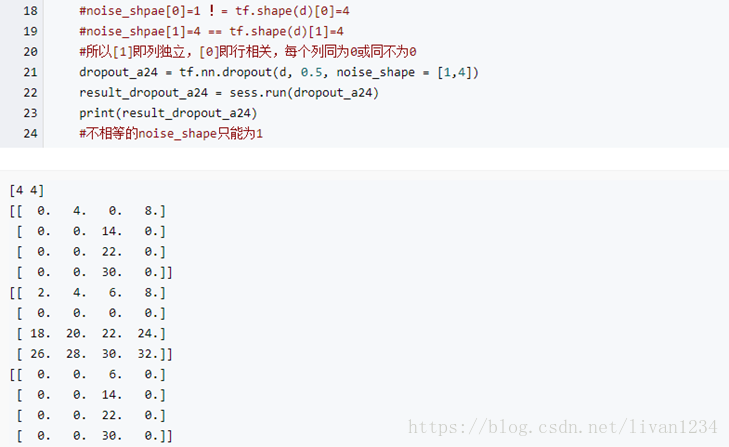
特别的,假设我们有一个输入xx并且相关的输入yy的训练。通常的我们将首先通过前馈网络把xx输入我们随机初始化权重后的网络。然后反向传播拿到对梯度的影响。也就是根据误差,根据链式法则反向拿到对相应权重的偏微分。但是,使用dropout技术的话。相关的处理就完全不同了。在开始训练的时候我们随机的(临时)删除一般的神经元。但是输入层和输出层不做变动。对深度网络dropout后。我们将会得到下图中这样类似的网络。注意。下图中的虚线存在的网络就是我们临时删除的。
我们前向传播输入项xx通过修改后的网络。然后反向传播拿到的结果通过修改后的网络。对此昨晚一个样本化的迷你批次的样本后。我们更新相应的权重和偏置。这样重复迭代处理。首先存储dropout的神经元,然后选择一个新的随机隐层神经元的子集去删除。估计不同样本批次的梯度。最后更新网络的权重和偏置。
通过不断的重复处理。我们的网络将会学到一系列的权重和偏置参数。当然这些参数是在一半的隐层神经元被dropped out(临时删除的)情况下学习到的。当我们真正的运行整个神经网络的时候意味着两倍多的隐层神经元将被激活。为了抵消此影响。我将从隐层的权重输出减半。
dropout处理看起来是奇怪并且没有规律的。为什么我们希望他对正则化有帮助呢。来解释dropout到底发生了什么。我们先不要思考dropout技术。而是想象我们用一个正常的方式训练一个神经网络。特别的。假设我们训练了几个完全不同的神经网络。用的是完全相同的训练数据。当然了。因为随机初始化参数或其他原因。训练得到的结果也许是不同的。当这种情况发生的时候,我们就可以平均这几种网络的结果,或者根据相应的规则决定使用哪一种神经网络输出的结果。例如。如果我们训练了五个网络。其中三个分类一个数字为3,最终的结果就是他是3的可能性更大一些。其他的两个网络也许有些错误。这种平均的架构被发现通常是十分有用的来减少过拟合。(当然这种训练多个网络的代价也是昂贵的。)出现这种结果的原因就是不同的网络也是在不同的方式上过你和。通过平均可以排除掉这种过拟合的。
这种现象与dropout这种技术有什么作用的。启发式的我们发现。dropout不同设置的神经元和我们训练几种不同的神经网络很像。因此,dropout处理很像是平均一个大量不同网络的平均结果。不同的网络在不同的情况下过拟合。因此,很大程度上。dropout将会减少这种过拟合。
一个相关的早期使用这种技术的论文((**ImageNetClassification with Deep Convolutional Neural Networks, by Alex Krizhevsky, Ilya Sutskever, and Geoffrey Hinton(2012).))中启发性的dropout解释是:这种技术减少了神经元之间复杂的共适性。因为一个神经元不能依赖其他特定的神经元。因此,不得不去学习随机子集神经元间的鲁棒性的有用连接。换句话说。想象我们的神经元作为要给预测的模型,dropout是一种方式可以确保我们的模型在丢失一个个体线索的情况下保持健壮的模型。在这种情况下,可以说他的作用和L1和L2范式正则化是相同的。都是来减少权重连接,然后增加网络模型在缺失个体连接信息情况下的鲁棒性。
当然,真正使dropout作为一个强大工具的原因是它在提高神经网络的表现方面是非常成功的。原始的dropout被发现的论文()介绍了这种技术对不同任务执行的结果。对我们来说。我们对dropout这种技术对手写字识别的提升特别感兴趣。用一个毫无新意的前馈神经网络。论文表明最好的结果实现的是98.4984的正确率。通过使用dropout和L2范式正则化。正确率提升到了98.7987.同样显著的效果也在其他任务中得到了体现。包括图像识别,语音识别,自然语言处理。大型深度网络过拟合现象很突出。dropout在训练大型的深度网络的时候在解决过拟合问题的非常有用。
十三、训练好的模型如何保存:
如何使用tensorflow内置的参数导出和导入方法:基本用法
如果你还在纠结如何保存tensorflow训练好的模型参数,用这个方法就对了
importtensorflowastf
"""变量声明,运算声明 例:w = tf.get_variable(name="vari_name", shape=[], dtype=tf.float32)初始化op声明"""#创建saver对象,它添加了一些op用来save和restore模型参数saver = tf.train.Saver() with tf.Session() as sess:
sess.run(init_op) #训练模型。。。 #使用saver提供的简便方法去调用 save op saver.save(sess, "save_path/file_name.ckpt") #file_name.ckpt如果不存在的话,会自动创建#后缀可加可不加现在,训练好的模型参数已经存储好了,我们来看一下怎么调用训练好的参数
变量保存的时候,保存的是 变量名:value,键值对。restore的时候,也是根据key-value来进行的(详见)
importtensorflowastf
"""变量声明,运算声明初始化op声明"""#创建saver 对象saver = tf.train.Saver()with tf.Session() as sess:
sess.run(init_op)#在这里,可以执行这个语句,也可以不执行,即使执行了,初始化的值也会被restore的值给override saver.restore(sess, "save_path/file_name.ckpt-???") #会将已经保存的变量值resotre到变量中,自己看好要restore哪步的如何restore变量的子集,然后使用初始化op初始化其他变量
#想要实现这个功能的话,必须从Saver的构造函数下手saver=tf.train.Saver([sub_set])init = tf.initialize_all_variables()with tf.Session() as sess:
#这样你就可以使用restore的变量替换掉初始化的变量的值,而其它初始化的值不受影响 sess.run(init)ifrestor_from_checkpoint:
saver.restore(sess,"file.ckpt") # train saver.save(sess,"file.ckpt")Saver
tensorflow 中的 Saver 对象是用于 参数保存和恢复的。如何使用呢?
这里介绍了一些基本的用法。
官网中给出了这么一个例子:
v1 = tf.Variable(..., name='v1')v2 = tf.Variable(..., name='v2')# Pass the variables as a dict:saver = tf.train.Saver({'v1': v1,'v2': v2})
# Or pass them as a list.saver = tf.train.Saver([v1, v2])# Passing a list is equivalent to passing a dict with the variable op names# as keys:saver = tf.train.Saver({v.op.name: v for v in [v1, v2]})#注意,如果不给Saver传var_list 参数的话, 他将已 所有可以保存的 variable作为其var_list的值。这里使用了三种不同的方式来创建 saver 对象, 但是它们内部的原理是一样的。我们都知道,参数会保存到 checkpoint 文件中,通过键值对的形式在 checkpoint中存放着。如果 Saver 的构造函数中传的是 dict,那么在 save 的时候,checkpoint文件中存放的就是对应的 key-value。如下:
importtensorflowastf
# Create some variables.v1 = tf.Variable(1.0, name="v1")v2 = tf.Variable(2.0, name="v2")saver = tf.train.Saver({"variable_1":v1, "variable_2": v2})# Use the saver object normally after that.with tf.Session() as sess:
tf.global_variables_initializer().run() saver.save(sess, 'test-ckpt/model-2')我们通过官方提供的工具来看一下 checkpoint 中保存了什么
from tensorflow.python.tools.inspect_checkpoint import print_tensors_in_checkpoint_file
print_tensors_in_checkpoint_file("test-ckpt/model-2",None,True)
# 输出:#tensor_name: variable_1#1.0#tensor_name: variable_2#2.0如果构建saver对象的时候,我们传入的是 list, 那么将会用对应 Variable 的 variable.op.name 作为 key。
importtensorflowastf
# Create some variables.v1 = tf.Variable(1.0, name="v1")v2 = tf.Variable(2.0, name="v2")saver = tf.train.Saver([v1, v2])# Use the saver object normally after that.with tf.Session() as sess:
tf.global_variables_initializer().run() saver.save(sess, 'test-ckpt/model-2')我们再使用官方工具打印出 checkpoint 中的数据,得到
tensor_name: v11.0tensor_name: v22.0如果我们现在想将 checkpoint 中v2的值restore到v1 中,v1的值restore到v2中,我们该怎么做?
这时,我们只能采用基于 dict 的 saver
importtensorflowastf
# Create some variables.v1 = tf.Variable(1.0, name="v1")v2 = tf.Variable(2.0, name="v2")saver = tf.train.Saver({"variable_1":v1, "variable_2": v2})# Use the saver object normally after that.with tf.Session() as sess:
tf.global_variables_initializer().run() saver.save(sess, 'test-ckpt/model-2')save 部分的代码如上所示,下面写 restore 的代码,和save代码有点不同。
importtensorflowastf
# Create some variables.v1 = tf.Variable(1.0, name="v1")v2 = tf.Variable(2.0, name="v2")#restore的时候,variable_1对应到v2,variable_2对应到v1,就可以实现目的了。saver = tf.train.Saver({"variable_1":v2, "variable_2": v1})# Use the saver object normally after that.with tf.Session() as sess:
tf.global_variables_initializer().run() saver.restore(sess, 'test-ckpt/model-2') print(sess.run(v1), sess.run(v2))# 输出的结果是 2.0 1.0,如我们所望我们发现,其实 创建 saver对象时使用的键值对就是表达了一种对应关系:
· save时,表示:variable的值应该保存到 checkpoint文件中的哪个 key下
· restore时,表示:checkpoint文件中key对应的值,应该restore到哪个variable
其它
一个快速找到ckpt文件的方式
ckpt = tf.train.get_checkpoint_state(ckpt_dir)if ckpt and ckpt.model_checkpoint_path:
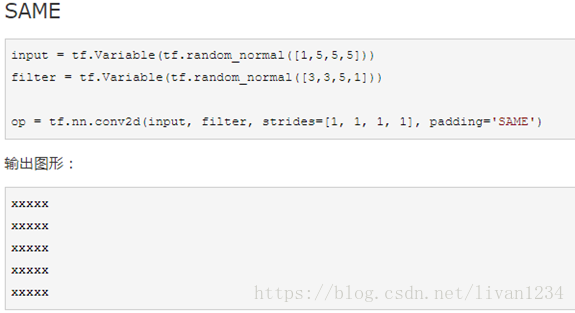
saver.restore(sess, ckpt.model_checkpoint_path)十四、conv2d卷积函数的应用:




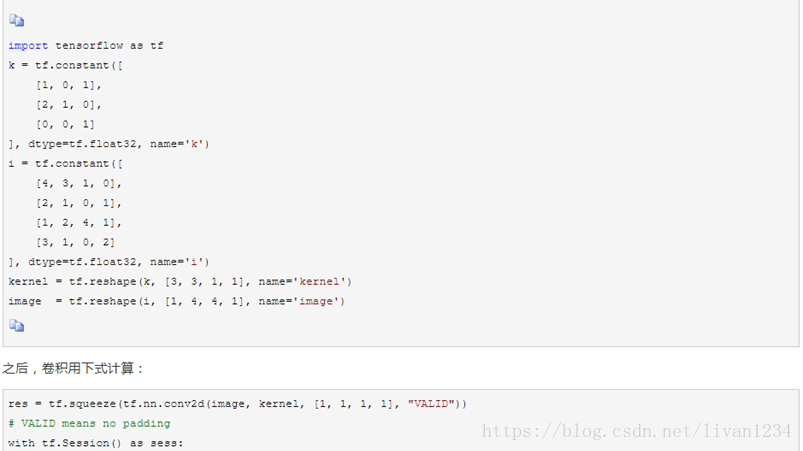


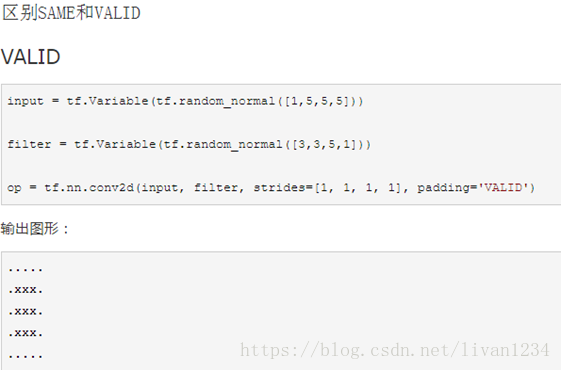
Ø VALID的方式是采用丢弃的方式,比如上述的input_width=13,只允许滑动2次,多余的元素全部丢掉;
Ø SAME的方式是采用的是补全的方式,对于上述的情况,允许滑动3次,但是需要补3个元素,左奇右偶,在左边补一个0,右边补2个0。
十五、如何获取shape:
1,tf.shape(a)和a.get_shape()比较:
相同点:都可以得到tensor a的尺寸
不同点:tf.shape()中a 数据的类型可以是tensor, list,array;
可以为:tf.shape(x)[2],即取第三个值。
a.get_shape()中a的数据类型只能是tensor,且返回的是一个元组(tuple);
2,例子:
[python] view plain copy
1. import tensorflow as tf
2. import numpy as np
3.
4. x=tf.constant([[1,2,3],[4,5,6]]
5. y=[[1,2,3],[4,5,6]]
6. z=np.arange(24).reshape([2,3,4]))
7.
8. sess=tf.Session()
9. # tf.shape()
10. x_shape=tf.shape(x) # x_shape 是一个tensor
11. y_shape=tf.shape(y) # <tf.Tensor ‘Shape_2:0’ shape=(2,) dtype=int32>
12. z_shape=tf.shape(z) # <tf.Tensor ‘Shape_5:0’ shape=(3,) dtype=int32>
13. print sess.run(x_shape) # 结果:[2 3]
14. print sess.run(y_shape) # 结果:[2 3]
15. print sess.run(z_shape) # 结果:[2 3 4]
16.
17.
18. #a.get_shape()
19. x_shape=x.get_shape() # 返回的是TensorShape([Dimension(2), Dimension(3)]),不能使用 sess.run() 因为返回的不是tensor 或string,而是元组
20. x_shape=x.get_shape().as_list() # 可以使用 as_list()得到具体的尺寸,x_shape=[2 3]
21. y_shape=y.get_shape() # AttributeError: ‘list’ object has no attribute ‘get_shape’
22. z_shape=z.get_shape() # AttributeError: ‘numpy.ndarray’ object has no attribute ‘get_shape’
23.
Fetch的意思就是在一个会话(session)中可以同时运行多个op。
24. #coding:utf-8
25. import tensorflow as tf
26. #Fetch
27. input1 = tf.constant(3.0)
28. input2 = tf.constant(1.0)
29. input3 = tf.constant(5.0)
30. add = tf.add(input1,input2)
31. mul = tf.multiply(input1,add)
32. with tf.Session() as sess:
33. result =sess.run([mul,add]) #同时运行两个op
34. print (result)
结果:
35. Total memory: 10.91GiB
36. Free memory: 10.21GiB
37. I tensorflow/core/common_runtime/gpu/gpu_device.cc:906] DMA: 0
38. I tensorflow/core/common_runtime/gpu/gpu_device.cc:916] 0: Y
39. I tensorflow/core/common_runtime/gpu/gpu_device.cc:975] CreatingTensorFlow device (/gpu:0) -> (device: 0, name: GeForce GTX 1080 Ti, pci busid: 0000:03:00.0)
40. [12.0, 4.0]
Feed的字面意思是喂养,流入。在tensorflow里面就是说先声明一个或者几个tensor,先用占位符给他们留几个位置,等到后面run的时候,再以其他形式比如字典的形式把值传进去,相当于买了两个存钱罐,先不存钱,等我想存的时候我再把钱一张一张“喂”进去。
41. #Feed
42. #创建占位符
43. input1 = tf.placeholder(tf.float32)
44. input2 = tf.placeholder(tf.float32)
45. output = tf.multiply(input1,input2)
46.
47. with tf.Session() as sess:
48. #feed的数据以字典的形式传入
49. print(sess.run(output,feed_dict={input1:[7.], input2:[8.]}))
结果:
50. I tensorflow/core/common_runtime/gpu/gpu_device.cc:975] Creating TensorFlowdevice (/gpu:0) -> (device: 0, name: GeForce GTX 1080 Ti, pci bus id:0000:03:00.0)
51. [ 56.]
52.
十六、会话执行:
session.run([fetch1, fetch2]):
关于 session.run([fetch1, fetch2]) :是执行括号中的会话。
执行sess.run()时,tensorflow是否计算了整个图。
我们在编写代码的时候,总是要先定义好整个图,然后才调用sess.run()。那么调用sess.run()的时候,程序是否执行了整个图。
53. import tensorflow as tf
54. state = tf.Variable(0.0,dtype=tf.float32)
55. one = tf.constant(1.0,dtype=tf.float32)
56. new_val = tf.add(state, one)
57. update = tf.assign(state, new_val) #返回tensor,值为new_val
58. update2 = tf.assign(state, 10000) #没有fetch,便没有执行
59. init = tf.initialize_all_variables()
60. with tf.Session() as sess:
61. sess.run(init)
62. for _ in range(3):
63. printsess.run(update)
和上个程序差不多,但我们这次仅仅是fetch “update”,输出是1.0 , 2.0, 3.0,可以看出,tensorflow并没有计算整个图,只是计算了与想要fetch 的值相关的部分
sess.run()中的feed_dict
我们都知道feed_dict的作用是给使用placeholder创建出来的tensor赋值。其实,他的作用更加广泛:feed 使用一个 值临时替换一个 op 的输出结果. 你可以提供 feed 数据作为 run() 调用的参数. feed 只在调用它的方法内有效, 方法结束, feed 就会消失.
64. import tensorflow as tf
65. y = tf.Variable(1)
66. b = tf.identity(y)
67. with tf.Session() as sess:
68. tf.global_variables_initializer().run()
69. print(sess.run(b,feed_dict={y:3})) #使用3 替换掉
70. #tf.Variable(1)的输出结果,所以打印出来3
71. #feed_dict{y.name:3} 和上面写法等价
72.
73. print(sess.run(b)) #由于feed只在调用他的方法范围内有效,所以这个打印的结果是 1
74.
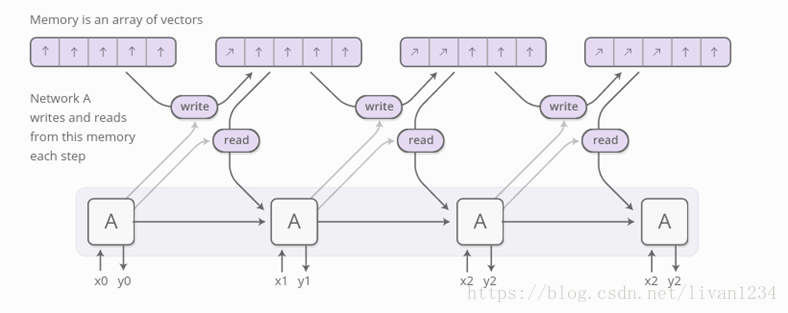
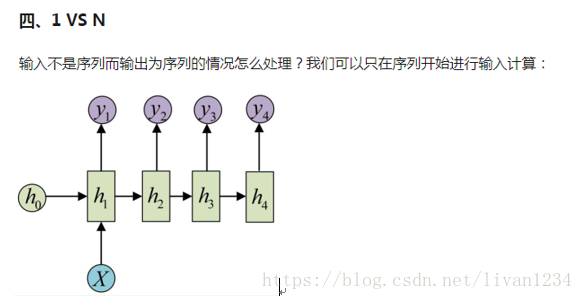
十七、LSTM的图示流程:
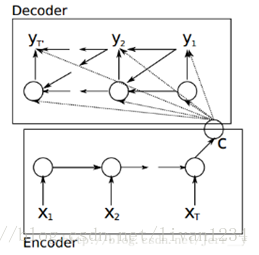
十八、从Encoder到Decoder实现Seq2Seq模型:
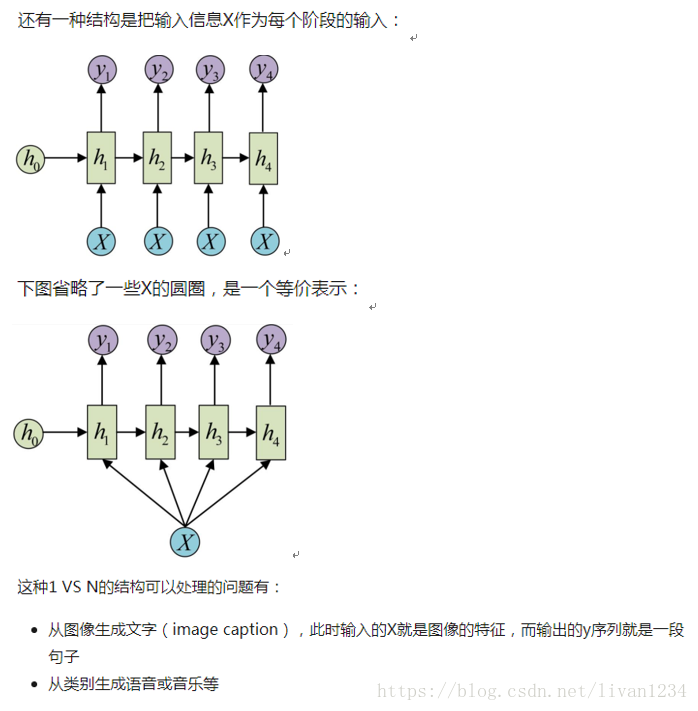
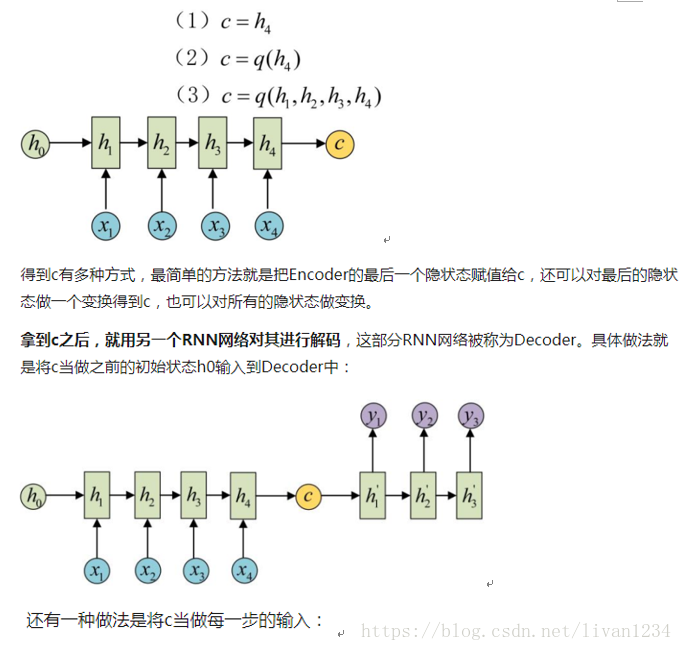
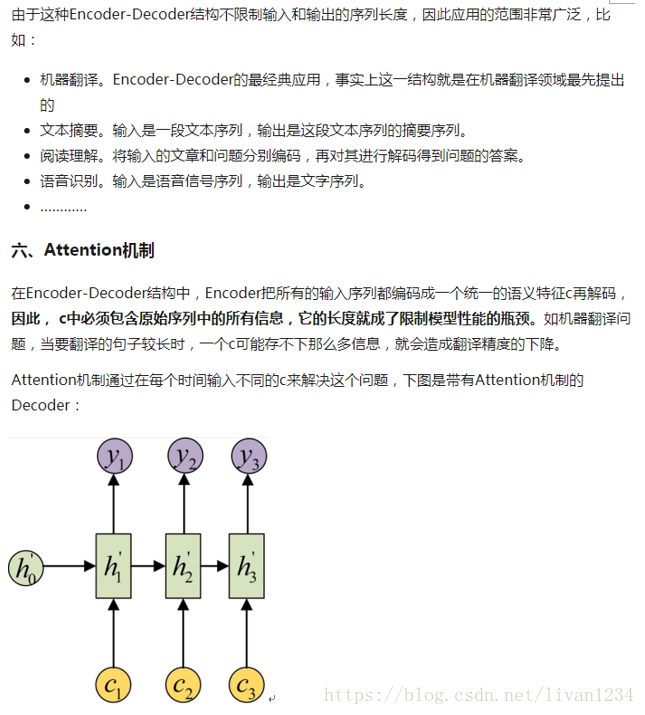
其中 Encoder 部分应该是非常容易理解的,就是一个RNNCell(RNN ,GRU,LSTM 等)结构。每个 timestep,我们向 Encoder 中输入一个字/词(一般是表示这个字/词的一个实数向量),直到我们输入这个句子的最后一个字/词 XTXT ,然后输出整个句子的语义向量 c(一般情况下, c=hXTc=hXT , XTXT 是最后一个输入)。因为 RNN 的特点就是把前面每一步的输入信息都考虑进来了,所以理论上这个 cc 就能够把整个句子的信息都包含了,我们可以把 cc 当成这个句子的一个语义表示,也就是一个句向量。在 Decoder 中,我们根据 Encoder 得到的句向量 cc,一步一步地把蕴含在其中的信息分析出来。
前言
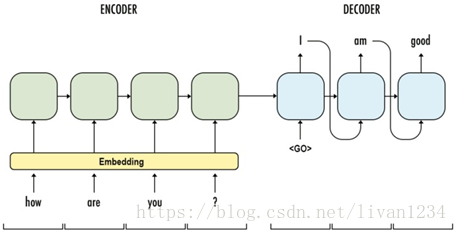
好久没有更新专栏,今天我们来看一个简单的Seq2Seq实现,我们将使用TensorFlow来实现一个基础版本的Seq2Seq,主要帮助理解Seq2Seq中的基础架构。
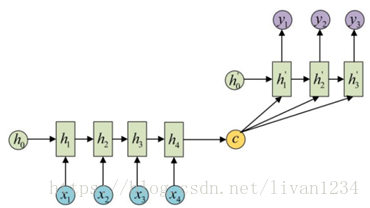
最基础的Seq2Seq模型包含了三个部分,即Encoder、Decoder以及连接两者的中间状态向量,Encoder通过学习输入,将其编码成一个固定大小的状态向量S,继而将S传给Decoder,Decoder再通过对状态向量S的学习来进行输出。
图中每一个box代表了一个RNN单元,通常是LSTM或者GRU。其实基础的Seq2Seq是有很多弊端的,首先Encoder将输入编码为固定大小状态向量的过程实际上是一个信息“信息有损压缩”的过程,如果信息量越大,那么这个转化向量的过程对信息的损失就越大,同时,随着sequencelength的增加,意味着时间维度上的序列很长,RNN模型也会出现梯度弥散。最后,基础的模型连接Encoder和Decoder模块的组件仅仅是一个固定大小的状态向量,这使得Decoder无法直接去关注到输入信息的更多细节。由于基础Seq2Seq的种种缺陷,随后引入了Attention的概念以及Bi-directional encoder layer等,由于本篇文章主要是构建一个基础的Seq2Seq模型,对其他改进tricks先不做介绍。
Seq2seq-attention模型的原理:



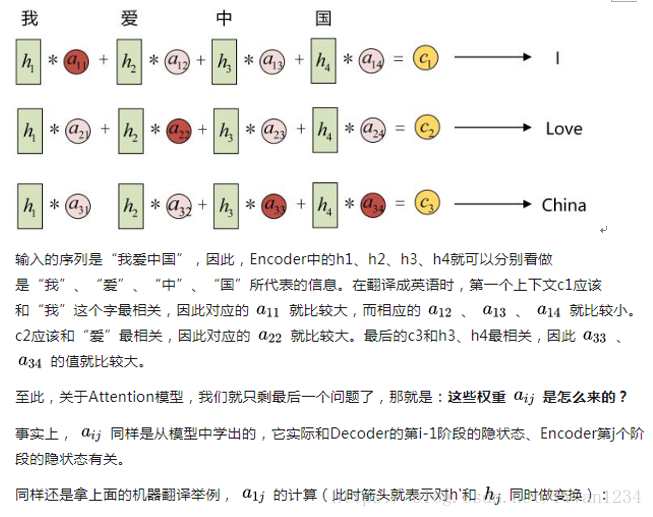
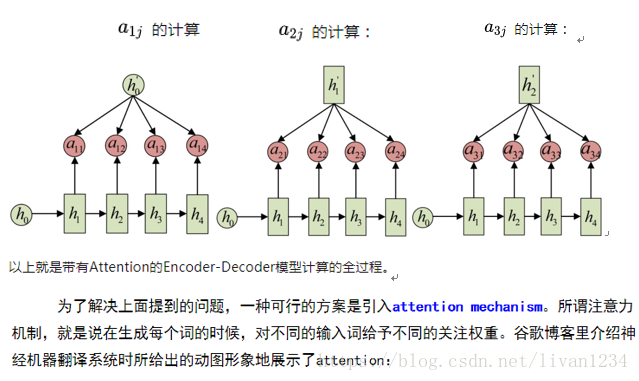
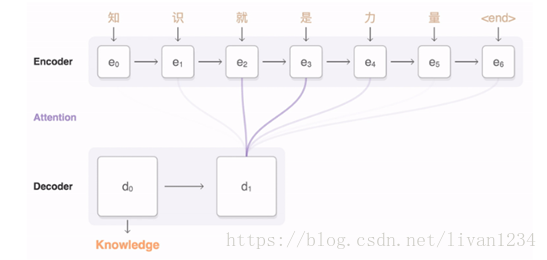
从图形可以看出,encoder中会有一个向量矩阵,通过e(i)的向量矩阵与decoder中的d(i-1)个节点可以逐一的计算出decoder中的内容。
当计算d(0)时,首先计算c(1),即用e(0)与d(初始值)两个值计算出注意项c(1),c1=f(e0,d初始值),然后再依据c(1)与e(1)计算出d(1),以此类推,计算出decoder中的内容。
总结起来说,基础的Seq2Seq主要包括Encoder,Decoder,以及连接两者的固定大小的State Vector。
实战代码:
下面我们就将利用TensorFlow来构建一个基础的Seq2Seq模型,通过向我们的模型输入一个单词(字母序列),例如hello,模型将按照字母顺序排序输出,即输出ehllo。
版本信息:Python 3 / TensorFlow1.1
1. 数据集
数据集包括source与target:
– source_data: 每一行是一个单词
– target_data: 每一行是经过字母排序后的“单词”,它的每一行与source_data中每一行一一对应
例如,source_data的第一行是hello,第二行是what,那么target_data中对应的第一行是ehllo,第二行是ahtw。
2. 数据预览
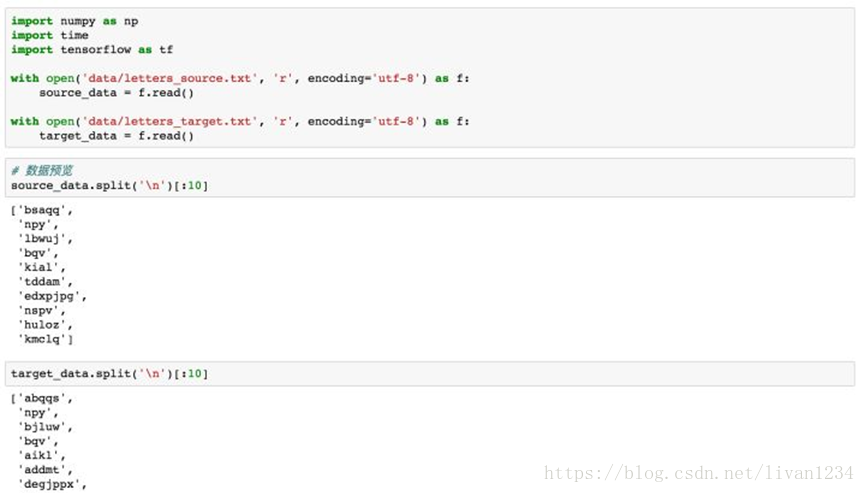

我们先把source和target数据加载进来,可以看一下前10行,target的每一行是对source源数据中的单词进行了排序。下面我们就将基于这些数据来训练一个Seq2Seq模型,来帮助大家理解基础架构。
3. 数据预处理
在神经网络中,对于文本的数据预处理无非是将文本转化为模型可理解的数字,这里都比较熟悉,不作过多解释。但在这里我们需要加入以下四种字符,<PAD>主要用来进行字符补全,<EOS>和<GO>都是用在Decoder端的序列中,告诉解码器句子的起始与结束,<UNK>则用来替代一些未出现过的词或者低频词。
· < PAD>: 补全字符。
· < EOS>: 解码器端的句子结束标识符。
· < UNK>: 低频词或者一些未遇到过的词等。
· < GO>: 解码器端的句子起始标识符。
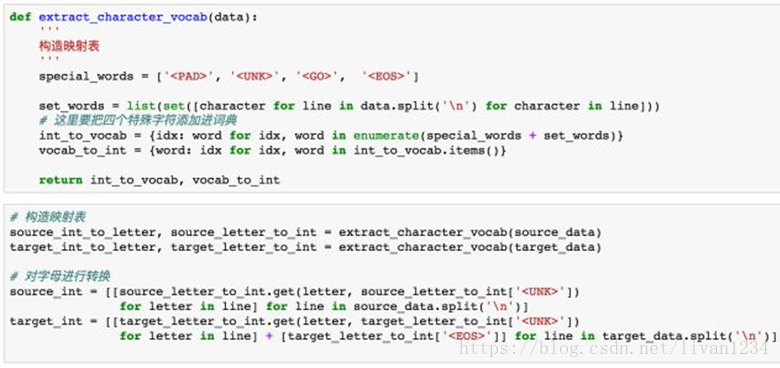
通过上面步骤,我们可以得到转换为数字后的源数据与目标数据。

4. 模型构建
Encoder
模型构建主要包括Encoder层与Decoder层。在Encoder层,我们首先需要对定义输入的tensor,同时要对字母进行Embedding,再输入到RNN层。
在这里,我们使用TensorFlow中的tf.contrib.layers.embed_sequence来对输入进行embedding。
我们来看一个栗子,假如我们有一个batch=2,sequence_length=5的样本,features =[[1,2,3,4,5],[6,7,8,9,10]],使用
tf.contrib.layers.embed_sequence(features,vocab_size=n_words, embed_dim=10)那么我们会得到一个2 x 5 x 10的输出,其中features中的每个数字都被embed成了一个10维向量。

Decoder
在Decoder端,我们主要要完成以下几件事情:
· 对target数据进行处理
· 构造Decoder
· Embedding
· 构造Decoder层
· 构造输出层,输出层会告诉我们每个时间序列的RNN输出结果
· Training Decoder
· Predicting Decoder
下面我们会对这每个部分进行一一介绍。
1. target数据处理
我们的target数据有两个作用:
· 在训练过程中,我们需要将我们的target序列作为输入传给Decoder端RNN的每个阶段,而不是使用前一阶段预测输出,这样会使得模型更加准确。(这就是为什么我们会构建Training和Predicting两个Decoder的原因,下面还会有对这部分的解释)。
· 需要用target数据来计算模型的loss。
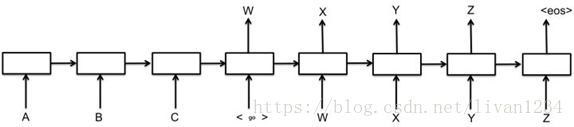
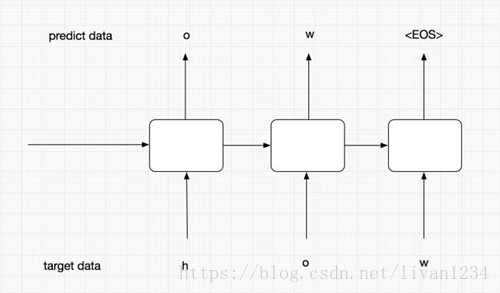
我们首先需要对target端的数据进行一步预处理。在我们将target中的序列作为输入给Decoder端的RNN时,序列中的最后一个字母(或单词)其实是没有用的。我们来用下图解释:
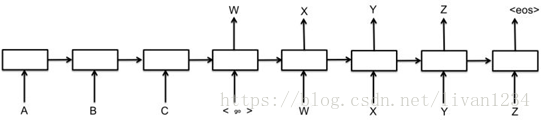
我们此时只看右边的Decoder端,可以看到我们的target序列是[<go>, W, X, Y, Z, <eos>],其中<go>,W,X,Y,Z是每个时间序列上输入给RNN的内容,我们发现,<eos>并没有作为输入传递给RNN。因此我们需要将target中的最后一个字符去掉,同时还需要在前面添加<go>标识,告诉模型这代表一个句子的开始。
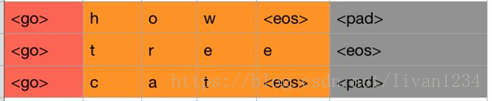
如上图,所示,红色和橙色为我们最终的保留区域,灰色是序列中的最后一个字符,我们把它删掉即可。
我们使用tf.strided_slice()来进行这一步处理。
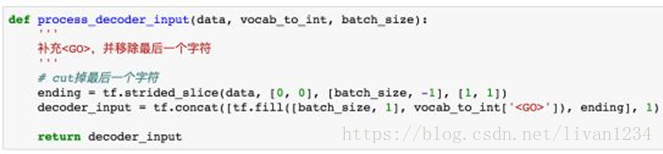
其中tf.fill(dims, value)参数会生成一个dims形状并用value填充的tensor。举个栗子:tf.fill([2,2], 7) => [[7,7], [7,7]]。tf.concat()会按照某个维度将两个tensor拼接起来。
2. 构造Decoder
· 对target数据进行embedding。
· 构造Decoder端的RNN单元。
· 构造输出层,从而得到每个时间序列上的预测结果。
· 构造training decoder。
· 构造predicting decoder。
注意,我们这里将decoder分为了training和predicting,这两个encoder实际上是共享参数的,也就是通过training decoder学得的参数,predicting会拿来进行预测。那么为什么我们要分两个呢,这里主要考虑模型的robust。
在training阶段,为了能够让模型更加准确,我们并不会把t-1的预测输出作为t阶段的输入,而是直接使用target data中序列的元素输入到Encoder中。而在predict阶段,我们没有target data,有的只是t-1阶段的输出和隐层状态。
上面的图中代表的是training过程。在training过程中,我们并不会把每个阶段的预测输出作为下一阶段的输入,下一阶段的输入我们会直接使用target data,这样能够保证模型更加准确。
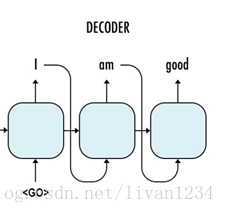
这个图代表我们的predict阶段,在这个阶段,我们没有target data,这个时候前一阶段的预测结果就会作为下一阶段的输入。
当然,predicting虽然与training是分开的,但他们是会共享参数的,training训练好的参数会供predicting使用。
decoder层的代码如下:

构建好了Encoder层与Decoder以后,我们需要将它们连接起来build我们的Seq2Seq模型。

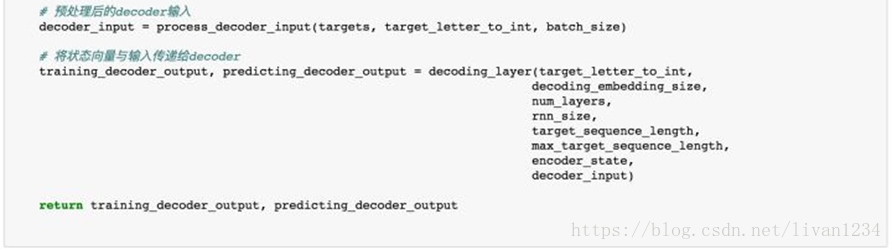
定义超参数:
# 超参数# Number of Epochsepochs = 60# Batch Sizebatch_size = 128# RNN Sizernn_size = 50# Number of Layersnum_layers = 2# Embedding Sizeencoding_embedding_size = 15decoding_embedding_size = 15# Learning Ratelearning_rate = 0.001定义loss function、optimizer以及gradient clipping
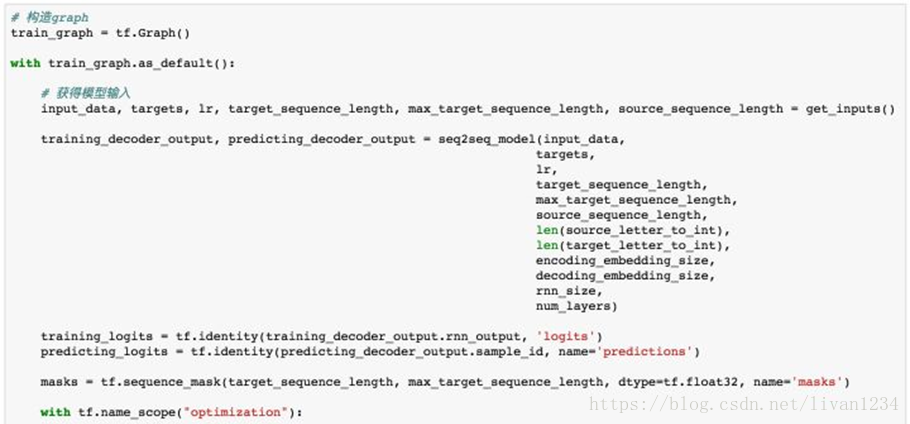
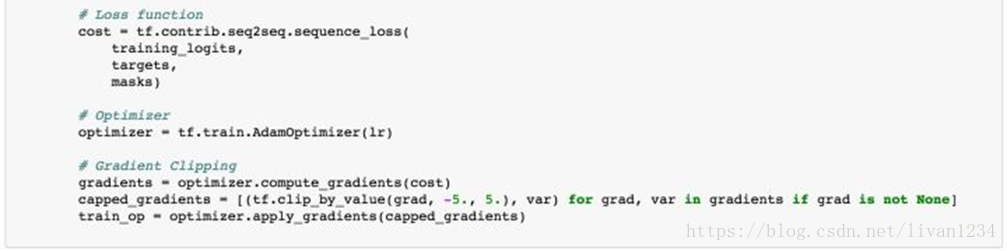
目前为止我们已经完成了整个模型的构建,但还没有构造batch函数,batch函数用来每次获取一个batch的训练样本对模型进行训练。
在这里,我们还需要定义另一个函数对batch中的序列进行补全操作。这是啥意思呢?我们来看个例子,假如我们定义了batch=2,里面的序列分别是:
[['h', 'e', 'l', 'l', 'o'], ['w', 'h', 'a', 't']]那么这两个序列的长度一个是5,一个是4,变长的序列对于RNN来说是没办法训练的,所以我们这个时候要对短序列进行补全,补全以后,两个序列会变成下面的样子:
[['h', 'e', 'l', 'l', 'o'], ['w', 'h', 'a', 't', '<PAD>']]这样就保证了我们每个batch中的序列长度是固定的。

感谢@Gang He提出的错误。此处代码已修正。修改部分为get_batches中的两个for循环,for target in targets_batch和for source in sources_batch(之前的代码是for target in pad_targets_batch和for source in pad_sources_batch),因为我们用sequence_mask计算了每个句子的权重,该权重作为参数传入loss函数,主要用来忽略句子中pad部分的loss。如果是对pad以后的句子进行loop,那么输出权重都是1,不符合我们的要求。在这里做出修正。GitHub上代码也已修改。
至此,我们完成了整个模型的构建与数据的处理。接下来我们对模型进行训练,我定义了batch_size=128,epochs=60。训练loss如下:

模型预测:
我们通过实际的例子来进行验证。
输入“hello”:

输入“machine”:

输入“common”:

总结:
至此,我们实现了一个基本的序列到序列模型,Encoder通过对输入序列的学习,将学习到的信息转化为一个状态向量传递给Decoder,Decoder再基于这个输入得到输出。除此之外,我们还知道要对batch中的单词进行补全保证一个batch内的样本具有相同的序列长度。
我们可以看到最终模型的训练loss相对已经比较低了,并且从例子看,其对短序列的输出还是比较准确的,但一旦我们的输入序列过长,比如15甚至20个字母的单词,其Decoder端的输出就非常的差。
Seq2seq的常用函数:
Ø tf.sampled_softmax_loss():
进行候选采样的时候,每次只评估所有类别的一个很小的子集,这样可以提高运算效率,在这样的方式下,计算函数的对应损失需要用到tf.sampled_softmax_loss()。tf.sampled_softmax_loss()中调用了_compute_sampled_logits() #此函数和nce_loss是差不多的, 取样求lossdef sampled_softmax_loss(weights, #[num_classes, dim] biases, #[num_classes] inputs, #[batch_size, dim] labels, #[batch_size, num_true] num_sampled, num_classes, num_true=1, sampled_values=None, remove_accidental_hits=True, partition_strategy="mod", name="sampled_softmax_loss"):#return: [batch_size]关于参数labels:一般情况下,num_true为1, labels的shpae为[batch_size, 1]。假设我们有1000个类别, 使用one_hot形式的label的话, 我们的labels的shape是[batch_size,num_classes]。显然,如果num_classes非常大的话,会影响计算性能。所以,这里采用了一个稀疏的方式,即:使用3代表了[0,0,0,1,0….]
Ø tf.nn.seq2seq.embedding_attention_seq2seq()
创建了input embedding matrix 和 output embedding matrix
def embedding_attention_seq2seq(encoder_inputs, #[T, batch_size] decoder_inputs, #[out_T, batch_size] cell, num_encoder_symbols, num_decoder_symbols, embedding_size, num_heads=1, #只采用一个read head output_projection=None, feed_previous=False, dtype=None, scope=None, initial_state_attention=False):#output_projection: (W, B) W:[output_size, num_decoder_symbols]#B: [num_decoder_symbols] (1)这个函数创建了一个inputs 的 embeddingmatrix.
(2)计算了encoder的 output,并保存起来,用于计算attention
encoder_cell = rnn_cell.EmbeddingWrapper( cell, embedding_classes=num_encoder_symbols, embedding_size=embedding_size)# 创建了inputs的 embedding matrixencoder_outputs, encoder_state = rnn.rnn( encoder_cell, encoder_inputs, dtype=dtype) #return [T ,batch_size,size](3)生成attention states
top_states = [array_ops.reshape(e, [-1, 1, cell.output_size])foreinencoder_outputs]# T * batch_size * 1 * size
attention_states = array_ops.concat(1, top_states)# batch_size*T*size
(4)剩下的工作交给embedding_attention_decoder,embedding_attention_decoder中创建了decoder的embeddingmatrix
# Decoder. output_size = Noneifoutput_projectionisNone:
cell = rnn_cell.OutputProjectionWrapper(cell, num_decoder_symbols) output_size = num_decoder_symbols if isinstance(feed_previous, bool):returnembedding_attention_decoder(
decoder_inputs, encoder_state, attention_states, cell, num_decoder_symbols, embedding_size, num_heads=num_heads, output_size=output_size, output_projection=output_projection, feed_previous=feed_previous, initial_state_attention=initial_state_attention)tf.nn.rnn_cell.EmbeddingWrapper()
embedding_attention_seq2seq中调用了这个类
使用了这个类之后,rnn 的inputs就可以是[batch_size]了,里面保存的是word的id。
此类就是在 cell 前 加了一层embedding
class EmbeddingWrapper(RNNCell): def __init__(self, cell, embedding_classes, embedding_size, initializer=None): def __call__(self, inputs, state, scope=None):#生成embedding矩阵[embedding_classes,embedding_size] #inputs: [batch_size, 1] #return : (output, state)tf.nn.rnn_cell.OutputProgectionWrapper()
将rnn_cell的输出映射成想要的维度
class OutputProjectionWrapper(RNNCell):def __init__(self, cell, output_size):# output_size:映射后的size
def __call__(self, inputs, state, scope=None):#init 返回一个带output projection的 rnn_celltf.nn.seq2seq.embedding_attention_decoder()
#生成embedding matrix :[num_symbols, embedding_size]def embedding_attention_decoder(decoder_inputs, # T*batch_size initial_state, attention_states, cell, num_symbols, embedding_size, num_heads=1, output_size=None, output_projection=None, feed_previous=False, update_embedding_for_previous=True, dtype=None, scope=None, initial_state_attention=False):#核心代码embedding = variable_scope.get_variable("embedding",
[num_symbols, embedding_size]) #output embedding loop_function = _extract_argmax_and_embed( embedding, output_projection,update_embedding_for_previous)iffeed_previouselseNone
emb_inp = [ embedding_ops.embedding_lookup(embedding, i) for i in decoder_inputs]returnattention_decoder(
emb_inp, initial_state, attention_states, cell, output_size=output_size, num_heads=num_heads, loop_function=loop_function, initial_state_attention=initial_state_attention)可以看到,此函数先为 decoder symbols 创建了一个embedding矩阵。然后定义了loop_function。
emb_in是embedded input :[T, batch_size, embedding_size]
函数的主要工作还是交给了attention_decoder()
tf.nn.attention_decoder()
def attention_decoder(decoder_inputs, #[T, batch_size, input_size] initial_state, #[batch_size, cell.states] attention_states, #[batch_size , attn_length , attn_size] cell, output_size=None, num_heads=1, loop_function=None, dtype=None, scope=None, initial_state_attention=False):论文中,在计算attention distribution的时候,提到了三个公式
(1)uti=vT∗tanh(W1∗hi+W2∗dt)(1)uit=vT∗tanh(W1∗hi+W2∗dt)
(2)sti=softmax(ati)(2)sit=softmax(ait)
(3)d′=∑i=1TAsti∗hi(3)d′=∑i=1TAsit∗hi
其中,W1W1维度是[attn_vec_size, size], hihi:[size,1],我们日常表示输入数据,都是用列向量表示,但是在tensorflow中,趋向用行向量表示。在这个函数中,为了计算 W1∗hiW1∗hi,使用了卷积的方式。
hidden = array_ops.reshape(attention_states, [-1, attn_length,1, attn_size])#[batch_size * T * 1 * input_size]
hidden_features = [] v = [] attention_vec_size = attn_size # Size of query vectors for attention.forainxrange(num_heads):
k = variable_scope.get_variable("AttnW_%d"% a,
[1,1, attn_size, attention_vec_size])
hidden_features.append(nn_ops.conv2d(hidden, k, [1, 1, 1, 1], "SAME")) v.append( variable_scope.get_variable("AttnV_%d" % a, [attention_vec_size])) #attention_vec_size = attn_size使用conv2d之后,返回的tensor的形状是[batch_size,attn_length, 1, attention_vec_size]
此函数是这么求 W2∗dtW2∗dt 和 sisi的。
y = linear(query, attention_vec_size,True)
y = array_ops.reshape(y, [-1,1,1, attention_vec_size])
# Attention mask is a softmax of v^T * tanh(...). s = math_ops.reduce_sum( v[a] * math_ops.tanh(hidden_features[a] + y), [2, 3]) #[batch_size, attn_length, 1, attn_size] a = nn_ops.softmax(s) #s" [batch_size * attn_len] # Now calculate the attention-weighted vector d. d = math_ops.reduce_sum(array_ops.reshape(a, [-1, attn_length,1,1]) * hidden,
[1,2])
ds.append(array_ops.reshape(d, [-1, attn_size]))y=W2∗dt,d=d′y=W2∗dt,d=d′
def rnn()
from tensorflow.python.ops import rnn
rnn.rnn()def rnn(cell, inputs, initial_state=None, dtype=None, sequence_length=None, scope=None):#inputs: A length T list of inputs, each a `Tensor` of shape`[batch_size, input_size]`#sequence_length: [batch_size], 指定sample 序列的长度#return : (outputs, states), outputs: T*batch_size*output_size. states:batch_size*stateseq2seqModel
· 创建映射参数 proj_w, proj_b
· 声明:sampled_loss,看了word2vec的就会理解
· 声明:seq2seq_f(),构建了inputs的embedding和outputs的embedding,进行核心计算
· 使用model_with_buckets(),model_with_buckets中调用了seq2seq_f和 sampled_loss
model_with_buckets()
调用方法tf.nn.seq2seq.model_with_buckets()
def model_with_buckets(encoder_inputs, decoder_inputs, targets, weights, buckets, seq2seq, softmax_loss_function=None, per_example_loss=False, name=None):"""Create a sequence-to-sequence model with support for bucketing.The seq2seq argument is a function that defines a sequence-to-sequence model,e.g., seq2seq = lambda x, y: basic_rnn_seq2seq(x, y, rnn_cell.GRUCell(24))Args:encoder_inputs: A list of Tensors to feed the encoder; first seq2seq input.decoder_inputs: A list of Tensors to feed the decoder; second seq2seq input.targets: A list of 1D batch-sized int32 Tensors (desired output sequence).weights: List of 1D batch-sized float-Tensors to weight the targets.buckets: A list of pairs of (input size, output size) for each bucket.seq2seq: A sequence-to-sequence model function; it takes 2 input that agree with encoder_inputs and decoder_inputs, and returns a pair consisting of outputs and states (as, e.g., basic_rnn_seq2seq).softmax_loss_function: Function (inputs-batch, labels-batch) -> loss-batchto be used instead of the standard softmax (the default if this is None).per_example_loss: Boolean. If set, the returned loss will be a batch-sizedtensor of losses for each sequence in the batch. If unset, it will bea scalar with the averaged loss from all examples.name: Optional name for this operation, defaults to "model_with_buckets".Returns:A tuple of the form (outputs, losses), where:outputs: The outputs for each bucket. Its j'th element consists of a listof 2D Tensors. The shape of output tensors can be either[batch_size x output_size] or [batch_size x num_decoder_symbols]depending on the seq2seq model used.losses: List of scalar Tensors, representing losses for each bucket, or,if per_example_loss is set, a list of 1D batch-sized float Tensors.Raises:ValueError: If length of encoder_inputsut, targets, or weights is smallerthan the largest (last) bucket."""记住,tensorflow的编码方法是:先构图,再训练。训练是根据feed确定的
十九、word2vec方法:
用词向量来表示词并不是word2vec的首创,在很久之前就出现了。最早的词向量是很冗长的,它使用是词向量维度大小为整个词汇表的大小,对于每个具体的词汇表中的词,将对应的位置置为1。比如我们有下面的5个词组成的词汇表,词“Queen”的序号为2,那么它的词向量就是(0,1,0,0,0)(0,1,0,0,0)。同样的道理,词“Woman”的词向量就是(0,0,0,1,0)(0,0,0,1,0)。这种词向量的编码方式我们一般叫做1-of-N representation或者one hot representation.
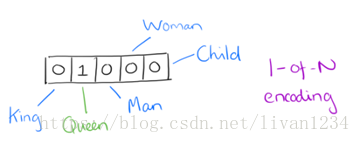
One hot representation用来表示词向量非常简单,但是却有很多问题。最大的问题是我们的词汇表一般都非常大,比如达到百万级别,这样每个词都用百万维的向量来表示简直是内存的灾难。这样的向量其实除了一个位置是1,其余的位置全部都是0,表达的效率不高,能不能把词向量的维度变小呢?
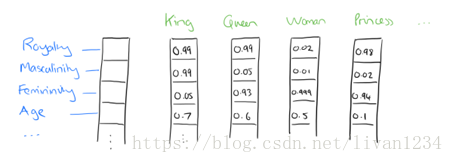
Dristributed representation可以解决One hot representation的问题,它的思路是通过训练,将每个词都映射到一个较短的词向量上来。所有的这些词向量就构成了向量空间,进而可以用普通的统计学的方法来研究词与词之间的关系。这个较短的词向量维度是多大呢?这个一般需要我们在训练时自己来指定。
比如下图我们将词汇表里的词用“Royalty”,”Masculinity”,”Femininity”和“Age”4个维度来表示,King这个词对应的词向量可能是(0.99,0.99,0.05,0.7)(0.99,0.99,0.05,0.7)。当然在实际情况中,我们并不能对词向量的每个维度做一个很好的解释。
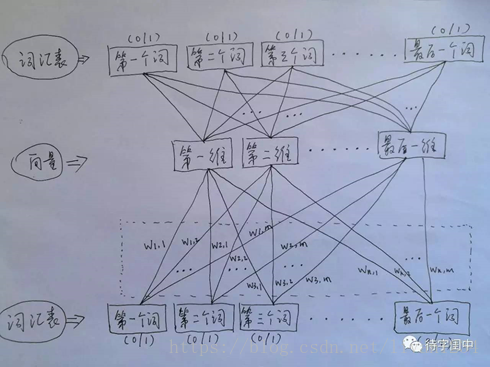
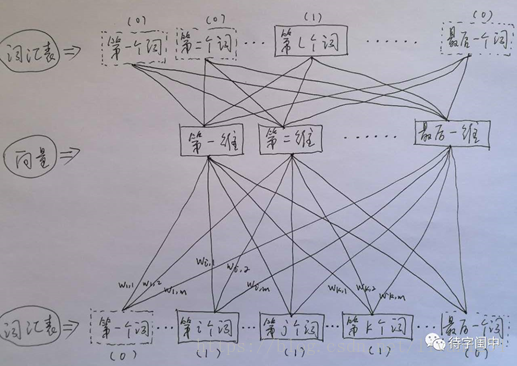
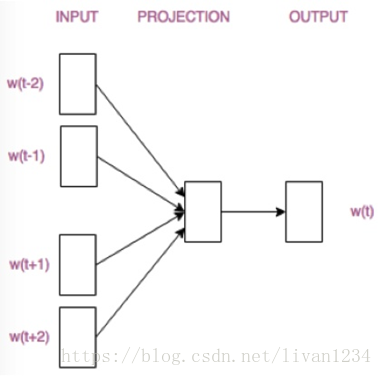
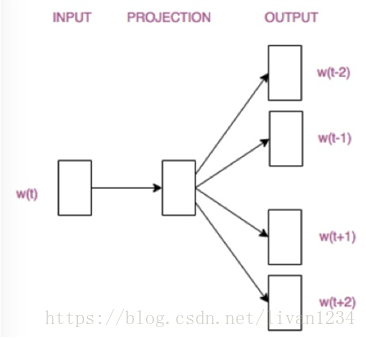
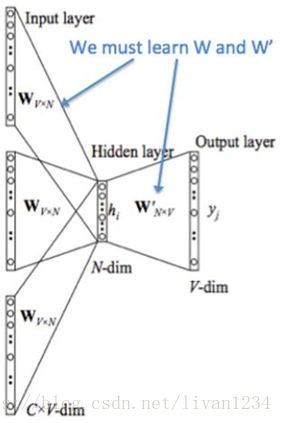
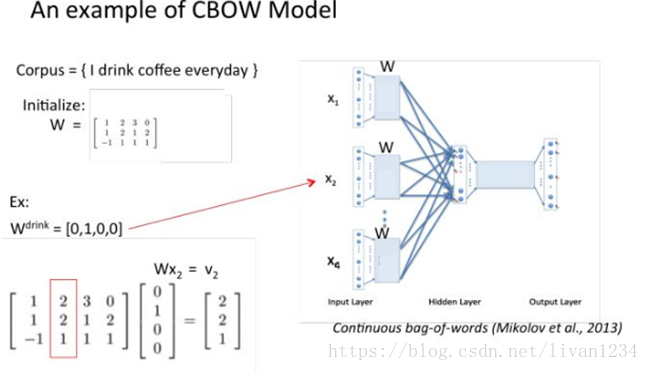
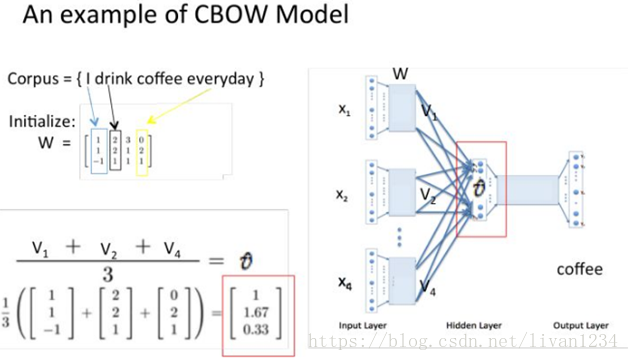
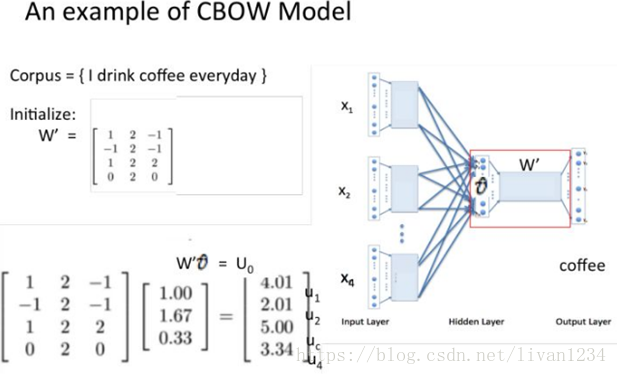
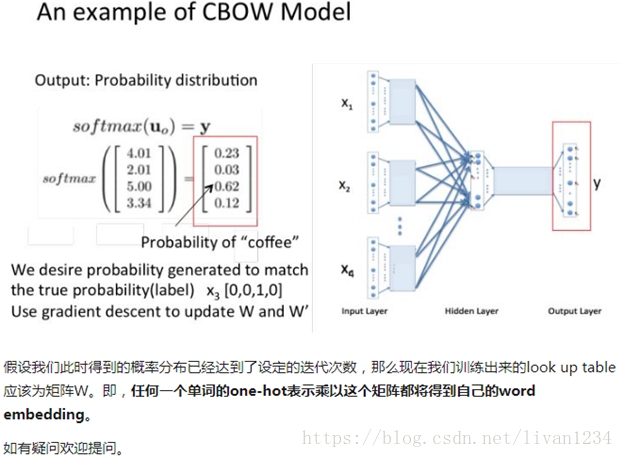
训练 Word2Vec 的思想,是利用一个词和它在文本中的上下文的词,这样就省去了人工去标注。论文中给出了 Word2Vec 的两种训练模型,CBOW (Continuous Bag-of-Words Model) 和 Skip-gram (Continuous Skip-gram Model)。
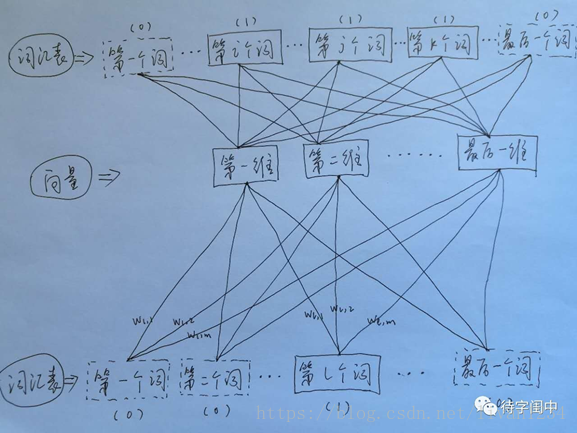
首先看CBOW,它的做法是,将一个词所在的上下文中的词作为输入,而那个词本身作为输出,也就是说,看到一个上下文,希望大概能猜出这个词和它的意思。通过在一个大的语料库训练,得到一个从输入层到隐含层的权重模型。如下图所示,第l个词的上下文词是i,j,k,那么i,j,k作为输入,它们所在的词汇表中的位置的值置为1。然后,输出是l,把它所在的词汇表中的位置的值置为1。训练完成后,就得到了每个词到隐含层的每个维度的权重,就是每个词的向量。
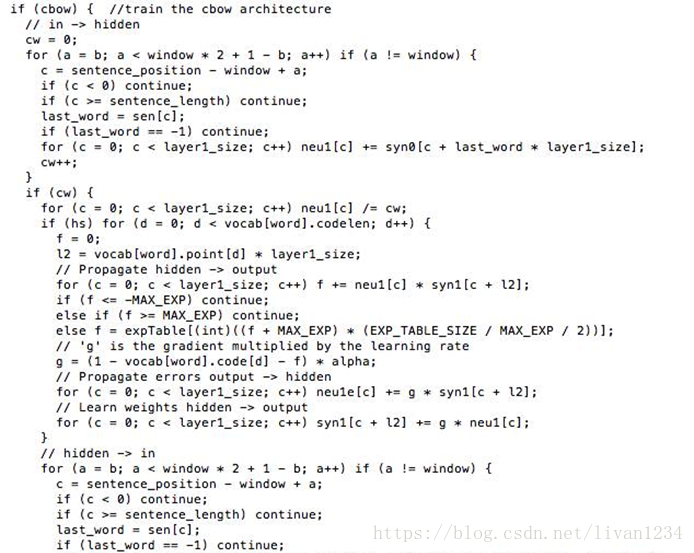
Word2Vec 代码库中关于CBOW训练的代码,其实就是神经元网路的标准反向传播算法。

接着,看看Skip-gram,它的做法是,将一个词所在的上下文中的词作为输出,而那个词本身作为输入,也就是说,给出一个词,希望预测可能出现的上下文的词。通过在一个大的语料库训练,得到一个从输入层到隐含层的权重模型。如下图所示,第l个词的上下文词是i,j,k,那么i,j,k作为输出,它们所在的词汇表中的位置的值置为1。然后,输入是l,把它所在的词汇表中的位置的值置为1。训练完成后,就得到了每个词到隐含层的每个维度的权重,就是每个词的向量。
Word2Vec 代码库中关于Skip-gram训练的代码,其实就是神经元网路的标准反向传播算法。


一个人读书时,如果遇到了生僻的词,一般能根据上下文大概猜出生僻词的意思,而 Word2Vec 正是很好的捕捉了这种人类的行为,利用神经元网络模型,发现了自然语言处理的一颗原子弹。
Ø 用图标来表示word2vec模型:
CBOW模型

Skip-gram模型



二十、梯度递减优化(gradient-clip):
tensorflow中操作gradient-clip:
在训练深度神经网络的时候,我们经常会碰到梯度消失和梯度爆炸问题,scientists提出了很多方法来解决这些问题,本篇就介绍一下如何在tensorflow中使用clip来address这些问题
train_op =tf.train.GradientDescentOptimizer(learning_rate=0.1).minimize(loss)
在调用minimize方法的时候,底层实际干了两件事:
· 计算所有 trainablevariables 梯度
· apply them to variables
随后, 在我们 sess.run(train_op) 的时候, 会对 variables 进行更新
Clip:
那我们如果想处理一下计算完的 gradients ,那该怎么办呢?
官方给出了以下步骤
1. Compute the gradients withcompute_gradients(). 计算梯度
2. Process the gradients as you wish. 处理梯度
3. Apply the processed gradients withapply_gradients(). apply处理后的梯度给variables
这样,我们以后在train的时候就会使用 processed gradient去更新 variable
框架:
# Create an optimizer.optimizer必须和variable在一个设备上声明
opt = GradientDescentOptimizer(learning_rate=0.1)
# Compute the gradients for a list of variables.
grads_and_vars = opt.compute_gradients(loss, <list ofvariables>)
# grads_and_vars is a list of tuples (gradient,variable). Do whatever you
# need to the ‘gradient’ part, for example cap them, etc.
capped_grads_and_vars = [(MyCapper(gv[0]), gv[1]) for gv in grads_and_vars]
# Ask the optimizer to apply the capped gradients.
opt.apply_gradients(capped_grads_and_vars)
例子:
#return a list of trainable variable in you model
params = tf.trainable_variables()
#create an optimizer
opt = tf.train.GradientDescentOptimizer(self.learning_rate)
#compute gradients for params
gradients = tf.gradients(loss, params)
#process gradients
clipped_gradients, norm =tf.clip_by_global_norm(gradients,max_gradient_norm)
train_op = opt.apply_gradients(zip(clipped_gradients,params)))
这时, sess.run(train_op) 就可以进行训练了
二十一、共享变量:
为什么要共享变量?我举个简单的例子:例如,当我们研究生成对抗网络GAN的时候,判别器的任务是,如果接收到的是生成器生成的图像,判别器就尝试优化自己的网络结构来使自己输出0,如果接收到的是来自真实数据的图像,那么就尝试优化自己的网络结构来使自己输出1。也就是说,生成图像和真实图像经过判别器的时候,要共享同一套变量,所以TensorFlow引入了变量共享机制,在做卷积神经网络的时候多个卷积层有可能使用同一个权重矩阵,这时就用到了共享矩阵。
变量共享主要涉及到两个函数: tf.get_variable(<name>, <shape>,<initializer>) 和tf.variable_scope(<scope_name>)。
先来看第一个函数: tf.get_variable。
tf.get_variable 和tf.Variable不同的一点是,前者拥有一个变量检查机制,会检测已经存在的变量是否设置为共享变量,如果已经存在的变量没有设置为共享变量,TensorFlow 运行到第二个拥有相同名字的变量的时候,就会报错。
例如如下代码:
def my_image_filter(input_images):
conv1_weights =tf.Variable(tf.random_normal([5, 5, 32, 32]),
name=”conv1_weights”)
conv1_biases =tf.Variable(tf.zeros([32]), name=”conv1_biases”)
conv1 =tf.nn.conv2d(input_images, conv1_weights,
strides=[1,1, 1, 1], padding=’SAME’)
return tf.nn.relu(conv1 + conv1_biases)
有两个变量(Variables)conv1_weighs, conv1_biases和一个操作(Op)conv1,如果你直接调用两次,不会出什么问题,但是会生成两套变量;
# First call creates one set of 2 variables.
result1 = my_image_filter(image1)
# Another set of 2 variables is created in the secondcall.
result2 = my_image_filter(image2)
如果把 tf.Variable 改成tf.get_variable,直接调用两次,就会出问题了:
result1 = my_image_filter(image1)
result2 = my_image_filter(image2)
# Raises ValueError(… conv1/weights already exists …)
为了解决这个问题,TensorFlow 又提出了 tf.variable_scope函数:它的主要作用是,在一个作用域 scope 内共享一些变量,可以有如下几种用法:
1)
with tf.variable_scope(“image_filters”) asscope:
result1 =my_image_filter(image1)
scope.reuse_variables() # or
#tf.get_variable_scope().reuse_variables()
result2 =my_image_filter(image2)
需要注意的是:最好不要设置 reuse 标识为False,只在需要的时候设置 reuse 标识为True。
2)
with tf.variable_scope(“image_filters1”) asscope1:
result1 =my_image_filter(image1)
with tf.variable_scope(scope1, reuse = True)
result2 =my_image_filter(image2)
通常情况下,tf.variable_scope 和tf.name_scope 配合,能画出非常漂亮的流程图,但是他们两个之间又有着细微的差别,那就是 name_scope 只能管住操作 Ops的名字,而管不住变量 Variables 的名字,看下例:
with tf.variable_scope(“foo”):
withtf.name_scope(“bar”):
v = tf.get_variable(“v”, [1])
x = 1.0 + v
assert v.name == “foo/v:0”
assert x.op.name == “foo/bar/add”
在tensorflow中,有两个scope, 一个是name_scope一个是variable_scope,这两个scope到底有什么区别呢?
先看第一个程序:
with tf.name_scope("hello") as name_scope:
arr1 = tf.get_variable("arr1", shape=[2,10],dtype=tf.float32) name_scope
print arr1.name print "scope_name:%s " % tf.get_variable_scope().original_name_scope输出为:
hello/
arr1:0
scope_name:
可以看出:
· tf.name_scope() 返回的是一个string,”hello/”
· 在name_scope使用 get_variable() 中定义的 variable 的 name 并没有 “hello/”前缀
· tf.get_variable_scope()的original_name_scope 是空
第二个程序:
with tf.variable_scope("hello") as variable_scope:
arr1 = tf.get_variable("arr1", shape=[2, 10], dtype=tf.float32) variable_scope
print variable_scope.name #打印出变量空间名字 print arr1.name print tf.get_variable_scope().original_name_scope #tf.get_variable_scope() 获取的就是variable_scope with tf.variable_scope("xixi") as v_scope2: print tf.get_variable_scope().original_name_scope #tf.get_variable_scope() 获取的就是v _scope2输出为:
<tensorflow.python.ops.variable_scope.VariableScope object at 0x7fbc09959210>hellohello/arr1:0hello/hello/xixi/可以看出:
· tf.variable_scope() 返回的是一个 VariableScope 对象
· variable_scope使用 get_variable 定义的variable 的name加上了”hello/”前缀
· tf.get_variable_scope()的original_name_scope 是嵌套后的scopename
第三个程序:
with tf.name_scope("name1"):
with tf.variable_scope("var1"):w = tf.get_variable("w",shape=[2])
res = tf.add(w,[3]) print w.name
print res.name
# 输出var1/w:0name1/var1/Add:0可以看出:
· variable scope和name scope都会给op的name加上前缀
· 这实际上是因为创建 variable_scope 时内部会创建一个同名的 name_scope
对比三个个程序可以看出:
· name_scope 返回的是 string, 而 variable_scope 返回的是对象. 这也可以感觉到, variable_scope 能干的事情比 name_scope 要多.
· name_scope对 get_variable()创建的变量的名字不会有任何影响,而创建的op会被加上前缀.
· tf.get_variable_scope() 返回的只是 variable_scope,不管 name_scope. 所以以后我们在使用tf.get_variable_scope().reuse_variables()时可以无视name_scope
其它
with tf.name_scope("scope1") as scope1:
with tf.name_scope("scope2") as scope2:scope2
#输出:scope1/scope2/importtensorflowastf
with tf.variable_scope("scope1") as scope1:
with tf.variable_scope("scope2") as scope2: print scope2.name#输出:scope1/scope2name_scope可以用来干什么
典型的 TensorFlow 可以有数以千计的节点,如此多而难以一下全部看到,甚至无法使用标准图表工具来展示。为简单起见,我们为op/tensor名划定范围,并且可视化把该信息用于在图表中的节点上定义一个层级。默认情况下, 只有顶层节点会显示。下面这个例子使用tf.name_scope在hidden命名域下定义了三个操作:
importtensorflowastf
with tf.name_scope('hidden') as scope:
a = tf.constant(5, name='alpha') W = tf.Variable(tf.random_uniform([1, 2], -1.0, 1.0), name='weights') b = tf.Variable(tf.zeros([1]), name='biases') print a.name print W.name print b.name结果是得到了下面三个操作名:
hidden/alpha
hidden/weights
hidden/biases
name_scope 是给op_name加前缀,variable_scope是给get_variable()创建的变量的名字加前缀。
tf.variable_scope有时也会处理命名冲突
importtensorflowastf
def test(name=None): with tf.variable_scope(name, default_name="scope") as scope:w = tf.get_variable("w", shape=[2,10])
test()test()ws = tf.trainable_variables()forwinws:
print(w.name)#scope/w:0#scope_1/w:0#可以看出,如果只是使用default_name这个属性来创建variable_scope#的时候,会处理命名冲突其它
· tf.name_scope(None) 有清除name scope的作用
importtensorflowastf
with tf.name_scope("hehe"):
w1 = tf.Variable(1.0)
with tf.name_scope(None):w2 = tf.Variable(2.0)
print(w1.name)print(w2.name)#hehe/Variable:0#Variable:0总结
简单来看
1. 使用tf.Variable()的时候,tf.name_scope()和tf.variable_scope() 都会给 Variable 和 op 的 name属性加上前缀。
2. 使用tf.get_variable()的时候,tf.name_scope()就不会给 tf.get_variable()创建出来的Variable加前缀。但是 tf.Variable() 创建出来的就会受到 name_scope 的影响.
二十二、run_cell常用方法:
主要是神经网络cell中的内容:
Ø run_cell._linear()
def_linear(args,output_size, bias, bias_start=0.0, scope=None):
· args: list of tensor [batch_size, size]. 注意,list中的每个tensor的size 并不需要一定相同,但batch_size要保证一样.
· output_size : 一个整数
· bias: bool型, True表示加bias,False表示不加
· return : [batch_size, output_size]
注意: 这个函数的atgs 不能是 _ref 类型(tf_getvariable(), tf.Variables()返回的都是 _ref),但这个 _ref类型经过任何op之后,_ref就会消失
PS: _ref referente-typed is mutable
Ø rnn_cell.BasicLSTMCell()
classBasicLSTMCell(RNNCell):
def__init__(self,num_units, forget_bias=1.0,input_size=None,
state_is_tuple=True, activation=tanh):
“””
为什么被称为 Basic
It does not allow cell clipping, a projection layer, anddoes not
use peep-hole connections: it is the basic baseline.
“””
· num_units: lstm单元的output_size
· input_size: 这个参数没必要输入, 官方说马上也要禁用了
· state_is_tuple: True的话, (c_state,h_state)作为tuple返回
· activation: 激活函数
注意: 在我们创建 cell=BasicLSTMCell(…) 的时候, 只是初始化了cell的一些基本参数值. 这时,是没有variable被创建的, variable在我们 cell(input, state)时才会被创建, 下面所有的类都是这样
rnn_cell.GRUCell()
classGRUCell(RNNCell):
def__init__(self,num_units, input_size=None, activation=tanh):
创建一个GRUCell
rnn_cell.LSTMCell()
classLSTMCell(RNNCell):
def__init__(self,num_units, input_size=None,
use_peepholes=False, cell_clip=None,
initializer=None, num_proj=None, proj_clip=None,
num_unit_shards=1, num_proj_shards=1,
forget_bias=1.0, state_is_tuple=True,
activation=tanh):
· num_proj: python Innteger ,映射输出的size, 用了这个就不需要下面那个类了
rnn_cell.OutputProjectionWrapper()
classOutputProjectionWrapper(RNNCell):
def__init__(self,cell, output_size):
· output_size: 要映射的 size
· return: 返回一个带有 OutputProjection Layer的 cell(s)
rnn_cell.InputProjectionWrapper():
classInputProjectionWrapper(RNNCell):
def__init__(self,cell, num_proj, input_size=None):
· 和上面差不多,一个输出映射,一个输入映射
rnn_cell.DropoutWrapper()
classDropoutWrapper(RNNCell):
def__init__(self,cell, input_keep_prob=1.0,output_keep_prob=1.0,
seed=None):
· dropout
rnn_cell.EmbeddingWrapper():
classEmbeddingWrapper(RNNCell):
def__init__(self,cell, embedding_classes, embedding_size, initializer=None):
· 返回一个带有 embedding 的cell
rnn_cell.MultiRNNCell():
classMultiRNNCell(RNNCell):
def__init__(self,cells, state_is_tuple=True):
· 用来增加 rnn 的层数
· cells : list of cell
· 返回一个多层的 cell
二十三、tensorboard可视化:
tensorflow的可视化是使用summary和tensorboard合作完成的.
基本用法
首先明确一点,summary也是op.
输出网络结构
with tf.Session() as sess:
writer =tf.summary.FileWriter(your_dir, sess.graph)
命令行运行tensorboard–logdir your_dir,然后浏览器输入127.0.1.1:6006注:tf1.1.0 版本的tensorboard端口换了(0.0.0.0:6006)
这样你就可以在tensorboard中看到你的网络结构图了
可视化参数
#ops
loss = …
tf.summary.scalar(“loss”, loss)
merged_summary = tf.summary.merge_all()
init = tf.global_variable_initializer()
with tf.Session() as sess:
writer= tf.summary.FileWriter(your_dir, sess.graph)
sess.run(init)
for i in xrange(100):
_,summary =sess.run([train_op,merged_summary], feed_dict)
writer.add_summary(summary, i)
这时,打开tensorboard,在EVENTS可以看到loss随着i的变化了,如果看不到的话,可以在代码最后加上writer.flush()试一下,原因后面说明。
函数介绍
· tf.summary.merge_all: 将之前定义的所有summary op整合到一起
· FileWriter: 创建一个filewriter用来向硬盘写summary数据,
· tf.summary.scalar(summary_tags,Tensor/variable, collections=None): 用于标量的 summary
· tf.summary.image(tag, tensor, max_images=3,collections=None, name=None):tensor,必须4维,形状[batch_size, height, width, channels],max_images(最多只能生成3张图片的summary),觉着这个用在卷积中的kernel可视化很好用.max_images确定了生成的图片是[-max_images: ,height, width, channels],还有一点就是,TensorBord中看到的imagesummary永远是最后一个global step的
· tf.summary.histogram(tag, values,collections=None, name=None):values,任意形状的tensor,生成直方图summary
· tf.summary.audio(tag, tensor, sample_rate,max_outputs=3, collections=None, name=None)
解释collections参数:它是一个list,如果不指定collections, 那么此summary会被添加到f.GraphKeys.SUMMARIES中,如果指定了,就会放在的collections中。
FileWriter
注意:add_summary仅仅是向FileWriter对象的缓存中存放event data。而向disk上写数据是由FileWrite对象控制的。下面通过FileWriter的构造函数来介绍这一点!!!
tf.summary.FileWriter.__init__(logdir, graph=None, max_queue=10,flush_secs=120, graph_def=None)
Creates a FileWriter and an eventfile.
# max_queue: 在向disk写数据之前,最大能够缓存event的个数
# flush_secs: 每多少秒像disk中写数据,并清空对象缓存
注意
1. 如果使用writer.add_summary(summary,global_step)时没有传global_step参数,会使scarlar_summary变成一条直线。
2. 只要是在计算图上的Summary op,都会被merge_all捕捉到, 不需要考虑变量生命周期问题!
3. 如果执行一次,disk上没有保存Summary数据的话,可以尝试下file_writer.flush()
小技巧
如果想要生成的summary有层次的话,记得在summary外面加一个name_scope
with tf.name_scope(“summary_gradients”):
tf.summary.histgram(“name”, gradients)
这样,tensorboard在显示的时候,就会有一个sumary_gradients一级目录。
最近在研究tensorflow自带的例程speech_command,顺便学习tensorflow的一些基本用法。
其中tensorboard 作为一款可视化神器,可以说是学习tensorflow时模型训练以及参数可视化的法宝。
而在训练过程中,主要用到了tf.summary()的各类方法,能够保存训练过程以及参数分布图并在tensorboard显示。
tf.summary有诸多函数:
1、tf.summary.scalar
用来显示标量信息,其格式为:
tf.summary.scalar(tags, values, collections=None,name=None)
例如:tf.summary.scalar(‘mean’, mean)
一般在画loss,accuary时会用到这个函数。
2、tf.summary.histogram
用来显示直方图信息,其格式为:
tf.summary.histogram(tags, values, collections=None,name=None)
例如: tf.summary.histogram(‘histogram’,var)
一般用来显示训练过程中变量的分布情况
3、tf.summary.distribution
分布图,一般用于显示weights分布
4、tf.summary.text
可以将文本类型的数据转换为tensor写入summary中:
例如:
text =”””/a/b/c\\_d/f\\_g\\_h\\_2017″””
summary_op0 = tf.summary.text(‘text’,tf.convert_to_tensor(text))
5、tf.summary.image
输出带图像的probuf,汇总数据的图像的的形式如下: ‘ tag /image/0′,’ tag /image/1’…,如:input/image/0等。
格式:tf.summary.image(tag, tensor, max_images=3, collections=None, name=Non
6、tf.summary.audio
展示训练过程中记录的音频
7、tf.summary.merge_all
merge_all 可以将所有summary全部保存到磁盘,以便tensorboard显示。如果没有特殊要求,一般用这一句就可一显示训练时的各种信息了。
格式:tf.summaries.merge_all(key=’summaries’)
8、tf.summary.FileWriter
指定一个文件用来保存图。
格式:tf.summary.FileWritter(path,sess.graph)
可以调用其add_summary()方法将训练过程数据保存在filewriter指定的文件中
Tensorflow Summary 用法示例:
tf.summary.scalar(‘accuracy’,acc) #生成准确率标量图
merge_summary = tf.summary.merge_all()
train_writer = tf.summary.FileWriter(dir,sess.graph)#定义一个写入summary的目标文件,dir为写入文件地址
……(交叉熵、优化器等定义)
for step in xrange(training_step): #训练循环
train_summary =sess.run(merge_summary,feed_dict = {…})#调用sess.run运行图,生成一步的训练过程数据
train_writer.add_summary(train_summary,step)#调用train_writer的add_summary方法将训练过程以及训练步数保存
此时开启tensorborad:
tensorboard –logdir=/summary_dir
便能看见accuracy曲线了。
另外,如果我不想保存所有定义的summary信息,也可以用tf.summary.merge方法有选择性地保存信息:
9、tf.summary.merge
格式:tf.summary.merge(inputs, collections=None,name=None)
一般选择要保存的信息还需要用到tf.get_collection()函数
示例:
tf.summary.scalar(‘accuracy’,acc) #生成准确率标量图
merge_summary =tf.summary.merge([tf.get_collection(tf.GraphKeys.SUMMARIES,’accuracy’),…(其他要显示的信息)])
train_writer = tf.summary.FileWriter(dir,sess.graph)#定义一个写入summary的目标文件,dir为写入文件地址
……(交叉熵、优化器等定义)
for step in xrange(training_step): #训练循环
train_summary =sess.run(merge_summary,feed_dict = {…})#调用sess.run运行图,生成一步的训练过程数据
train_writer.add_summary(train_summary,step)#调用train_writer的add_summary方法将训练过程以及训练步数保存
使用tf.get_collection函数筛选图中summary信息中的accuracy信息,这里的
tf.GraphKeys.SUMMARIES 是summary在collection中的标志。
当然,也可以直接:
acc_summary = tf.summary.scalar(‘accuracy’,acc) #生成准确率标量图
merge_summary = tf.summary.merge([acc_summary ,…(其他要显示的信息)]) #这里的[]不可省
二十四、tensorflow configProto
tf.ConfigProto一般用在创建session的时候。用来对session进行参数配置
with tf.Session(config = tf.ConfigProto(…),…)
#tf.ConfigProto()的参数
log_device_placement=True : 是否打印设备分配日志
allow_soft_placement=True:如果你指定的设备不存在,允许TF自动分配设备
tf.ConfigProto(log_device_placement=True,allow_soft_placement=True)
Ø 控制GPU资源使用率
#allow growth
config = tf.ConfigProto()
config.gpu_options.allow_growth = True
session = tf.Session(config=config, …)
# 使用allow_growthoption,刚一开始分配少量的GPU容量,然后按需慢慢的增加,由于不会释放
#内存,所以会导致碎片
# per_process_gpu_memory_fraction
gpu_options=tf.GPUOptions(per_process_gpu_memory_fraction=0.7)
config=tf.ConfigProto(gpu_options=gpu_options)
session = tf.Session(config=config, …)
#设置每个GPU应该拿出多少容量给进程使用,0.4代表 40%
Ø 控制使用哪块GPU
~/ CUDA_VISIBLE_DEVICES=0 python your.py#使用GPU0
~/ CUDA_VISIBLE_DEVICES=0,1 pythonyour.py#使用GPU0,1
#注意单词不要打错
#或者在程序开头
os.environ[‘CUDA_VISIBLE_DEVICES’] = ‘0’#使用 GPU 0
os.environ[‘CUDA_VISIBLE_DEVICES’] = ‘0,1’# 使用 GPU 0,1
二十五、如何构建TF代码
batch_size: batch的大小
mini_batch: 将训练样本以batch_size分组
epoch_size: 样本分为几个min_batch
num_epoch : 训练几轮
读代码的时候应该关注的几部分
1. 如何处理数据
2. 如何构建计算图
3. 如何计算梯度
4. 如何Summary,如何save模型参数
5. 如何执行计算图
写一个将数据分成训练集,验证集和测试集的函数
train_set, valid_set, test_set = split_set(data)
最好写一个管理数据的对象,将原始数据转化成mini_batch
classDataManager(object):
#raw_data为train_set, valid_data或test_set
def__init__(self,raw_data, batch_size):
self.raw_data =raw_data
self.batch_size= batch_size
self.epoch_size= len(raw_data)/batch_size
self.counter = 0#监测batch index
defnext_batch(self):
…
self.counter +=1
return batched_x,batched_label, …
计算图的构建在Model类中的__init__()中完成,并设置is_training参数
优点:
1. 因为如果我们在训练的时候加dropout的话,那么在测试的时候是需要把这个dropout层去掉的。这样的话,在写代码的时候,你就可以创建两个对象。这就相当于建了两个模型,然后让这两个模型参数共享,就可以达到训练和测试一起运行的效果了。具体看下面代码。
classModel(object):
def__init__(self,is_training, config, scope,…):#scope可以使你正确的summary
self.is_training = is_training
self.config =config
#placeholder:用于feed数据
# 一个train op
self.graph(self.is_training) #构建图
self.merge_op =tf.summary.merge(tf.get_collection(tf.GraphKeys.SUMMARIES,scope))
defgraph(self,is_training):
…
#定义计算图
self.predict =…
self.loss = …
写个run_epoch函数
batch_size: batch的大小
mini_batch: 将训练样本以batch_size分组
epoch_size: 样本分为几个min_batch
num_epoch : 训练几轮
如何编写run_epoch函数
#eval_op是用来指定是否需要训练模型,需要的话,传入模型的eval_op
#draw_ata用于接收train_data,valid_data或test_data
defrun_epoch(raw_data ,session, model, is_training_set, …):
data_manager =DataManager(raw_data, model.config.batch_size)
#通过is_training_set来决定fetch哪些Tensor
#add_summary,saver.save(….)
如何组织main函数
1. 分解原始数据为train,valid,test
2. 设置默认图
3. 建图 trian, test 分别建图
4. 一个或多个Saver对象,用来保存模型参数
5. 创建session,初始化变量
6. 一个summary.FileWriter对象,用来将summary写入到硬盘中
7. run epoch
FileWriter 和 Saver对象,一个计算图只需要一个就够了,所以放在Model类的外面
附录
本篇博文总结下面代码写成, 有些地方和源码之间有不同。
下面是截取自官方代码:
classPTBInput(object):
“””Theinput data.”””
def__init__(self,config, data, name=None):
self.batch_size= batch_size = config.batch_size
self.num_steps= num_steps = config.num_steps
self.epoch_size= ((len(data) // batch_size) – 1) // num_steps
self.input_data, self.targets = reader.ptb_producer(
data,batch_size, num_steps, name=name)
classPTBModel(object):
“””ThePTB model.”””
def__init__(self,is_training, config, input_):
self._input =input_
batch_size =input_.batch_size
num_steps =input_.num_steps
size =config.hidden_size
vocab_size =config.vocab_size
# Slightlybetter results can be obtained with forget gate biases
#initialized to 1 but the hyperparameters of the model would need to be
# different than reported in thepaper.
lstm_cell =tf.contrib.rnn.BasicLSTMCell(
size,forget_bias=0.0, state_is_tuple=True)
if is_trainingand config.keep_prob < 1:
lstm_cell =tf.contrib.rnn.DropoutWrapper(
lstm_cell, output_keep_prob=config.keep_prob)
cell =tf.contrib.rnn.MultiRNNCell(
[lstm_cell]* config.num_layers, state_is_tuple=True)
self._initial_state = cell.zero_state(batch_size, data_type())
with tf.device(“/cpu:0”):
embedding =tf.get_variable(
“embedding”,[vocab_size, size], dtype=data_type())
inputs =tf.nn.embedding_lookup(embedding, input_.input_data)
if is_trainingand config.keep_prob < 1:
inputs =tf.nn.dropout(inputs, config.keep_prob)
#Simplified version of models/tutorials/rnn/rnn.py’s rnn().
# Thisbuilds an unrolled LSTM for tutorial purposes only.
# Ingeneral, use the rnn() or state_saving_rnn() from rnn.py.
#
# Thealternative version of the code below is:
#
# inputs =tf.unstack(inputs, num=num_steps, axis=1)
# outputs,state = tf.nn.rnn(cell, inputs,
# initial_state=self._initial_state)
outputs = []
state =self._initial_state
withtf.variable_scope(“RNN”):
for time_step inrange(num_steps):
if time_step> 0: tf.get_variable_scope().reuse_variables()
(cell_output, state) = cell(inputs[:, time_step, :], state)
outputs.append(cell_output)
output =tf.reshape(tf.concat_v2(outputs, 1), [-1, size])
softmax_w =tf.get_variable(
“softmax_w”, [size,vocab_size], dtype=data_type())
softmax_b =tf.get_variable(“softmax_b”, [vocab_size],dtype=data_type())
logits =tf.matmul(output, softmax_w) + softmax_b
loss =tf.contrib.legacy_seq2seq.sequence_loss_by_example(
[logits],
[tf.reshape(input_.targets, [-1])],
[tf.ones([batch_size * num_steps], dtype=data_type())])
self._cost =cost = tf.reduce_sum(loss) / batch_size
self._final_state = state
ifnotis_training:
return
self._lr =tf.Variable(0.0, trainable=False)
tvars =tf.trainable_variables()
grads, _ =tf.clip_by_global_norm(tf.gradients(cost, tvars),
config.max_grad_norm)
optimizer =tf.train.GradientDescentOptimizer(self._lr)
self._train_op= optimizer.apply_gradients(
zip(grads,tvars),
global_step=tf.contrib.framework.get_or_create_global_step())
self._new_lr =tf.placeholder(
tf.float32,shape=[], name=“new_learning_rate”)
self._lr_update= tf.assign(self._lr, self._new_lr)
defassign_lr(self,session, lr_value):
session.run(self._lr_update, feed_dict={self._new_lr: lr_value})
defrun_epoch(session,model, eval_op=None, verbose=False):
“””Runsthe model on the given data.”””
start_time =time.time()
costs = 0.0
iters = 0
state =session.run(model.initial_state)
fetches = {
“cost”:model.cost,
“final_state”:model.final_state,
}
if eval_op isnotNone:
fetches[“eval_op”] = eval_op
for step inrange(model.input.epoch_size):
feed_dict = {}
for i, (c, h) inenumerate(model.initial_state):
feed_dict[c]= state[i].c
feed_dict[h]= state[i].h
vals =session.run(fetches, feed_dict)
cost = vals[“cost”]
state = vals[“final_state”]
costs += cost
iters +=model.input.num_steps
if verbose and step %(model.input.epoch_size // 10) == 10:
print(“%.3fperplexity: %.3f speed: %.0f wps” %
(step *1.0 / model.input.epoch_size, np.exp(costs /iters),
iters* model.input.batch_size / (time.time() – start_time)))
returnnp.exp(costs / iters)
defmain(_):
ifnotFLAGS.data_path:
raise ValueError(“Mustset –data_path to PTB data directory”)
raw_data =reader.ptb_raw_data(FLAGS.data_path)
train_data,valid_data, test_data, _ = raw_data
config =get_config()
eval_config =get_config()
eval_config.batch_size = 1
eval_config.num_steps = 1
withtf.Graph().as_default():
initializer =tf.random_uniform_initializer(-config.init_scale,
config.init_scale)
withtf.name_scope(“Train”):
train_input =PTBInput(config=config, data=train_data, name=“TrainInput”)
withtf.variable_scope(“Model”, reuse=None,initializer=initializer):
m =PTBModel(is_training=True, config=config,input_=train_input)
tf.contrib.deprecated.scalar_summary(“TrainingLoss”, m.cost)
tf.contrib.deprecated.scalar_summary(“LearningRate”, m.lr)
withtf.name_scope(“Valid”):
valid_input =PTBInput(config=config, data=valid_data, name=“ValidInput”)
withtf.variable_scope(“Model”, reuse=True,initializer=initializer):
mvalid =PTBModel(is_training=False,config=config, input_=valid_input)
tf.contrib.deprecated.scalar_summary(“ValidationLoss”, mvalid.cost)
withtf.name_scope(“Test”):
test_input =PTBInput(config=eval_config, data=test_data, name=“TestInput”)
withtf.variable_scope(“Model”, reuse=True,initializer=initializer):
mtest =PTBModel(is_training=False,config=eval_config,
input_=test_input)
sv =tf.train.Supervisor(logdir=FLAGS.save_path)
withsv.managed_session() as session:
for i inrange(config.max_max_epoch):
lr_decay =config.lr_decay ** max(i + 1 – config.max_epoch, 0.0)
m.assign_lr(session, config.learning_rate * lr_decay)
print(“Epoch:%d Learning rate: %.3f” % (i + 1,session.run(m.lr)))
train_perplexity = run_epoch(session, m, eval_op=m.train_op,
verbose=True)
print(“Epoch:%d Train Perplexity: %.3f” % (i + 1,train_perplexity))
valid_perplexity = run_epoch(session, mvalid)
print(“Epoch:%d Valid Perplexity: %.3f” % (i + 1,valid_perplexity))
test_perplexity = run_epoch(session, mtest)
print(“TestPerplexity: %.3f” % test_perplexity)
ifFLAGS.save_path:
print(“Savingmodel to %s.” % FLAGS.save_path)
sv.saver.save(session, FLAGS.save_path, global_step=sv.global_step)
if __name__ == “__main__”:
tf.app.run()
二十六、collection全局存储
tensorflow的collection提供一个全局的存储机制,不会受到变量名生存空间的影响。一处保存,到处可取。
接口介绍
#向collection中存数据
tf.Graph.add_to_collection(name, value)
#Stores value in the collection with the given name.
#Note that collections are not sets, so it is possible toadd a value to a collection
#several times.
# 注意,一个‘name’下,可以存很多值; add_to_collection(“haha”,[a,b]),这种情况下
#tf.get_collection(“haha”)获得的是 [[a,b]], 并不是[a,b]
tf.add_to_collection(name, value)
#这个和上面函数功能上没有区别,区别是,这个函数是给默认图使用的
#从collection中获取数据
tf.Graph.get_collection(name, scope=None)
二十七、merge_all的应用
不要用merge_all而是用merge。
1. 在训练深度神经网络的时候,我们经常会使用Dropout,然而在test的时候,需要把dropout撤掉.为了应对这种问题,我们通常要建立两个模型,让他们共享变量。详情.也可以通过设置 train_flag, 这里只讨论第一个方法可能会碰到的问题.
2. 为了使用Tensorboard来可视化我们的数据,我们会经常使用Summary,最终都会用一个简单的merge_all函数来管理我们的Summary
错误示例
当这两种情况相遇时,bug就产生了,看代码:
importtensorflowastf
importnumpyasnp
class Model(object): def __init__(self): self.graph() self.merged_summary = tf.summary.merge_all()# 引起血案的地方 def graph(self): self.x = tf.placeholder(dtype=tf.float32,shape=[None,1]) self.label = tf.placeholder(dtype=tf.float32, shape=[None,1])w = tf.get_variable("w",shape=[1,1])
self.predict = tf.matmul(self.x,w) self.loss = tf.reduce_mean(tf.reduce_sum(tf.square(self.label-self.predict),axis=1)) self.train_op = tf.train.GradientDescentOptimizer(0.01).minimize(self.loss) tf.summary.scalar("loss",self.loss)def run_epoch(session, model): x = np.random.rand(1000).reshape(-1,1) label = x*3 feed_dic = {model.x.name:x, model.label:label} su = session.run([model.merged_summary], feed_dic)def main(): with tf.Graph().as_default(): with tf.name_scope("train"): with tf.variable_scope("var1",dtype=tf.float32): model1 = Model() with tf.name_scope("test"): with tf.variable_scope("var1",reuse=True,dtype=tf.float32): model2 = Model() with tf.Session() as sess: tf.global_variables_initializer().run() run_epoch(sess,model1) run_epoch(sess,model2)if__name__ =="__main__":
main()运行情况是这样的: 执行run_epoch(sess,model1)时候,程序并不会报错,一旦执行到run_epoch(sess,model2),就会报错(错误信息见文章最后)。
错误原因
看代码片段:
class Model(object): def __init__(self): self.graph() self.merged_summary = tf.summary.merge_all()# 引起血案的地方...with tf.name_scope("train"):
with tf.variable_scope("var1",dtype=tf.float32): model1 = Model() # 这里的merge_all只是管理了自己的summarywith tf.name_scope("test"):
with tf.variable_scope("var1",reuse=True,dtype=tf.float32): model2 = Model()# 这里的merge_all管理了自己的summary和上边模型的Summary由于Summary的计算是需要feed数据的,所以会报错。
解决方法
我们只需要替换掉merge_all就可以解决这个问题。看代码
class Model(object): def __init__(self,scope): self.graph() self.merged_summary = tf.summary.merge( tf.get_collection(tf.GraphKeys.SUMMARIES,scope) )...with tf.Graph().as_default():
with tf.name_scope("train") as train_scope: with tf.variable_scope("var1",dtype=tf.float32): model1 = Model(train_scope) with tf.name_scope("test") as test_scope: with tf.variable_scope("var1",reuse=True,dtype=tf.float32): model2 = Model(test_scope)关于tf.get_collection地址
当有多个模型时,出现类似错误,应该考虑使用的方法是不是涉及到了其他的模型
error
tensorflow.python.framework.errors_impl.InvalidArgumentError:You must feed a value for placeholder tensor ‘train/var1/Placeholder’ withdtype float
[Node:train/var1/Placeholder = Placeholder[dtype=DT_FLOAT, shape=[],_device=”/job:localhost/replica:0/task:0/gpu:0”]]
二十八、tf.gradients 与 tf.stop_gradient() 与 高阶导数
Ø gradient
tensorflow中有一个计算梯度的函数tf.gradients(ys,xs),要注意的是,xs中的x必须要与ys相关,不相关的话,会报错。
代码中定义了两个变量w1, w2, 但res只与w1相关
#wrong
import tensorflow as tf
w1 = tf.Variable([[1,2]])
w2 = tf.Variable([[3,4]])
res = tf.matmul(w1, [[2],[1]])
grads = tf.gradients(res,[w1,w2])
with tf.Session() as sess:
tf.global_variables_initializer().run()
re =sess.run(grads)
print(re)
错误信息
TypeError: Fetch argument None has invalid type
# right
import tensorflow as tf
w1 = tf.Variable([[1,2]])
w2 = tf.Variable([[3,4]])
res = tf.matmul(w1, [[2],[1]])
grads = tf.gradients(res,[w1])
with tf.Session() as sess:
tf.global_variables_initializer().run()
re =sess.run(grads)
print(re)
# [array([[2, 1]],dtype=int32)]
对于grad_ys的测试:
import tensorflow as tf
w1 = tf.get_variable(‘w1’, shape=[3])
w2 = tf.get_variable(‘w2’, shape=[3])
w3 = tf.get_variable(‘w3’, shape=[3])
w4 = tf.get_variable(‘w4’, shape=[3])
z1 = w1 + w2+ w3
z2 = w3 + w4
grads = tf.gradients([z1, z2], [w1, w2, w3, w4],grad_ys=[tf.convert_to_tensor([2.,2.,3.]),
tf.convert_to_tensor([3.,2.,4.])])
with tf.Session() as sess:
tf.global_variables_initializer().run()
print(sess.run(grads))
[array([ 2., 2., 3.],dtype=float32),
array([ 2., 2., 3.],dtype=float32),
array([ 5., 4., 7.],dtype=float32),
array([ 3., 2., 4.],dtype=float32)]
Ø tf.stop_gradient()
阻挡节点BP的梯度
import tensorflow as tf
w1 = tf.Variable(2.0)
w2 = tf.Variable(2.0)
a = tf.multiply(w1, 3.0)
a_stoped = tf.stop_gradient(a)
# b=w1*3.0*w2
b = tf.multiply(a_stoped, w2)
gradients = tf.gradients(b, xs=[w1, w2])
print(gradients)
#输出
#[None, <tf.Tensor ‘gradients/Mul_1_grad/Reshape_1:0’shape=() dtype=float32>]
可见,一个节点被 stop之后,这个节点上的梯度,就无法再向前BP了。由于w1变量的梯度只能来自a节点,所以,计算梯度返回的是None。
a = tf.Variable(1.0)
b = tf.Variable(1.0)
c = tf.add(a, b)
c_stoped = tf.stop_gradient(c)
d = tf.add(a, b)
e = tf.add(c_stoped, d)
gradients = tf.gradients(e, xs=[a, b])
with tf.Session() as sess:
tf.global_variables_initializer().run()
print(sess.run(gradients))
#输出 [1.0, 1.0]
虽然 c节点被stop了,但是a,b还有从d传回的梯度,所以还是可以输出梯度值的。
import tensorflow as tf
w1 = tf.Variable(2.0)
w2 = tf.Variable(2.0)
a = tf.multiply(w1, 3.0)
a_stoped = tf.stop_gradient(a)
# b=w1*3.0*w2
b = tf.multiply(a_stoped, w2)
opt = tf.train.GradientDescentOptimizer(0.1)
gradients = tf.gradients(b, xs=tf.trainable_variables())
tf.summary.histogram(gradients[0].name,gradients[0])# 这里会报错,因为gradients[0]是None
#其它地方都会运行正常,无论是梯度的计算还是变量的更新。总觉着tensorflow这么设计有点不好,
#不如改成流过去的梯度为0
train_op = opt.apply_gradients(zip(gradients,tf.trainable_variables()))
print(gradients)
with tf.Session() as sess:
tf.global_variables_initializer().run()
print(sess.run(train_op))
print(sess.run([w1, w2]))
Ø 高阶导数
tensorflow 求 高阶导数可以使用 tf.gradients 来实现
import tensorflow as tf
with tf.device(‘/cpu:0’):
a =tf.constant(1.)
b = tf.pow(a, 2)
grad =tf.gradients(ys=b, xs=a) # 一阶导
print(grad[0])
grad_2 =tf.gradients(ys=grad[0], xs=a) # 二阶导
grad_3 =tf.gradients(ys=grad_2[0], xs=a) # 三阶导
print(grad_3)
with tf.Session() as sess:
print(sess.run(grad_3))
Note: 有些 op,tf 没有实现其高阶导的计算,例如 tf.add …, 如果计算了一个没有实现 高阶导的 op的高阶导, gradients 会返回 None。









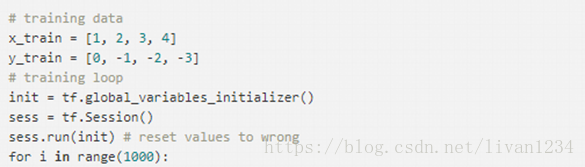
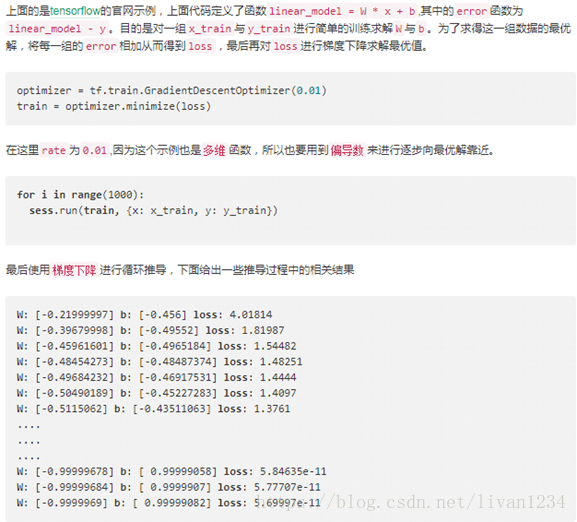

二十九、构建多GPU代码
结构
1. 先构建单GPU代码
2. 写个函数multi_gpu_model(num_gpus)来生成多GPU代码,并将对象保存在collection中
3. feed data
4. run
如何构建单GPU代码
见之前博客构建TF代码
不要在单GPU代码中创建optimizerop,因为是multi gpu,所以参数更新的操作是所有的GPU计算完梯度之后,才进行更新的。
如何实现multi_gpu_model函数
def multi_gpu_model(num_gpus=1): grads = [] for i in range(num_gpus): with tf.device("/gpu:%d"%i): with tf.name_scope("tower_%d"%i): model = Model(is_training, config, scope) # 放到collection中,方便feed的时候取 tf.add_to_collection("train_model", model) grads.append(model.grad) #grad 是通过tf.gradients(loss, vars)求得 #以下这些add_to_collection可以直接在模型内部完成。 # 将loss放到 collection中, 方便以后操作 tf.add_to_collection("loss",model.loss) #将predict放到collection中,方便操作 tf.add_to_collection("predict", model.predict) #将 summary.merge op放到collection中,方便操作 tf.add_to_collection("merge_summary", model.merge_summary) # ... with tf.device("cpu:0"): averaged_gradients = average_gradients(grads)# average_gradients后面说明 opt = tf.train.GradientDescentOptimizer(learning_rate) train_op=opt.apply_gradients(zip(average_gradients,tf.trainable_variables())) returntrain_op
如何feed data
def generate_feed_dic(model, feed_dict, batch_generator): x, y = batch_generator.next_batch() feed_dict[model.x] = x feed_dict[model.y] = y如何实现run_epoch
#这里的scope是用来区别 train 还是 testdef run_epoch(session, data_set, scope, train_op=None, is_training=True): batch_generator = BatchGenerator(data_set, batch_size) ... ...ifis_trainingandtrain_opisnotNone:
models = tf.get_collection("train_model")
# 生成 feed_dict feed_dic = {}formodelinmodels:
generate_feed_dic(model, feed_dic, batch_generator) #生成fetch_dictlosses = tf.get_collection("loss", scope)#保证了在 test的时候,不会fetch train的loss
... ...main函数
main函数干了以下几件事:
1. 数据处理
2. 建立多GPU训练模型
3. 建立单/多GPU测试模型
4. 创建Saver对象和FileWriter对象
5. 创建session
6. run_epoch
data_process()with tf.name_scope("train") as train_scope:
train_op = multi_gpu_model(..)with tf.name_scope("test") as test_scope:
model = Model(...)saver = tf.train.Saver()# 建图完毕,开始执行运算with tf.Session() as sess:
writer = tf.summary.FileWriter(...) ... run_epoch(...,train_scope) run_epoch(...,test_scope)如何编写average_gradients函数
def average_gradients(grads):#grads:[[grad0, grad1,..], [grad0,grad1,..]..] averaged_grads = [] for grads_per_var in zip(*grads): grads = []forgradingrads_per_var:
expanded_grad = tf.expanded_dim(grad,0)
grads.append(expanded_grad)grads = tf.concat_v2(grads,0)
grads = tf.reduce_mean(grads,0)
averaged_grads.append(grads) returnaveraged_grads
还有一个版本,但是不work,不知为啥
def average_gradients(grads):#grads:[[grad0, grad1,..], [grad0,grad1,..]..] averaged_grads = [] for grads_per_var in zip(*grads):grads = tf.reduce_mean(grads_per_var,0)
averaged_grads.append(grads)returnaveraged_grads
三十、deconv解卷积
deconv解卷积,实际是叫做conv_transpose, conv_transpose实际是卷积的一个逆向过程,tf 中, 编写conv_transpose代码的时候,心中想着一个正向的卷积过程会很有帮助。
想象一下我们有一个正向卷积:
input_shape = [1,5,5,3]
kernel_shape=[2,2,3,1]
strides=[1,2,2,1]
padding = “SAME”
那么,卷积激活后,我们会得到 x(就是上面代码的x)。那么,我们已知x,要想得到input_shape 形状的 tensor,我们应该如何使用conv2d_transpose函数呢?
就用下面的代码
import tensorflow as tf
tf.set_random_seed(1)
x = tf.random_normal(shape=[1,3,3,1])
#正向卷积的kernel的模样
kernel = tf.random_normal(shape=[2,2,3,1])
# strides 和padding也是假想中正向卷积的模样。当然,x是正向卷积后的模样
y = tf.nn.conv2d_transpose(x,kernel,output_shape=[1,5,5,3],
strides=[1,2,2,1],padding=“SAME”)
# 在这里,output_shape=[1,6,6,3]也可以,考虑正向过程,[1,6,6,3]
# 通过kernel_shape:[2,2,3,1],strides:[1,2,2,1]也可以
# 获得x_shape:[1,3,3,1]
# output_shape 也可以是一个 tensor
sess = tf.Session()
tf.global_variables_initializer().run(session=sess)
print(y.eval(session=sess))
conv2d_transpose 中会计算 output_shape 能否通过给定的参数计算出 inputs的维度,如果不能,则报错
import tensorflow as tf
from tensorflow.contrib import slim
inputs = tf.random_normal(shape=[3, 97, 97, 10])
conv1 = slim.conv2d(inputs, num_outputs=20,kernel_size=3, stride=4)
de_weight = tf.get_variable(‘de_weight’, shape=[3, 3, 10, 20])
deconv1 = tf.nn.conv2d_transpose(conv1, filter=de_weight,output_shape=tf.shape(inputs),
strides=[1, 3, 3, 1], padding=‘SAME’)
# ValueError: Shapes (3, 33, 33, 20) and (3, 25, 25, 20)are not compatible
上面错误的意思是:
· conv1 的 shape 是 (3, 25, 25, 20)
· 但是 deconv1 对 conv1 求导的时候,得到的导数 shape 却是 [3, 33, 33, 20],这个和 conv1 的shape 不匹配,当然要报错咯。
import tensorflow as tf
from tensorflow.contrib import slim
import numpy as np
inputs = tf.placeholder(tf.float32, shape=[None, None, None, 3])
conv1 = slim.conv2d(inputs, num_outputs=20,kernel_size=3, stride=4)
de_weight = tf.get_variable(‘de_weight’, shape=[3, 3, 3, 20])
deconv1 = tf.nn.conv2d_transpose(conv1, filter=de_weight,output_shape=tf.shape(inputs),
strides=[1, 3, 3, 1], padding=‘SAME’)
loss = deconv1 – inputs
train_op = tf.train.GradientDescentOptimizer(0.001).minimize(loss)
with tf.Session() as sess:
tf.global_variables_initializer().run()
for i in range(10):
data_in =np.random.normal(size=[3, 97, 97, 3])
_, los_ =sess.run([train_op, loss], feed_dict={inputs: data_in})
print(los_)
# InvalidArgumentError (see above for traceback):Conv2DSlowBackpropInput: Size of out_backprop doesn’t match computed: actual =25, computed = 33
如果 输入的 shape 有好多 None 的话,那就是另外一种 报错方式了,如上所示:
这个错误的意思是:
· conv1 的 shape 第二维或第三维的 shape 是 25
· 但是 deconv1 对 conv1 求导的时候,得到的倒数 shape 的第二位或第三维却是 33
至于为什么会这样,因为 deconv 的计算方式就是 conv 求导的计算方式,conv 的计算方式,就是 decov 求导的方式。
对deconv 求导就相当于 拿着 conv_transpose 中的参数对 deconv 输出的值的导数做卷积。
如何灵活的控制 deconv 的output shape
在 conv2d_transpose() 中,有一个参数,叫 output_shape, 如果对它传入一个 int list 的话,那么在运行的过程中,output_shape 将无法改变(传入int list已经可以满足大部分应用的需要),但是如何更灵活的控制 output_shape 呢?
· 传入 tensor
# 可以用 placeholder
outputs_shape = tf.placeholder(dtype=tf.int32, shape=[4])
deconv1 = tf.nn.conv2d_transpose(conv1, filter=de_weight,output_shape=output_shape,
strides=[1, 3, 3, 1], padding=‘SAME’)
# 可以用 inputs 的shape,但是有点改变
inputs_shape = tf.shape(inputs)
outputs_shape = [inputs_shape[0],inputs_shape[1], inputs_shape[2],some_value]
deconv1 = tf.nn.conv2d_transpose(conv1, filter=de_weight,output_shape=outputs_shape,
strides=[1, 3, 3, 1], padding=‘SAME’)
三十一、ExponentialMovingAverage(指数移动平滑)
ExponentialMovingAverage
Sometraining algorithms, such as GradientDescent and Momentum often benefit frommaintaining a moving average of variables during optimization. Using the movingaverages for evaluations often improve results significantly.
tensorflow 官网上对于这个方法功能的介绍。GradientDescent 和 Momentum 方式的训练 都能够从 ExponentialMovingAverage 方法中获益。
什么是MovingAverage?
假设我们与一串时间序列
{a1,a2,a3,…,at−1,at,…}{a1,a2,a3,…,at−1,at,…}
,那么,这串时间序列的 MovingAverage 就是:
mvt=decay∗mvt−1+(1−decay)∗atmvt=decay∗mvt−1+(1−decay)∗at
这是一个递归表达式。
如何理解这个式子呢?
他就像一个滑动窗口,mvtmvt 的值只和这个窗口内的 aiai 有关,为什么这么说呢?将递归式拆开 :
mvtmvt−1mvt−2=(1−decay)∗at+decay∗mvt−1=(1−decay)∗at−1+decay∗mvt−2=(1−decay)∗at−2+decay∗mvt−3…mvt=(1−decay)∗at+decay∗mvt−1mvt−1=(1−decay)∗at−1+decay∗mvt−2mvt−2=(1−decay)∗at−2+decay∗mvt−3…
得到:
mvt=∑i=1tdecayt−i∗(1−decay)∗aimvt=∑i=1tdecayt−i∗(1−decay)∗ai
当 t−i>Ct−i>C, CC 为某足够大的数时
decayt−i∗(1−decay)∗ai≈0decayt−i∗(1−decay)∗ai≈0
, 所以:
mvt≈∑i=t−Ctdecayt−i∗(1−decay)∗aimvt≈∑i=t−Ctdecayt−i∗(1−decay)∗ai
。即, mvtmvt 的值只和 {at−C,…,at}{at−C,…,at} 有关。
tensorflow中的ExponentialMovingAverage
这时,再看官方文档中的公式:
shadowVariable=decay∗shadowVariable+(1−decay)∗variableshadowVariable=decay∗shadowVariable+(1−decay)∗variable
,就知道各代表什么意思了。
shadowvariables are created with trainable=False。用其来存放 ema 的值
importtensorflowastf
w = tf.Variable(1.0)
ema = tf.train.ExponentialMovingAverage(0.9)
update = tf.assign_add(w, 1.0)with tf.control_dependencies([update]):
#返回一个op,这个op用来更新moving_average,i.e. shadow value ema_op = ema.apply([w])#这句和下面那句不能调换顺序# 以 w 当作 key, 获取 shadow value 的值ema_val = ema.average(w)#参数不能是list,有点蛋疼with tf.Session() as sess:
tf.global_variables_initializer().run() for i in range(3): sess.run(ema_op) print(sess.run(ema_val))# 创建一个时间序列 1 2 3 4#输出:#1.1 =0.9*1 + 0.1*2#1.29 =0.9*1.1+0.1*3#1.561 =0.9*1.29+0.1*4你可能会奇怪,明明 只执行三次循环, 为什么产生了 4 个数?
这是因为,当程序执行到 ema_op = ema.apply([w]) 的时候,如果 w 是 Variable, 那么将会用 w 的初始值初始化 ema 中关于 w 的 ema_value,所以 emaVal0=1.0emaVal0=1.0。如果 w 是 Tensor的话,将会用 0.0 初始化。
官网中的示例:
# Create variables.var0 = tf.Variable(...)var1 = tf.Variable(...)# ... use the variables to build a training model......# Create an op that applies the optimizer. This is what we usually# would use as a training op.opt_op = opt.minimize(my_loss, [var0, var1])# Create an ExponentialMovingAverage objectema = tf.train.ExponentialMovingAverage(decay=0.9999)
# Create the shadow variables, and add ops to maintain moving averages# of var0 and var1.maintain_averages_op = ema.apply([var0, var1])# Create an op that will update the moving averages after each training# step. This is what we will use in place of the usual training op.with tf.control_dependencies([opt_op]):
training_op = tf.group(maintain_averages_op) # run这个op获取当前时刻 ema_value get_var0_average_op = ema.average(var0)使用 ExponentialMovingAveraged parameters
假设我们使用了ExponentialMovingAverage方法训练了神经网络, 在test阶段,如何使用 ExponentialMovingAveraged parameters呢? 官网也给出了答案
方法一:
# Create a Saver that loads variables from their saved shadow values.shadow_var0_name = ema.average_name(var0)shadow_var1_name = ema.average_name(var1)saver = tf.train.Saver({shadow_var0_name: var0, shadow_var1_name: var1})saver.restore(...checkpoint filename...)# var0 and var1 now hold the moving average values方法二:
#Returns a map of names to Variables to restore.variables_to_restore = ema.variables_to_restore()saver = tf.train.Saver(variables_to_restore)...saver.restore(...checkpoint filename...)这里要注意的一个问题是,用于保存的saver可不能这么写,参考 http://blog.csdn.net/u012436149/article/details/56665612
三十二、保存与加载模型(saver)
Saver
tensorflow 中的 Saver 对象是用于 参数保存和恢复的。如何使用呢?
这里介绍了一些基本的用法。
官网中给出了这么一个例子:
v1 = tf.Variable(..., name='v1')v2 = tf.Variable(..., name='v2')# Pass the variables as a dict:saver = tf.train.Saver({'v1': v1,'v2': v2})
# Or pass them as a list.saver = tf.train.Saver([v1, v2])# Passing a list is equivalent to passing a dict with the variable op names# as keys:saver = tf.train.Saver({v.op.name: v for v in [v1, v2]})#注意,如果不给Saver传var_list 参数的话, 他将已 所有可以保存的 variable作为其var_list的值。这里使用了三种不同的方式来创建 saver 对象, 但是它们内部的原理是一样的。我们都知道,参数会保存到 checkpoint 文件中,通过键值对的形式在 checkpoint中存放着。如果 Saver 的构造函数中传的是 dict,那么在 save 的时候,checkpoint文件中存放的就是对应的 key-value。如下:
importtensorflowastf
# Create some variables.v1 = tf.Variable(1.0, name="v1")v2 = tf.Variable(2.0, name="v2")saver = tf.train.Saver({"variable_1":v1, "variable_2": v2})# Use the saver object normally after that.with tf.Session() as sess:
tf.global_variables_initializer().run() saver.save(sess, 'test-ckpt/model-2')我们通过官方提供的工具来看一下 checkpoint 中保存了什么
from tensorflow.python.tools.inspect_checkpoint import print_tensors_in_checkpoint_file
print_tensors_in_checkpoint_file("test-ckpt/model-2",None,True)
# 输出:#tensor_name: variable_1#1.0#tensor_name: variable_2#2.0如果构建saver对象的时候,我们传入的是 list, 那么将会用对应 Variable 的 variable.op.name 作为 key。
importtensorflowastf
# Create some variables.v1 = tf.Variable(1.0, name="v1")v2 = tf.Variable(2.0, name="v2")saver = tf.train.Saver([v1, v2])# Use the saver object normally after that.with tf.Session() as sess:
tf.global_variables_initializer().run() saver.save(sess, 'test-ckpt/model-2')我们再使用官方工具打印出 checkpoint 中的数据,得到
tensor_name: v11.0tensor_name: v22.0如果我们现在想将 checkpoint 中v2的值restore到v1 中,v1的值restore到v2中,我们该怎么做?
这时,我们只能采用基于 dict 的 saver
importtensorflowastf
# Create some variables.v1 = tf.Variable(1.0, name="v1")v2 = tf.Variable(2.0, name="v2")saver = tf.train.Saver({"variable_1":v1, "variable_2": v2})# Use the saver object normally after that.with tf.Session() as sess:
tf.global_variables_initializer().run() saver.save(sess, 'test-ckpt/model-2')save 部分的代码如上所示,下面写 restore 的代码,和save代码有点不同。
```pythonimporttensorflowastf
# Create some variables.v1 = tf.Variable(1.0, name="v1")v2 = tf.Variable(2.0, name="v2")#restore的时候,variable_1对应到v2,variable_2对应到v1,就可以实现目的了。saver = tf.train.Saver({"variable_1":v2, "variable_2": v1})# Use the saver object normally after that.with tf.Session() as sess:
tf.global_variables_initializer().run() saver.restore(sess, 'test-ckpt/model-2') print(sess.run(v1), sess.run(v2))# 输出的结果是 2.0 1.0,如我们所望我们发现,其实 创建 saver对象时使用的键值对就是表达了一种对应关系:
· save时,表示:variable的值应该保存到 checkpoint文件中的哪个 key下
· restore时,表示:checkpoint文件中key对应的值,应该restore到哪个variable
其它
一个快速找到ckpt文件的方式
ckpt = tf.train.get_checkpoint_state(ckpt_dir)if ckpt and ckpt.model_checkpoint_path:
saver.restore(sess, ckpt.model_checkpoint_path)三十三、control flow(控制流):
由于tensorflow使用的是graph的计算概念,在没有涉及控制数据流向的时候编程和普通编程语言的编程差别不大,但是涉及到控制数据流向的操作时,就要特别小心,不然很容易出错。这也是TensorFlow比较反直觉的地方。
在TensorFlow中,tf.cond()类似于c语言中的if…else…,用来控制数据流向,但是仅仅类似而已,其中差别还是挺大的。
tf.cond(pred, fn1, fn2,name=None)
等价于:
res = fn1()ifpredelsefn2()
注意:pred不能是 python bool, pred是个标量Tensori.e. tf.placeholder(dtype=tf.bool,shape=[])
官网例子
z = tf.mul(a, b)result = tf.cond(x < y, lambda: tf.add(x, z), lambda: tf.square(y))tf.case(pred_fn_pairs,default, exclusive=False, name=’case’)
pred_fn_pairs:以下两种形式都是正确的
1. [(pred_1, fn_1), (pred_2, fn_2)]
2. {pred_1:fn_1, pred_2:fn_2}
tf.case()等价于:
if pred_1:
returnfn_1()
elif pred_2:
returnfn_2()
else:
return default()· exclusive: 如果为True,那么pred至多有一个为True,如果有多余一个,会报错。如果False,则不会检查所有条件。
importtensorflowastf
x = tf.constant(0)
y = tf.constant(1)
z = tf.constant(2)
def f1(): return tf.constant(17)
def f2(): return tf.constant(23)
def f3(): return tf.constant(-1)
r = tf.case({tf.less(x, y): f2, tf.less(x, z): f1}, default=f3, exclusive=False)with tf.Session() as sess:
tf.global_variables_initializer().run() print(sess.run(r))tf.group()与 tf.tuple()
如果我们有很多 tensor 或 op想要一起run,这时这两个函数就是一个很好的帮手了。
w = tf.Variable(1)
mul = tf.multiply(w,2)
add = tf.add(w, 2)group = tf.group(mul, add)tuple = tf.tuple([mul, add])# sess.run(group)和sess.run(tuple)都会求Tensor(add)#Tensor(mul)的值。区别是,tf.group()返回的是`op`#tf.tuple()返回的是list of tensor。#这样就会导致,sess.run(tuple)的时候,会返回 Tensor(mul),Tensor(add)的值.#而 sess.run(group)不会tf.identity()
http://stackoverflow.com/questions/34877523/in-tensorflow-what-is-tf-identity-used-for
tf.while_loop()
tf.while_loop(cond, body, loop_vars,shape_invariants=None, parallel_iterations=10, back_prop=True,swap_memory=False, name=None)
while_loop可以这么理解
loop_vars = [...]while cond(*loop_vars):
loop_vars = body(*loop_vars) 示例:
importtensorflowastf
a = tf.get_variable("a", dtype=tf.int32, shape=[], initializer=tf.ones_initializer())b = tf.constant(2)
f = tf.constant(6)
# Definition of condition and bodydef cond(a, b, f):returna <3
def body(a, b, f): # do some stuff with a, b a = a + 1returna, b, f
# Loop, 返回的tensor while 循环后的 a,b,f;[a,b,f]是返回值。a, b, f = tf.while_loop(cond, body, [a, b, f])with tf.Session() as sess:
tf.global_variables_initializer().run() res = sess.run([a, b, f]) print(res)三十四、学习退化率:
learning rate decay
在训练神经网络的时候,通常在训练刚开始的时候使用较大的learningrate, 随着训练的进行,我们会慢慢的减小learningrate。对于这种常用的训练策略,tensorflow 也提供了相应的API让我们可以更简单的将这个方法应用到我们训练网络的过程中。
在Tensorflow中,为解决设定学习率(learning rate)问题,提供了指数衰减法来解决。
通过tf.train.exponential_decay函数实现指数衰减学习率。
步骤:1.首先使用较大学习率(目的:为快速得到一个比较优的解);
2.然后通过迭代逐步减小学习率(目的:为使模型在训练后期更加稳定);
代码实现:
[html] view plain copy
1. decayed_learning_rate=learining_rate*decay_rate^(global_step/decay_steps)
其中,decayed_learning_rate为每一轮优化时使用的学习率;
learning_rate为事先设定的初始学习率;
decay_rate为衰减系数;
decay_steps为衰减速度。
而tf.train.exponential_decay函数则可以通过staircase(默认值为False,当为True时,(global_step/decay_steps)则被转化为整数) ,选择不同的衰减方式。
代码示例:
[html] view plain copy
1. global_step = tf.Variable(0)
2.
3. learning_rate = tf.train.exponential_decay(0.1, global_step, 100, 0.96, staircase=True) #生成学习率
4.
5. learning_step = tf.train.GradientDescentOptimizer(learning_rate).minimize(….., global_step=global_step) #使用指数衰减学习率
learning_rate:0.1;staircase=True;则每100轮训练后要乘以0.96.
通常初始学习率,衰减系数,衰减速度的设定具有主观性(即经验设置),而损失函数下降的速度与迭代结束之后损失的大小没有必然联系,
所以神经网络的效果不能单一的通过前几轮损失函数的下降速度来比较。
接口
tf.train.exponential_decay(learning_rate, global_step,decay_steps, decay_rate, staircase=False, name=None)
参数:
learning_rate : 初始的learning rate
global_step : 全局的step,与 decay_step 和 decay_rate一起决定了 learning rate的变化。
staircase : 如果为 True global_step/decay_step 向下取整
更新公式:
decayed_learning_rate = learning_rate *
decay_rate ^ (global_step / decay_steps)
这个代码可以看一下 learning_rate 的变化趋势:
import tensorflow as tf
global_step = tf.Variable(0, trainable=False)
initial_learning_rate = 0.1#初始学习率
learning_rate =tf.train.exponential_decay(initial_learning_rate,
global_step=global_step,
decay_steps=10,decay_rate=0.9)
opt = tf.train.GradientDescentOptimizer(learning_rate)
add_global = global_step.assign_add(1)
with tf.Session() as sess:
tf.global_variables_initializer().run()
print(sess.run(learning_rate))
for i in range(10):
_, rate =sess.run([add_global, learning_rate])
print(rate)
用法:
import tensorflow as tf
global_step = tf.Variable(0, trainable=False)
initial_learning_rate = 0.1#初始学习率
learning_rate =tf.train.exponential_decay(initial_learning_rate,
global_step=global_step,
decay_steps=10,decay_rate=0.9)
opt = tf.train.GradientDescentOptimizer(learning_rate)
add_global = global_step.assign_add(1)
with tf.control_denpendices([add_global]):
train_op =opt.minimise(loss)
with tf.Session() as sess:
tf.global_variables_initializer().run()
print(sess.run(learning_rate))
for i in range(10):
_=sess.run(train_op)
print(rate)
三十五、如何初始化LSTM的state
如何初始化LSTM的state
LSTM 需要 initial state。一般情况下,我们都会使用 lstm_cell.zero_state()来获取 initial state。但有些时候,我们想要给 lstm_cell 的 initial state 赋予我们想要的值,而不是简单的用 0 来初始化,那么,应该怎么做呢?
当然,当我们设置了state_is_tuple=False的时候,是很简单的,当state_is_tuple=True的时候,应该怎么做呢?
需要用到LSTMStateTuple
LSTMStateTuple(c ,h)
可以把 LSTMStateTuple() 看做一个op
fromtensorflow.contrib.rnn.python.ops.core_rnn_cell_impl importLSTMStateTuple
…
c_state = …
h_state = …
# c_state , h_state 都为Tensor,是需要初始化的值。
initial_state = LSTMStateTuple(c_state, h_state)
当然,GRU就没有这么麻烦了,因为GRU没有两个state。
三十六、损失函数加正则项:


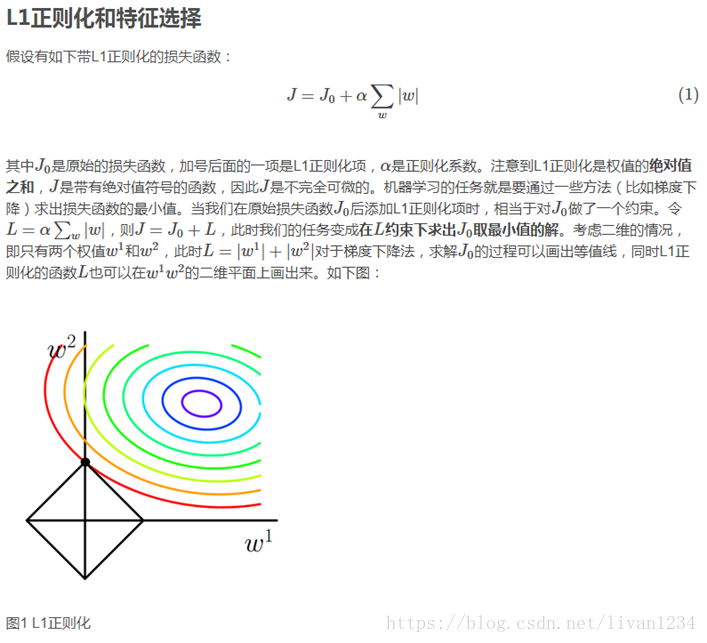




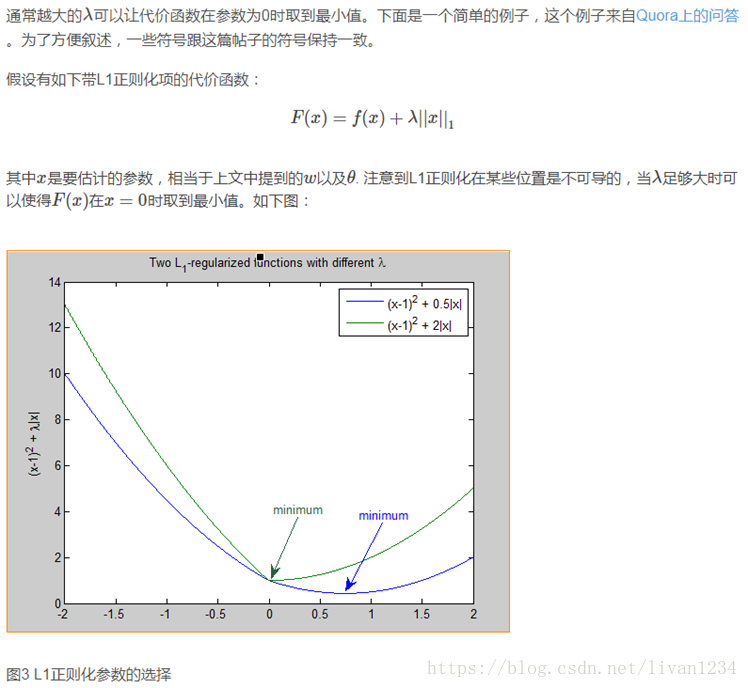


tensorflow Regularizers
在损失函数上加上正则项是防止过拟合的一个重要方法,下面介绍如何在TensorFlow中使用正则项.
tensorflow中对参数使用正则项分为两步:
1. 创建一个正则方法(函数/对象)
2. 将这个正则方法(函数/对象),应用到参数上
如何创建一个正则方法函数
tf.contrib.layers.l1_regularizer(scale,scope=None)
返回一个用来执行L1正则化的函数,函数的签名是func(weights).
参数:
· scale: 正则项的系数.
· scope: 可选的scope name
tf.contrib.layers.l2_regularizer(scale,scope=None)
返回一个执行L2正则化的函数.
tf.contrib.layers.sum_regularizer(regularizer_list,scope=None)
返回一个可以执行多种(个)正则化的函数.意思是,创建一个正则化方法,这个方法是多个正则化方法的混合体.
参数:
regularizer_list: regulizer的列表
已经知道如何创建正则化方法了,下面要说明的就是如何将正则化方法应用到参数上
应用正则化方法到参数上
tf.contrib.layers.apply_regularization(regularizer,weights_list=None)
先看参数
· regularizer:就是我们上一步创建的正则化方法
· weights_list: 想要执行正则化方法的参数列表,如果为None的话,就取GraphKeys.WEIGHTS中的weights.
函数返回一个标量Tensor,同时,这个标量Tensor也会保存到GraphKeys.REGULARIZATION_LOSSES中.这个Tensor保存了计算正则项损失的方法.
tensorflow中的Tensor是保存了计算这个值的路径(方法),当我们run的时候,tensorflow后端就通过路径计算出Tensor对应的值
现在,我们只需将这个正则项损失加到我们的损失函数上就可以了.
如果是自己手动定义weight的话,需要手动将weight保存到GraphKeys.WEIGHTS中,但是如果使用layer的话,就不用这么麻烦了,别人已经帮你考虑好了.(最好自己验证一下tf.GraphKeys.WEIGHTS中是否包含了所有的weights,防止被坑)
其它
在使用tf.get_variable()和tf.variable_scope()的时候,你会发现,它们俩中有regularizer形参.如果传入这个参数的话,那么variable_scope内的weights的正则化损失,或者weights的正则化损失就会被添加到GraphKeys.REGULARIZATION_LOSSES中.
示例:
import tensorflow as tf
from tensorflow.contrib import layers
regularizer = layers.l1_regularizer(0.1)
with tf.variable_scope(‘var’,initializer=tf.random_normal_initializer(),
regularizer=regularizer):
weight =tf.get_variable(‘weight’, shape=[8],initializer=tf.ones_initializer())
with tf.variable_scope(‘var2’,initializer=tf.random_normal_initializer(),
regularizer=regularizer):
weight2 =tf.get_variable(‘weight’, shape=[8],initializer=tf.ones_initializer())
regularization_loss =tf.reduce_sum(tf.get_collection(tf.GraphKeys.REGULARIZATION_LOSSES))
实例:
#coding:utf-8
import tensorflow as tf
defget_weight(shape,lambda):
var =tf.Variable(tf.random_normal(shape),dtype=tf.float32)
tf.add_to_collection(“losses”,tf.contrib.layers.l2_regularizer(lambda)(var))#把正则化加入集合losses里面
return var
x = tf.placeholder(tf.float32,shape=(None,2))
y_ = tf.placeholder(tf.float32,shape=(none,1))#真值
batcg_size = 8
layer_dimension = [2,10,10,10,1]#神经网络层节点的个数
n_layers = len(layer_dimension)#神经网络的层数
cur_layer = x
in_dimension = layer_dimension[0]
for i in range (1,n_layers):
out_dimension =layer_dimension[i]
weight =get_weight([in_dimension,out_dimension],0.001)
bias = tf.Variable(tf.constant(0.1,shape(out_dimension)))
cur_layer =tf.nn.relu(tf.matmul(x,weight)) + bias)
in_dimension =layer_dimension[i]
ses_loss = tf.reduce_mean(tf.square(y_ – cur_layer))#计算最终输出与标准之间的loss
tf.add_to_collenction(“losses”,ses_loss)#把均方误差也加入到集合里
loss = tf.add_n(tf.get_collection(“losses”))
#tf.get_collection返回一个列表,内容是这个集合的所有元素
#add_n()把输入按照元素相加
三十七、双向RNN
双向RNN实际上仅仅是两个独立的RNN放在一起, 本博文将介绍如何在tensorflow中实现双向rnn
单层双向rnn
单层双向rnn (cs224d)
tensorflow中已经提供了双向rnn的接口,它就是tf.nn.bidirectional_dynamic_rnn(). 我们先来看一下这个接口怎么用.
bidirectional_dynamic_rnn( cell_fw, #前向 rnn cell cell_bw, #反向 rnn cell inputs, #输入序列.sequence_length=None,# 序列长度
initial_state_fw=None,#前向rnn_cell的初始状态
initial_state_bw=None,#反向rnn_cell的初始状态
dtype=None,#数据类型
parallel_iterations=None,
swap_memory=False,
time_major=False,
scope=None)返回值:一个tuple(outputs, outputs_states), 其中,outputs是一个tuple(outputs_fw,outputs_bw). 关于outputs_fw和outputs_bw,如果time_major=True则它俩也是time_major的,vice versa. 如果想要concatenate的话,直接使用tf.concat(outputs, 2)即可.
如何使用:
bidirectional_dynamic_rnn 在使用上和 dynamic_rnn是非常相似的.
1. 定义前向和反向rnn_cell
2. 定义前向和反向rnn_cell的初始状态
3. 准备好序列
4. 调用bidirectional_dynamic_rnn
importtensorflowastf
from tensorflow.contrib import rnn
cell_fw = rnn.LSTMCell(10)
cell_bw = rnn.LSTMCell(10)
initial_state_fw = cell_fw.zero_state(batch_size)initial_state_bw = cell_bw.zero_state(batch_size)seq = ...seq_length = ...(outputs, states)=tf.nn.bidirectional_dynamic_rnn(cell_fw, cell_bw, seq, seq_length, initial_state_fw,initial_state_bw)out = tf.concat(outputs, 2)# ....多层双向rnn
多层双向rnn(cs224d)
单层双向rnn可以通过上述方法简单的实现,但是多层的双向rnn就不能使将MultiRNNCell传给bidirectional_dynamic_rnn了.
想要知道为什么,我们需要看一下bidirectional_dynamic_rnn的源码片段.
with vs.variable_scope(scope or "bidirectional_rnn"):
# Forward direction with vs.variable_scope("fw") as fw_scope: output_fw, output_state_fw = dynamic_rnn( cell=cell_fw, inputs=inputs, sequence_length=sequence_length, initial_state=initial_state_fw, dtype=dtype, parallel_iterations=parallel_iterations, swap_memory=swap_memory, time_major=time_major, scope=fw_scope)这只是一小部分代码,但足以看出,bi-rnn实际上是依靠dynamic-rnn实现的,如果我们使用MuitiRNNCell的话,那么每层之间不同方向之间交互就被忽略了.所以我们可以自己实现一个工具函数,通过多次调用bidirectional_dynamic_rnn来实现多层的双向RNN 这是我对多层双向RNN的一个精简版的实现,如有错误,欢迎指出
bidirectional_dynamic_rnn源码一探
上面我们已经看到了正向过程的代码实现,下面来看一下剩下的反向部分的实现.
其实反向的过程就是做了两次reverse
1. 第一次reverse:将输入序列进行reverse,然后送入dynamic_rnn做一次运算.
2. 第二次reverse:将上面dynamic_rnn返回的outputs进行reverse,保证正向和反向输出 对应位置的 输入是一致的 是对上的.
def _reverse(input_, seq_lengths, seq_dim, batch_dim):ifseq_lengthsisnotNone:
return array_ops.reverse_sequence( input=input_, seq_lengths=seq_lengths, seq_dim=seq_dim, batch_dim=batch_dim)else:
return array_ops.reverse(input_, axis=[seq_dim]) with vs.variable_scope("bw") as bw_scope:
inputs_reverse = _reverse( inputs, seq_lengths=sequence_length, seq_dim=time_dim, batch_dim=batch_dim) tmp, output_state_bw = dynamic_rnn( cell=cell_bw, inputs=inputs_reverse, sequence_length=sequence_length, initial_state=initial_state_bw, dtype=dtype, parallel_iterations=parallel_iterations, swap_memory=swap_memory, time_major=time_major, scope=bw_scope)output_bw = _reverse( tmp, seq_lengths=sequence_length, seq_dim=time_dim, batch_dim=batch_dim)outputs = (output_fw, output_bw)output_states = (output_state_fw, output_state_bw)return (outputs, output_states)
tf.reverse_sequence
对序列中某一部分进行反转
reverse_sequence( input,#输入序列,将被reverse的序列 seq_lengths,#1Dtensor,表示输入序列长度seq_axis=None,# 哪维代表序列
batch_axis=None,#哪维代表 batch
name=None,seq_dim=None,
batch_dim=None)官网上的例子给的非常好,这里就直接粘贴过来:
# Given this:batch_dim = 0seq_dim = 1input.dims = (4,8, ...)
seq_lengths = [7,2,3,5]
# then slices of input are reversed on seq_dim, but only up to seq_lengths:output[0, 0:7, :, ...] = input[0, 7:0:-1, :, ...]output[1, 0:2, :, ...] = input[1, 2:0:-1, :, ...]output[2, 0:3, :, ...] = input[2, 3:0:-1, :, ...]output[3, 0:5, :, ...] = input[3, 5:0:-1, :, ...]# while entries past seq_lens are copied through:output[0,7:, :, ...] = input[0,7:, :, ...]
output[1,2:, :, ...] = input[1,2:, :, ...]
output[2,3:, :, ...] = input[2,3:, :, ...]
output[3,2:, :, ...] = input[3,2:, :, ...]
例二:
# Given this:batch_dim = 2seq_dim = 0input.dims = (8, ?,4, ...)
seq_lengths = [7,2,3,5]
# then slices of input are reversed on seq_dim, but only up to seq_lengths:output[0:7, :, 0, :, ...] = input[7:0:-1, :, 0, :, ...]output[0:2, :, 1, :, ...] = input[2:0:-1, :, 1, :, ...]output[0:3, :, 2, :, ...] = input[3:0:-1, :, 2, :, ...]output[0:5, :, 3, :, ...] = input[5:0:-1, :, 3, :, ...]# while entries past seq_lens are copied through:output[7:, :,0, :, ...] = input[7:, :,0, :, ...]
output[2:, :,1, :, ...] = input[2:, :,1, :, ...]
output[3:, :,2, :, ...] = input[3:, :,2, :, ...]
output[2:, :,3, :, ...] = input[2:, :,3, :, ...]
三十八、control dependencies
tf.control_dependencies()设计是用来控制计算流图的,给图中的某些计算指定顺序。比如:我们想要获取参数更新后的值,那么我们可以这么组织我们的代码。
opt = tf.train.Optimizer().minize(loss)with tf.control_dependencies([opt]):
updated_weight = tf.identity(weight)with tf.Session() as sess:
tf.global_variables_initializer().run() sess.run(updated_weight, feed_dict={...}) # 这样每次得到的都是更新后的weight下面说明两种control_dependencies 不 work 的情况
下面有两种情况,control_dependencies不work,其实并不是它真的不work,而是我们的使用方法有问题。
第一种情况:
importtensorflowastf
w = tf.Variable(1.0)
ema = tf.train.ExponentialMovingAverage(0.9)
update = tf.assign_add(w, 1.0)ema_op = ema.apply([update])with tf.control_dependencies([ema_op]):
ema_val = ema.average(update)with tf.Session() as sess:
tf.global_variables_initializer().run() for i in range(3): print(sess.run([ema_val]))也许你会觉得,在我们 sess.run([ema_val]), ema_op 都会被先执行,然后再计算ema_val,实际情况并不是这样,为什么?
有兴趣的可以看一下源码,就会发现 ema.average(update) 不是一个 op,它只是从ema对象的一个字典中取出键对应的 tensor 而已,然后赋值给ema_val。这个 tensor是由一个在 tf.control_dependencies([ema_op]) 外部的一个 op 计算得来的,所以 control_dependencies会失效。解决方法也很简单,看代码:
importtensorflowastf
w = tf.Variable(1.0)
ema = tf.train.ExponentialMovingAverage(0.9)
update = tf.assign_add(w, 1.0) ema_op = ema.apply([update])with tf.control_dependencies([ema_op]):
ema_val = tf.identity(ema.average(update)) #一个identity搞定 with tf.Session() as sess:
tf.global_variables_initializer().run() for i in range(3): print(sess.run([ema_val]))第二种情况: 这个情况一般不会碰到,这是我在测试 control_dependencies 发现的
importtensorflowastf
w = tf.Variable(1.0)
ema = tf.train.ExponentialMovingAverage(0.9)
update = tf.assign_add(w, 1.0)ema_op = ema.apply([update])with tf.control_dependencies([ema_op]):
w1 = tf.Variable(2.0)
ema_val = ema.average(update)with tf.Session() as sess:
tf.global_variables_initializer().run() for i in range(3): print(sess.run([ema_val, w1]))这种情况下,control_dependencies也不 work。读取 w1 的值并不会触发 ema_op, 原因请看代码:
#这段代码出现在Variable类定义文件中第287行,# 在创建Varible时,tensorflow是移除了dependencies了的#所以会出现 control 不住的情况with ops.control_dependencies(None):
... 三十九、输入流水线
tensorflow 如何读取数据
tensorflow有三种把数据放入计算图中的方式:
· 通过feed_dict
· 通过文件名读取数据:一个输入流水线,在计算图的开始部分从文件中读取数据
· 把数据预加载到一个常量或者变量中
第一个和第三个都很简单,本文主要介绍的是第二种.
考虑一个场景:我们有大量的数据,无法一次导入内存,那我们一次就只能导入几个nimi-batch,然后进行训练,然后再导入几个mini-batch然后再进行训练.可能你会想,为什么我们不能在训练的时候,并行的导入下次要训练的几个mini-batch呢?幸运的是,tensorflow已经提供了这个机制.也许你还会问,既然你可以在训练前个mini-batch的时候把要训练的下几个mini-batch导进来,那么内存是足够将两次的mini-batch都导入进来的,为什么我们不直接把两次的mini-batch都导入呢,占满整个内存.实际上,这种方法,相比之前所述的流水线似的方法,还是慢的.
现在来看tensorflow给我们提供了什么
Queue
Queue,队列,用来存放数据(跟Variable似的),tensorflow中的Queue中已经实现了同步机制,所以我们可以放心的往里面添加数据还有读取数据.如果Queue中的数据满了,那么en_queue操作将会阻塞,如果Queue是空的,那么dequeue操作就会阻塞.在常用环境中,一般是有多个en_queue线程同时像Queue中放数据,有一个dequeue操作从Queue中取数据.一般来说enqueue线程就是准备数据的线程,dequeue线程就是训练数据的线程.
Coordinator(协调者)
Coordinator就是用来帮助多个线程同时停止.线程组需要一个Coordinator来协调它们之间的工作.
# Thread body: loop until the coordinator indicates astop was requested.
# If some condition becomes true, ask the coordinator tostop.
#将coord传入到线程中,来帮助它们同时停止工作
defMyLoop(coord):
whilenotcoord.should_stop():
…dosomething…
if …somecondition…:
coord.request_stop()
# Main thread: create a coordinator.
coord = tf.train.Coordinator()
# Create 10 threads that run ‘MyLoop()’
threads = [threading.Thread(target=MyLoop, args=(coord,))for i in xrange(10)]
# Start the threads and wait for all of them to stop.
for t in threads:
t.start()
coord.join(threads)
QueueRunner
QueueRunner创建多个线程对Queue进行enqueue操作.它是一个op.这些线程可以通过上面所述的Coordinator来协调它们同时停止工作.
example = …ops to create one example…
# Create a queue, and an op that enqueues examples one ata time in the queue.
queue = tf.RandomShuffleQueue(…)
enqueue_op = queue.enqueue(example)
#当enqueue_many中的数量多余`Queue`中剩余的数量时,会阻塞
#init = q.enqueue_many(([1.2,2.1,3.3],))
# Create a training graph that starts by dequeuing abatch of examples.
inputs = queue.dequeue_many(batch_size)
train_op = …use ‘inputs’ to buildthe training part of the graph…
# Create a queue runner that will run 4 threads inparallel to enqueue
# examples.
#定义了四个`enqueue`线程,但是还没有执行
qr = tf.train.QueueRunner(queue, [enqueue_op] * 4)
# Launch the graph.
sess = tf.Session()
# Create a coordinator, launch the queue runner threads.
coord = tf.train.Coordinator()
#执行 enqueue线程,像queue中放数据
enqueue_threads = qr.create_threads(sess, coord=coord,start=True)
# Run the training loop, controlling termination with thecoordinator.
for step in xrange(1000000):
ifcoord.should_stop():
break
sess.run(train_op)
# When done, ask the threads to stop.
coord.request_stop()
# And wait for them to actually do it.
coord.join(enqueue_threads)
有了这些基础,我们来看一下tensorflow的input-pipeline
tensorflow 输入流水线
我们先梳理一些之前说的东西.Queue是一个队列,QueueRunner用来创建多个线程对Queue进行enqueue操作.Coordinator可用来协调QueueRunner创建出来的线程共同停止工作.
下面来看tensorflow的输入流水线.
1. 准备文件名
2. 创建一个Reader从文件中读取数据
3. 定义文件中数据的解码规则
4. 解析数据
即:(文件名 -> reader-> decoder)
从文件里读数据,读完了,就换另一个文件.文件名放在string_input_producer中.
下面的代码是来自官网的一个示例
import tensorflow as tf
#一个Queue,用来保存文件名字.对此Queue,只读取,不dequeue
filename_queue = tf.train.string_input_producer([“file0.csv”, “file1.csv”])
#用来从文件中读取数据, LineReader,每次读一行
reader = tf.TextLineReader()
key, value = reader.read(filename_queue)
# Default values, in case of empty columns. Alsospecifies the type of the
# decoded result.
record_defaults = [[1], [1], [1], [1], [1]]
col1, col2, col3, col4, col5 = tf.decode_csv(
value,record_defaults=record_defaults)
features = tf.stack([col1, col2, col3, col4])
with tf.Session() as sess:
# Startpopulating the filename queue.
coord =tf.train.Coordinator()
#在调用run或eval执行读取之前,必须
#用tf.train.start_queue_runners来填充队列
threads =tf.train.start_queue_runners(coord=coord)
for i in range(10):
# Retrievea single instance:
example, label= sess.run([features, col5])
print(example,label)
coord.request_stop()
coord.join(threads)
我们来一步步解析它,
tf.train.string_input_producer([“file0.csv”, “file1.csv”])
先来看第一个APItf.train.string_input_producer([“file0.csv”,”file1.csv”]),看一下里面的代码怎么实现的.在追到input_producer时,我们会看到下面这些代码.
q = data_flow_ops.FIFOQueue(capacity=capacity,
dtypes=[input_tensor.dtype.base_dtype],
shapes=[element_shape],
shared_name=shared_name, name=name)
enq = q.enqueue_many([input_tensor])
queue_runner.add_queue_runner(
queue_runner.QueueRunner(
q, [enq],cancel_op=cancel_op))
if summary_name isnotNone:
summary.scalar(summary_name,
math_ops.cast(q.size(), dtypes.float32) * (1. /capacity))
return q
看到这,我们就很清楚tf.train.string_input_producer([“file0.csv”,”file1.csv”])到底干了啥了:
1. 创建一个Queue
2. 创建一个enqueue_op
3. 使用QueueRunner创建一个线程来执行enqueue_op,并把QueueRunner放入collection中
4. 返回创建的Queue
如今文件名已经用一个Queue管理好了,下一步就是如何从文件中读数据与解析数据了.
定义数据解析OP
reader = tf.TextLineReader() #创建一个读取数据的对象
key, value = reader.read(filename_queue)# 开始读取数据
对读取的一个数据进行解析,然后进行一些预处理
record_defaults = [[1], [1], [1], [1], [1]]
col1, col2, col3, col4, col5 = tf.decode_csv(
value,record_defaults=record_defaults)
解析完数据之后,我们就获得了一个样本的data和label Tensor.
现在我们就想了,能否通过Queue机制,利用多线程准备好batch数据,然后我们通过dequeue来获得一个mini-batch的样本呢?这个 tensorflow也给出了解决方案.
如何使用mini-batch
#定义数据的读取与解析规则
defread_my_file_format(filename_queue):
reader =tf.SomeReader()
key,record_string = reader.read(filename_queue)
example, label =tf.some_decoder(record_string)
processed_example= some_processing(example)
returnprocessed_example, label
definput_pipeline(filenames,batch_size, num_epochs=None):
filename_queue =tf.train.string_input_producer(
filenames,num_epochs=num_epochs, shuffle=True)
example, label =read_my_file_format(filename_queue)
#min_after_dequeue defines how big a buffer we will randomly sample
# from — bigger means better shuffling butslower start up and more
# memory used.
# capacitymust be larger than min_after_dequeue and the amount larger
# determines the maximum we willprefetch. Recommendation:
# min_after_dequeue + (num_threads + a smallsafety margin) * batch_size
#dequeue后的所剩数据的最小值
min_after_dequeue= 10000
#queue的容量
capacity =min_after_dequeue + 3 * batch_size
example_batch,label_batch = tf.train.shuffle_batch(
[example,label], batch_size=batch_size, capacity=capacity,
min_after_dequeue=min_after_dequeue)
returnexample_batch, label_batch
这里面重要的一个方法就是tf.train.shuffle_batch,它所干的事情有:
1. 创建一个RandomShuffleQueue用来保存样本
2. 使用QueueRunner创建多个enqueue线程向Queue中放数据
3. 创建一个dequeue_many OP
4. 返回dequeue_many OP
然后我们就可以使用dequeue出来的mini-batch来训练网络了.
tf.train.Feature(..)与tf.FixedLenFeature() 的对应关系
tfrecords 制作和解码时候,API接口是有一些对应关系的, 下面来看一下这些对应关系.
#制作时期
tf.train.Feature(int64_list=tf.train.Int64List(value=[1.0]))
#解码时期
tf.FixedLenFeature([],tf.int64) # 返回 1.0
tf.FixedLenFeature([1],tf.int64) # 返回 [1.0]
#对于之前的制作代码,这两种解码策略都是可以的,只不过返回的不同.
#制作时期
tf.train.Feature(int64_list=tf.train.Int64List(value=[1.0, 2.0]))
#解码时期
tf.FixedLenFeature([2],tf.int64) # 返回[1.0, 2.0]
#对于bytes,制作时期
tf.train.Feature(bytes_list=tf.train.BytesList(value=[bytestring]))
#解码时期
tf.FixedLenFeature([],tf.string)
tf.FixedLenFeature([1],tf.string)
# 如果在制作过程中, value 的长度是变化的话,解码的时候是需要用tf.VarLenFeature(dtype)了
# 上述只是说 value的长度变化, 而不是说bytestring 的大小变化,如果bytestring变化的话,是不需要担心的,
# 一个例子就是,如果制作tfrecords的图片大小是变化的,这时候改变的只是bytestring的大小,但是value的长度
# 还是1,这时候用FixedLenFeature解码是可以正确还原数据的.
tf.train.FloatList 保存的是 float32 还是 float64 : 是 float32。
四十、使用tfdbg进行debug:
由于 tensorflow 在训练的时候是在后台运行的,所以使用 python 的 debug 工具来 debugtensorflow 的执行过程是不可行的,为此,官方提供了一款debug 工具,名为 tfdbg
有很多人觉得,为了 debugtensorflow 的计算过程又要学习一个新的工具,很烦。
但其实不然,tfdbg 用起来是十分简单的。以至于简单到我们只需要增加两行代码,就可以将之前的模型改成可 debug 的。
在 debug 界面,也只需熟悉几个常用的命令就可以了。
# 第一行: 引包from tensorflow.python import debug as tf_debug
sess = tf.Session()# 初始化的 sess 没必要加上 debug wrappersess.run(tf.global_variables_initializer())# 第二行,给 session 加个 wrapperdebug_sess = tf_debug.LocalCLIDebugWrapperSession(sess=sess)debug_sess.run(train_op) # 用 加了 wrapper 的 session,来代替之前的 session 做训练操作好了,这样就可以了,然后命令行执行:
python demo_debug.py# 或者python -m demo_debug不一会,下面界面就会出现,就可以开心的 debug 了
Tips : debug 界面中带下划线的东西都是可以用鼠标点一下,就会触发相应操作的
关于debug 界面的命令,官方文档有详细的说明 :
https://www.tensorflow.org/programmers_guide/debugger#debugging_model_training_with_tfdbg
核心的几个命令是:
· run :执行一次 debug_session.run() , 这次执行产生中间 tensor 的值都可以通过 debug 界面查看
· exit :退出debug
注意事项
· debug 的 wrapper 要加在执行 train_op 的 session 上,因为要 debug 的是 train 过程。但是如果是想 debug input-pipeline 的话,感觉是可以将 wrapper 加在执行input-pipeline 的session 上的(没有测试过)。
· 如果代码中使用了 input-pipeline 的话, debug 非常慢(不知道原因是啥)
四十一、用queue保存更复杂的内容
当查看 tensorflow 中提供的 Queue 的类的时候,会发现有个 dtypes 参数,这个参数代表 Queue 中元素是什么类型的,如果 dtypes=[tf.string, tf.int64] ,这个表示,Queue 中每个元素是 (string, int) 。
importtensorflowastf
queue = tf.FIFOQueue(capacity=100, dtypes=[tf.string, tf.int64])# enqueue_many 的写法,两个元素放在两个列表里。en_m = queue.enqueue_many([['hello', 'world'], [1, 2]])# enqueue 的写法en = queue.enqueue(['hello', 1])deq = queue.dequeue()with tf.Session() as sess:
sess.run(en_m) print(sess.run(deq))四十二、session.run()的解释
当我们训练自己的神经网络的时候,无一例外的就是都会加上一句 sess.run(tf.global_variables_initializer()) ,这行代码的官方解释是 初始化模型的参数。那么,它到底做了些什么?
在执行tensor的时候,你可以使用sess.run()在同一步获取多个tensor中的值,使用Tensor.eval()时只能在同一步当中获取一个tensor值,并且每次使用 eval 和 run时,都会执行整个计算图。
一步步看源代码:(代码在后面)
· global_variables_initializer 返回一个用来初始化计算图中所有globalvariable的 op。
· 这个op 到底是啥,还不清楚。
· 函数中调用了 variable_initializer() 和 global_variables()
· global_variables() 返回一个 Variable list ,里面保存的是 gloabalvariables。
· variable_initializer() 将 Variable list 中的所有 Variable 取出来,将其 variable.initializer 属性做成一个 op group。
· 然后看 Variable 类的源码可以发现, variable.initializer 就是一个 assign op。
所以: sess.run(tf.global_variables_initializer()) 就是 run了 所有globalVariable 的 assign op,这就是初始化参数的本来面目。
defglobal_variables_initializer():
“””Returnsan Op that initializes global variables.
Returns:
An Op thatinitializes global variables in the graph.
“””
returnvariables_initializer(global_variables())
defglobal_variables():
“””Returnsglobal variables.
Returns:
A list of`Variable` objects.
“””
returnops.get_collection(ops.GraphKeys.GLOBAL_VARIABLES)
defvariables_initializer(var_list,name=“init”):
“””Returnsan Op that initializes a list of variables.
Args:
var_list: Listof `Variable` objects to initialize.
name: Optionalname for the returned operation.
Returns:
An Op that runthe initializers of all the specified variables.
“””
if var_list:
returncontrol_flow_ops.group(*[v.initializer for v in var_list],name=name)
returncontrol_flow_ops.no_op(name=name)
classVariable(object):
def_init_from_args(self,…):
self._initializer_op = state_ops.assign(
self._variable, self._initial_value,
validate_shape=validate_shape).op
@property
definitializer(self):
“””Theinitializer operation for this variable.”””
returnself._initializer_op