回复内容:
context_re = r'(.*?)’你准备的这个正则表达式啊,truncated!断在了这里,所以只能爬第一段。爬取新浪军事论坛需要做三件事:一、上csdn汪海老师的专栏,http://blog.csdn.net/column/details/why-bug.html,学习一个。
 二、按f12看一下前端。
二、按f12看一下前端。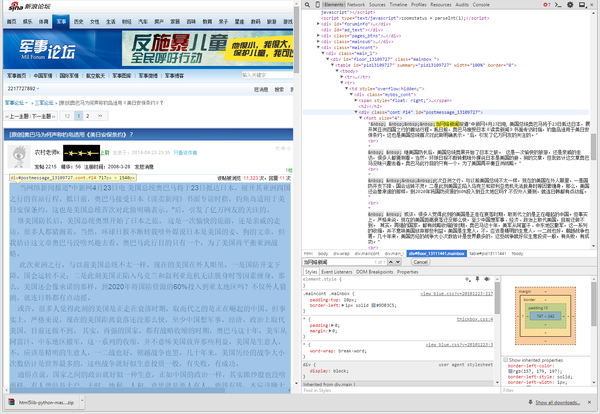 三、
三、
from bs4 import beautifulsoup
import requests
response = requests.get(“http://club.mil.news.sina.com.cn/thread-666013-1-1.html?retcode=0”) #硬点网址
response.encoding = ‘gb18030’ #中文编码
soup = beautifulsoup(response.text, ‘html.parser’) #构建beautifulsoup对象
ps = soup(‘p’, ‘mainbox’)
#每个楼层
for p in ps:
comments = p.find_all(‘p’,’cont f14′) #每个楼层的正文
with open(‘sina_military_club.txt’,’a’) as f:
f.write(‘\n’+str(comments)+’\n’)
刚好几个小时前就在写一个爬取网站会员(公司)资料的小程序具体的编程问题就不回答了,跟用什么语言写代码无关,关键是你要分析好这个页面的html代码结构,写出合适的正则表达式来进行匹配,如果想简化的话,可以进行分次匹配(比如先得到
里面的第一个
里面的内容就是原帖的地址,然后再进一步处理)大数据分析就不会了,还请赐教。
import requests
from bs4 import beautifulsoup
r = requests.get(“http://club.mil.news.sina.com.cn/thread-666013-1-1.html”)
r.encoding = r.apparent_encoding
soup = beautifulsoup(r.text)
result = soup.find(attrs={“class”: “cont f14”})
print result.text
用beautifulsoup吧,正则太多了看着都头疼.
先用了beautifulsoup爬取数据
# -*- coding:utf-8 -*-
import re, requests
from bs4 import beautifulsoup
import sys
reload(sys)
sys.setdefaultencoding(‘utf-8’)
url = “http://club.mil.news.sina.com.cn/viewthread.php?t
req = requests.get(url)
req.encoding = req.apparent_encoding
html = req.text
soup = beautifulsoup(html)
file = open(‘sina_club.txt’, ‘w’)
x = 1
for tag in soup.find_all(‘p’, attrs = {‘class’: “cont f14”}):
word = tag.get_text()
line1 = “—————评论” + str(x) + “———————” + “\n”
line2 = word + “\n”
line = line1 + line2
x += 1
file.write(line)
file.close()
哎,扒就扒吧,发了paper能不能告诉我刊号页数让我看一下?我们自己都没做大数据分析……
建议用一下正则测试工具
你需要pyquery,可以使用jquery一样的语法。你值得拥有。https://pythonhosted.org/pyquery/