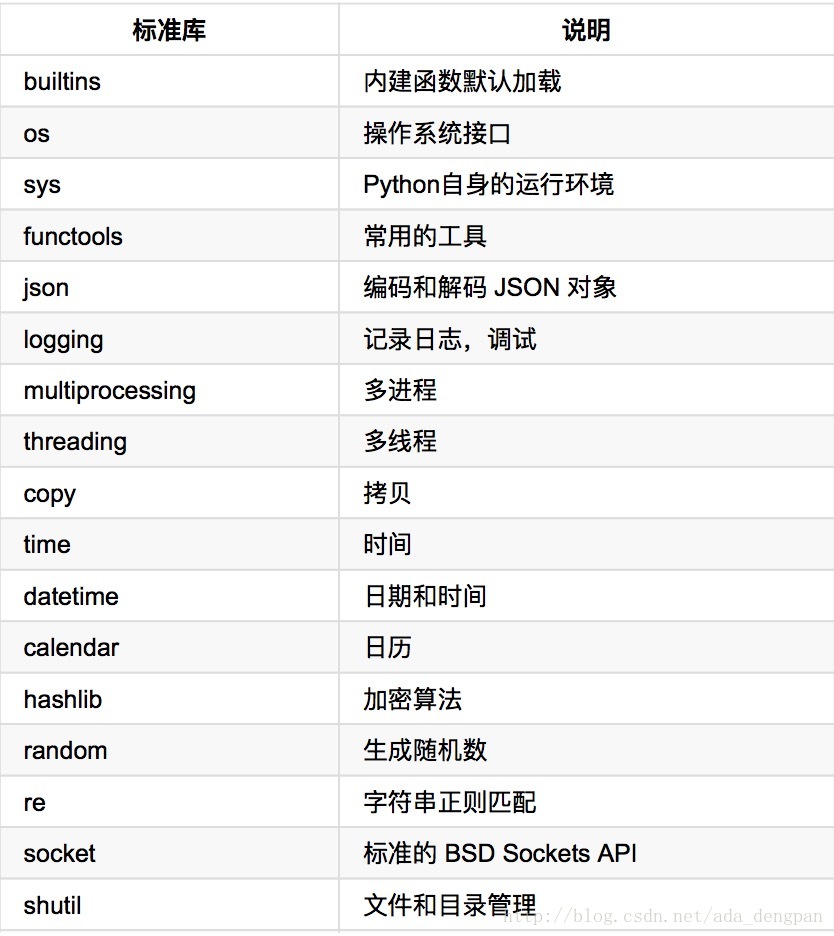
模块重新导入
当import moduleName 的时候,python是通过sys.path 来查找的。可以使用sys.path.append('newPath') 可以添加搜索路径。
当import了一个module之后,修改了module的代码,那么在当前运行时不会更新module修改后的功能。需要重新导入:
form imp import *
reload(moduleName)- 1
- 2
- 循环导入:
a import b ,b import a ,导致循环导入,发生错误。解决思路是建一个主模块,建多个子模块,让主模块调用子模块,避免循环导入。
is 和 ==
==是判断两个对象值是否相等
is是判断两个是否指向同一个对象(引用比较)
深拷贝 浅拷贝
浅拷贝:给变量赋值,只将自己的引用赋值给变量,没有赋值。
深拷贝:import copy b = copy.deepcopy(a)
import copy
b = copy.copy(a)
copy.copy指深拷贝本身变量的值,而不会深拷贝变量里面元素的值;而copy.deepcopy会深拷贝里面的值- 1
- 2
- 3
copy.copy如果拷贝的是不可变类型,则是浅拷贝。
property
class Test(object):
def __init__(self):
self.__num = 100
def setNum(self, newNum):
print("----setter----")
self.__num = newNum
def getNum(self):
print("----getter----")
return self.__num
num = property(getNum, setNum)
#t.num = 200 #相当于调用了 t.setNum(200)
#print(t.num) #相当于调用了 t.getNum()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
或者
class Test(object):
def __init__(self):
self.__num = 100
@property
def num(self):
print("----getter----")
return self.__num
@num.setter
def num(self, newNum):
print("----setter----")
self.__num = newNum
t = Test()
#t.num = 200 #相当于调用了 t.setNum(200)
#print(t.num) #相当于调用了 t.getNum()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
迭代器
- 可迭代对象
Iterable- 一类是集合数据类型:list,tuple,dict,set str
- 一类是generator,包括生成器和带yield的generator function
- 判断对象是否可以迭代
from collections import Iterable
isinstance(Obj,Iterable)- 1
- 2
- 迭代器。可以用next()返回下一个值的对象。
Iterator
from collections import Iterable
isinstance(Obj,Iterable)- 1
- 2
iter()函数,可以将可迭代对象转成迭代器。
闭包
在函数内部定义一个函数,并且这个函数用到了外边函数的变量,那么将这个函数以及用到的一些变量称之为闭包。
def func(var):
def func_closure():
print(var*2)
return func_closure
f = func(123)
f()- 1
- 2
- 3
- 4
- 5
- 6
- 7
装饰器
原理:
def auth(func):
def inner():
print('验证权限...')
func()
return inner
def f1():
pass
def f2():
pass
f1 = auth(f1)
f1()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
应用:语法糖简化调用
def auth(func):
print('装饰1...')
def inner():
print('验证权限1...')
func()
return inner
def auth2(func):
print('装饰2...')
def inner():
print('验证权限2...')
func()
return inner
@auth #相当于 f1 = auth(f1) ->注意装饰器的执行时间
@auth2
def f1():
pass
@auth
def f2():
pass
f1()
#@语法糖可以加多个
执行结果:
装饰2...
装饰1...
验证权限1...
验证权限2...- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
通用的的装饰器
def decorate(functionName):
def funcIn(*args,**kwargs):
ret = functionName(*args,**kwargs)
return ret
return funcIn- 1
- 2
- 3
- 4
- 5
装饰器带参数
作用:在运行时起到有不同的功能。
def decorateArgs(pre="hello"):
def decorate(functionName):
def funcIn(*args,**kwargs):
ret = functionName(*args,**kwargs)
return ret
return funcIn
return decorate
@decorateArgs("bendeng")
def test():
pass- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
作用域
globals() 查看当前命名空间所有的全局变量。
localls() 查看当前命名空间所有的局部变量。
LEGB 原则:local->enclosing->global->buildins
dir(__buildin__) 查看所有内嵌
动态语言
在运行时给对象(类)绑定(添加)属性(方法)。
class Test:
pass
def test(self):
pass
#动态添加属性可以直接添加
#动态添加方法使用types的MethodType方法
import types
t.test() = types.MethodType(test,t)#或者xxx = types.MethodType(test,t)
t.test()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
静态方法和类方法直接添加
@staticmethod
def staticMethod():
pass
@classmethod
def classMethod():
pass
class Test:
pass
Test.test = staticMethod
Test.test = classMethod- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
__slots__可以限制class实例能添加的属性
class Person:
__slots__ = ("name","age")- 1
- 2
生成器
python中一边循环一边计算的机制,叫generator,生成器。
产生原因:生成列表时,如果很大(比如10000000),那么会占用很大的储存空间。根据列表生成规则只生成前面几个,就产生了生成器。
- 生成器创建方法1:
a = (x for x in range(10)) - 生成器创建方法2: 存在
yield的函数称为生成器
def generator():
b = 0
for i in range(10):
yield b #next()一次就执行到这里停顿,b会更新值
b = i * 2
a = generator()
next(a) <==> a.__next__() #两种方式等价
for c in a: #生成器可以放在for循环里执行
pass- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
send:
def test():
i = 0
while i < 5:
temp = yield i
print(temp)
i += 1
t = test()
t.__next__() #temp 为None
t.send('hello') #temp为hello。send可以为temp赋值,相当于yield i的值为'hello'并赋值给temp
#第一次调用t.send(None)不会报错- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
yield作用:多任务。三种多任务方法之一:协程。
def test1():
while True:
print('1')
yield None
def test2():
while True:
print('2')
yield None
t1 = test1()
t2 = test2()
while True:
t1.__next__()
t2.__next__()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
垃圾回收
- 小整数[5,257)共享对象,常驻内存
- 单个字符共享对象,常驻内存
- 单个单词不可修改,默认开启
intern机制,共用对象,引用计数为0,则销毁。 - 字符串(含有空格),不可修改,不开启
intern机制,不共用对象,引用计数为0,销毁。 - 大整数不共用内存,引用计数为0,销毁。
- 数值类型和字符串类型在python中是不可变的,即无法修改一个对象的值,每次对对象的修改,实际上是创建一个新对象。
python采用引用计数为主,标记-清除和分代收集两种机制为辅的策略。
引用计数
- 优点:
- 简单
- 实时性:一旦没有引用,内存就直接被释放。不用像其它机制等到特定时机。实时性还带来一个好处,处理回收内存的时间分摊到了平时。
- 缺点
- 维护引用计数消耗资源
- 循环引用
- 导致引用计数+1 的情况
- 对象被创建,a = “hello”
- 对象被引用,b = a
- 对象被当做参数传入一个函数,func(a)
- 对象作为一个元素,储存在容器中,list=[a,b]
- 导致引用计数-1的情况
- 对象的别名被显示销毁,del a
- 对象的别名被赋予新的对象,a = “world”
- 一个对象离开它的作用域,如局部对象
- 对象所在的容器被销毁,或从容器中删除对象
- 查看一个对象的引用计数
import sys
a = "hello world"
sys.getrefcount(a)- 1
- 2
- 3
这里查看a对象的引用计数,会比正常计数大1。
垃圾回收
- 垃圾回收的对象会存放在
gc.garbage列表里面 gc.collect()会返回不可达的对象数目。- 三种情况会触发垃圾回收
- 调用gc.collect()
- 当gc模块的计数器达到阈值的时候
- 程序退出的时候
- gc模块常用功能
- 1、gc.set_debug(flag).一般设置为gc.DEBUG_LEAK
- 2、gc.collect()。显示进行垃圾回收
- 3、gc.get_threshould()获取gc模块中自动执行垃圾回收的频率。如(700,10,10)
- 4、gc.set_threshould(threshould0,[threshould1,[threshould2])设置自动执行垃圾回收的频率
- gc.get_count()获取当前自动执行垃圾回收的计数器,返回一个长度为3的列表。例如(465,7,6),465表示距离上一次一代垃圾检查Python分配内存的数目减去释放内存的数目;7指距离上一次二代检查,一代垃圾检查的次数;6是指距离上一次三代垃圾检查,二代垃圾检查的次数。
在Python中,采用分代收集的方法。把对象分为三代,一开始,对象在创建的时候,放在一代中,如果在一次一代的检查中,该对象存活下来,就会被放到二代中,同理在一次二代的检查中,该对象存活下来,就会放到三代中。
gc模块唯一处理不了的是循环引用的类都有
__del__方法,所以项目中尽量避免定义__del__方法。
内建属性

class Test(object):
def __init__(self,subject1):
self.subject1 = subject1
self.subject2 = 'python'
#属性访问拦截器
def __getattribute__(self,obj):
if(obj == 'subject1'):
print('access property subject1')
return 'back custom subject1 value'
else:
#return self.show() 发生递归调用,程序崩溃
return object.__getattribute__(self,obj)
def show(self):
pass
t = Test('p')
print(t.subject1)
print(t.subject2)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
强调内容
不要在
__getattribute__中调用self.xxxx。
内建函数
输入dir(__buildin__)可以看到很多python解释器启动后默认加载的属性和函数。
常用的内建函数:
- range()
- map():map(func,sequence,[sequence,]),,返回值是list
m = map(lambda x:x*x,[1,2,3])
print(list(m)) #结果为[1,4,9]- 1
- 2
- filter():对指定序列执行过滤操作。返回值的类型和参数sequence的类型相同
f = filter(lambda x:x%2,[2,3])
print(list(f)) #结果为[3]- 1
- 2
- reduce():对参数序列中的元素进行累积。
reduce(lambda x,y:x+y,[1,2,3,4])- 1
在python3中,reduce函数从全局名字空间移除了,现在放置在functools模块里。
from functools import reduce
- sorted()
sorted([2,1,3,4]) #[1,2,3,4]
sorted([2,1,3,4],reverse=1) #[4,3,2,1]- 1
- 2
集合Set
集合与列表、元组类似,可以储存多个数据,但是这些数据是不重复的。
集合对象支持union(联合)、difference(差)和sysmmetric_difference(对称差集)等数学运算。
x = set([1,2,3,4]) #{1,2,3,4}
y = set([2,3,5,6,2]) #{2,3,5,6}
x & y #交集{2, 3}
x | y #并集{1, 2, 3, 4, 5, 6}
x ^ y #差集{1, 4, 5, 6}- 1
- 2
- 3
- 4
- 5
functools
functools是python2.5引入的。一些工具函数放在此包中。python3中增加了更多的函数,但很多不常用到。下面是常用的两个函数 :
particial函数(偏函数):把一些函数的某些参数设置成默认值,返回一个新的函数,调用新函数会更简单。
import functools
def showValue(*args,**kwargs):
print(args)
print(kwargs)
#p = showValue
#p(1,2,3)
p = functools.partial(showValue,1,2,3)
p() #(1, 2, 3) {}
p(id=123) #(1,2,3) {'id':123}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
wraps函数
使用装饰器时,需要注意被装饰后的函数其实已经是另外一个函数了(函数名等函数属性会改变)。
由于函数名和__doc__变化,对测试结果会有一些影响。
import functools
def note(func):
'''note function'''
#@functools.wraps(func)
def wrapper():
'''wrapper function'''
print('note something')
return func
return wrapper
@note
def test():
'''test function'''
print('test ~')
print(test.__name__) #wrapper
print(test.__doc__) #wrapper function- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
使用@functools.wraps(func)后,print(test.__doc__)会返回test function。
模块进阶

- hashlib
import hashlib
m = hashlib.md5()
m.update('bendeng')
m.hexdigest() #45ac4274cad82274abcfce45f494eea4 - 1
- 2
- 3
- 4
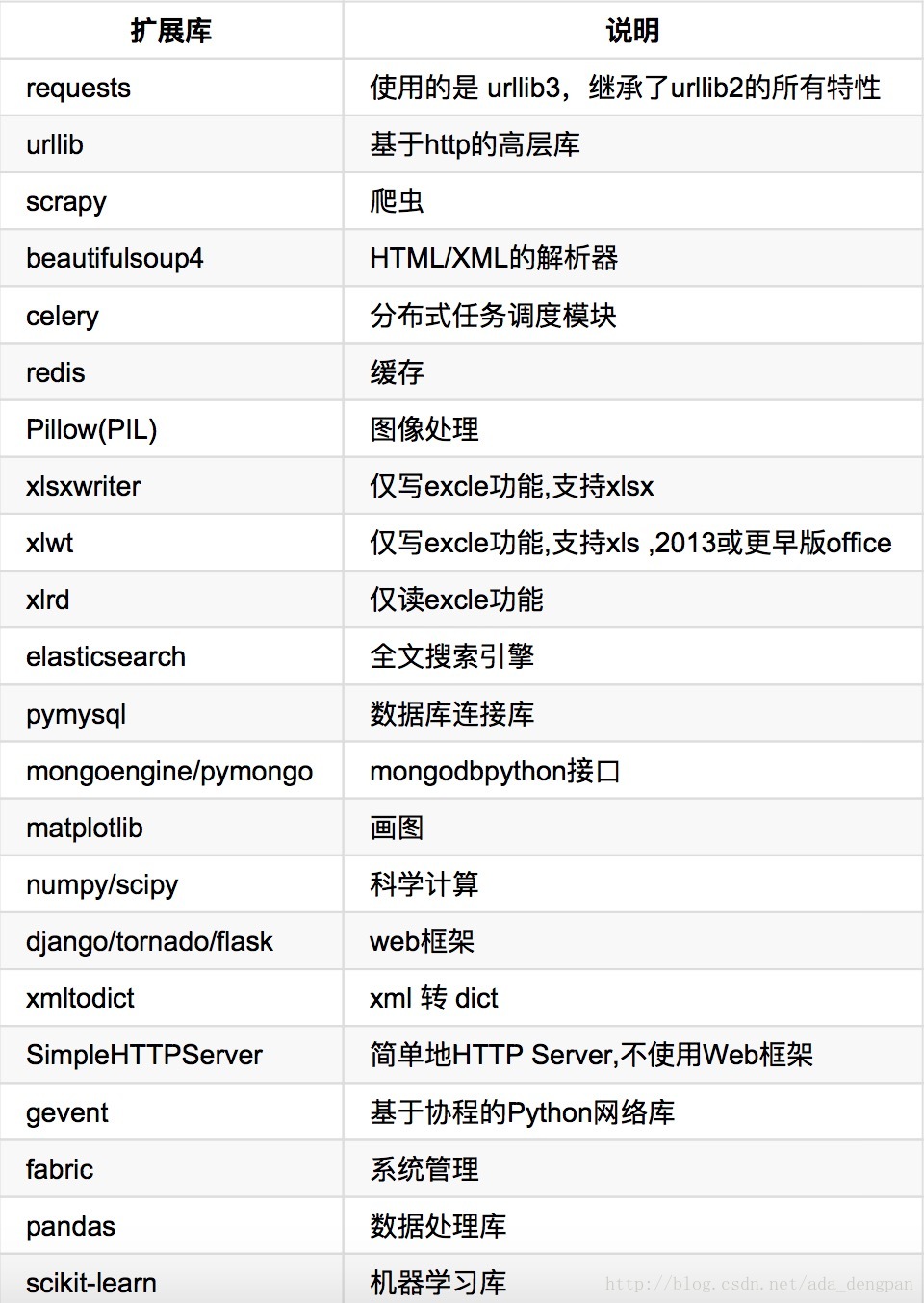
常用的扩展库:
Python2中,python -m SimpleHTTPServer PORT,python3中,python3 -m http.server PORT。可运行起来静态服务, 用于预览和下载文件。
- 读写Exce文件
1、安装个easy_install工具
sudo apt-get install python-setuptools- 1
2、安装模块
sudo easy_install xlrd
sudo easy_install xlwt- 1
- 2
调试
pdb是基于命令行的 调试工具,非常类似于GNU的gdb。
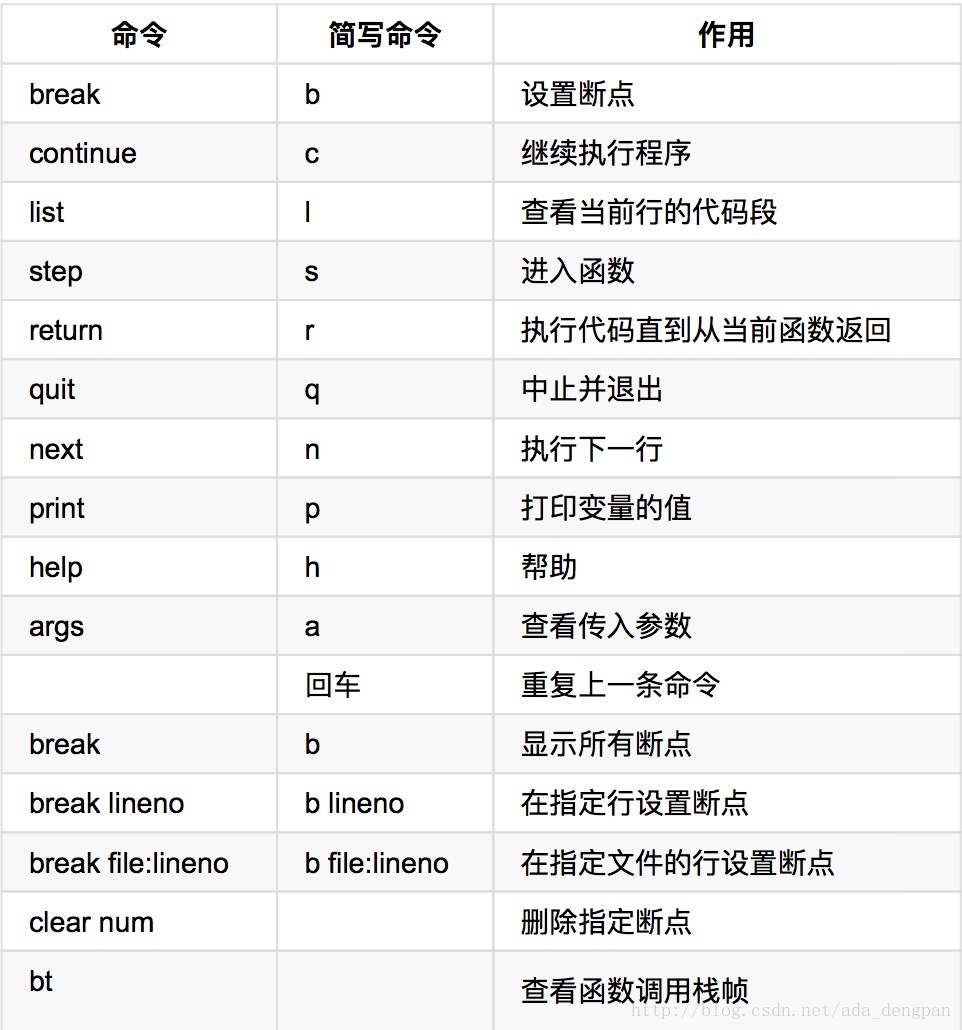
- 执行时调试
python -m pdb some.py - 交互调试,进入pythoo或者ipython:
import pdb
pdb.run('testfun(args)')- 1
- 2
- 程序里埋点
import pdb
pdb.set_trace()- 1
- 2
- 日志调试
print
正则表达式
正则表达式是所有语言通用的字符串匹配方式。
python中使用正则表达式:
import re
#使用match方法进行匹配操作
result = re.match(正则表达式,要匹配的字符串)
#提取数据
result.group()- 1
- 2
- 3
- 4
- 5
- 6
match方法返回匹配对象Match Object;否则返回None。
表示单个字符串
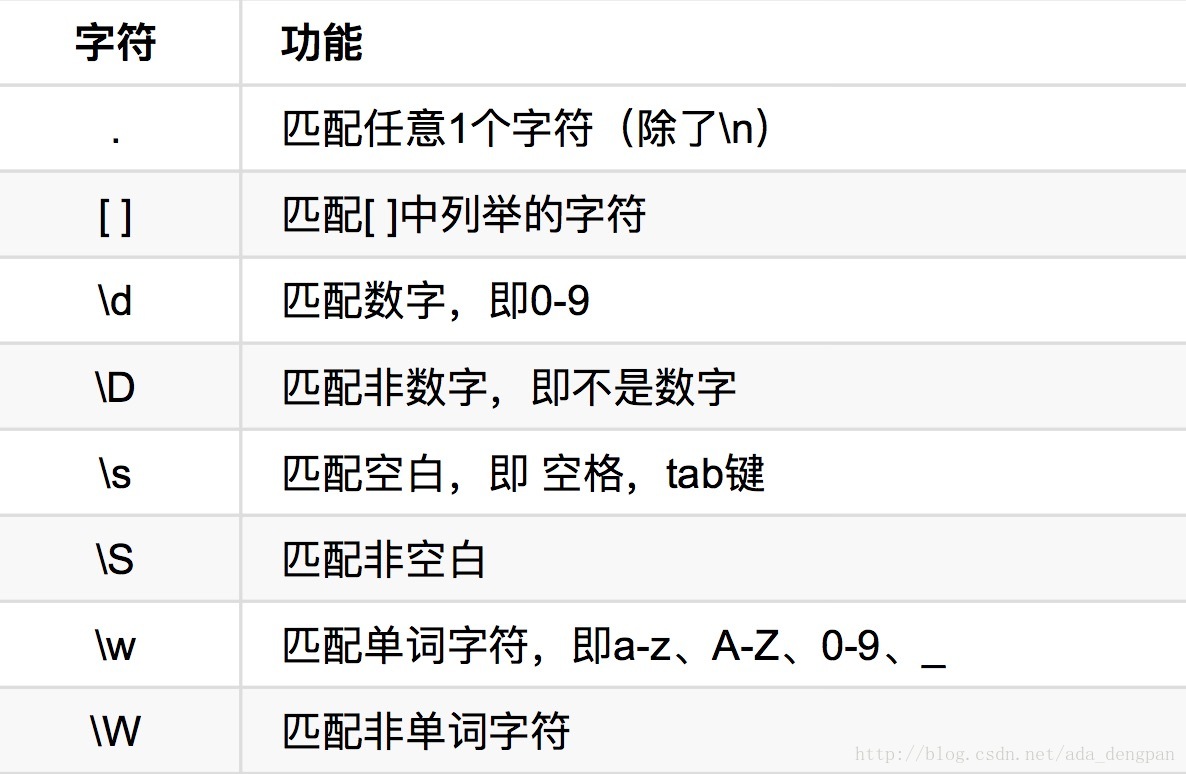
\d = [0-9]
\D = [^0-9]
\w = [a-zA-Z0-9_]
\W = [^a-zA-Z0-9_]- 1
- 2
- 3
- 4
表示匹配数量的表达式

* {0,}
+ {1,}
? {0,1}- 1
- 2
- 3
Python中使用字符r表示字符使用原始字符。
表示边界:
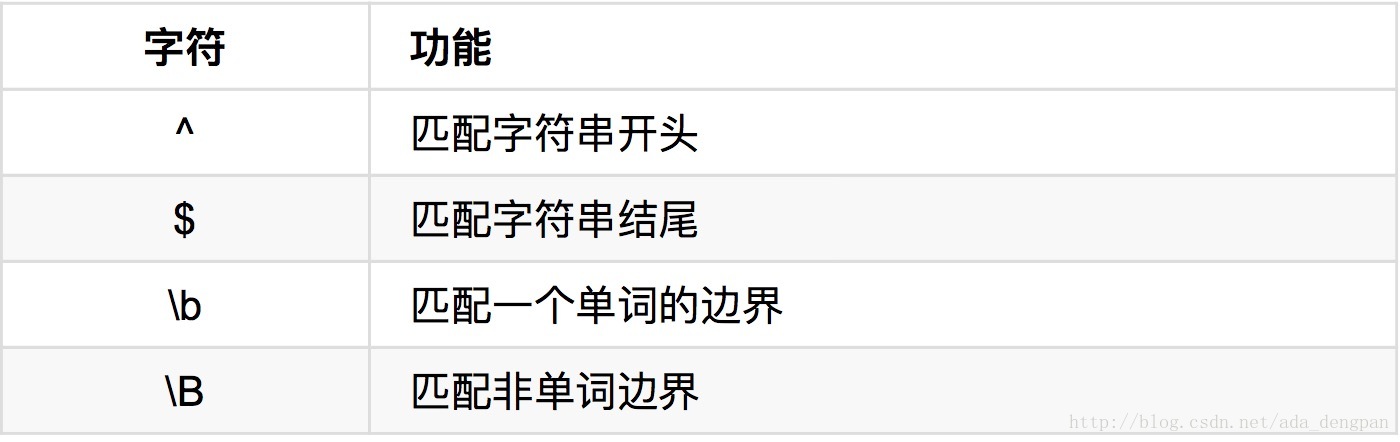
re.match(r'.{3}\b','ben deng') #ben
re.match(r'.+\B','bendeng') #benden- 1
- 2
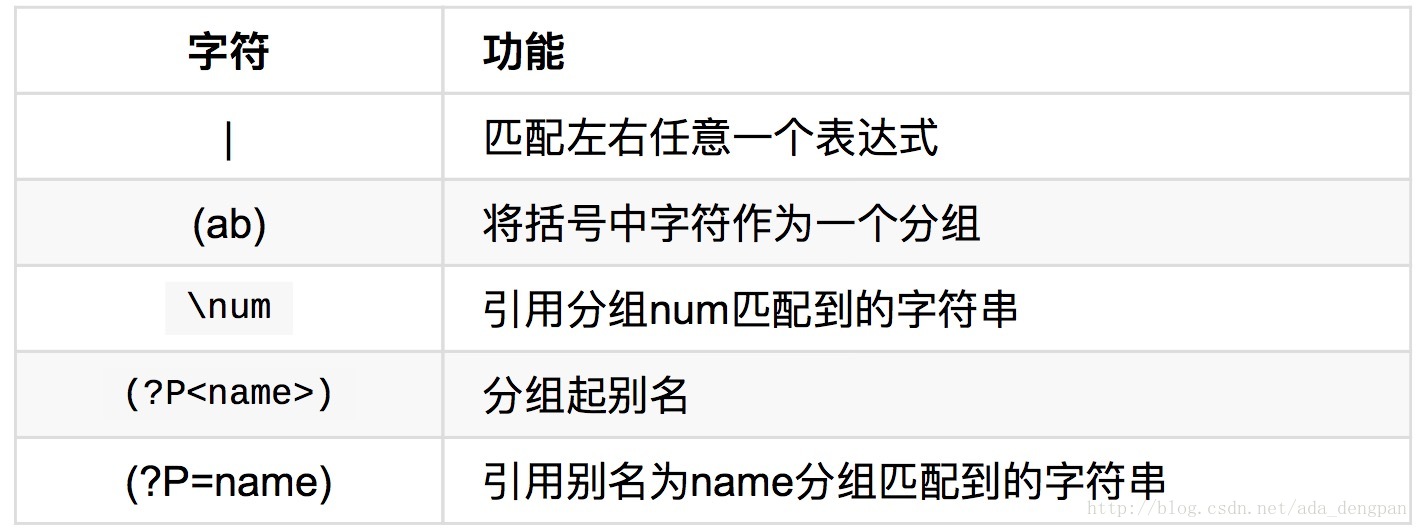
匹配分组
匹配任意一个0-100的数字r'[1-9]\d?$|0$|100$'
或r'[1-9]?\d?$|100$'
分组匹配
r = re.match(r'<h1>(.*)</h1><h2>(.*)</h2>','<h1>网页标题</h1><h2>H2文本</h2>')
r.group|r.group(0) #'<h1>网页标题</h1><h2>H2文本</h2>'
r.group(1) #网页标题
r.group(2) #H2文本
r.groups() #('网页标题', 'H2文本')- 1
- 2
- 3
- 4
- 5
分组别名示例:
#coding=utf-8
import re
r = re.match(r'<(?P<k1>.+)>.*</(?P=k1)><(?P<k2>.+)>.*</(?P=k2)>','<h1>h1文本</h1><h2>H2文本</h2>')
print(r.groups()) #('h1','h2')- 1
- 2
- 3
- 4
高级用法
- search
从左向右搜索拿到第一个结果则停止
import re
re.search(r'h\d','<h1>h1文本</h1><h2>H2文本</h2>')
# h1- 1
- 2
- 3
- findall
找到所有匹配的结果
import re
re.findall(r'h\d','<h1>h1文本</h1><h2>H2文本</h2>')
#['h1', 'h1', 'h1', 'h2', 'h2']- 1
- 2
- 3
- sub
正则替换
import re
re.sub(r'h\d','m','<h1>h1文本</h1><h2>H2文本</h2>')
#'<m>m文本</m><m>H2文本</m>'- 1
- 2
- 3
- split
分割字符串
import re
re.split(r'<.+?>','<h1>h1文本</h1><h2>H2文本</h2>')
#['', 'h1文本', '', 'H2文本', '']- 1
- 2
- 3
贪婪和非贪婪模式
正则表达式默认是贪婪模式,使用?使用非贪婪模式。