在最初学习python的时候,只知道有dom和sax两种解析方法,但是其效率都不够理想,由于需要处理的文件数量太大,这两种方式耗时太高无法接受。
在网络搜索后发现,目前应用比较广泛,且效率相对较高的elementtree也是一个比较多人推荐的算法,于是拿这个算法来实测对比,elementtree也包括两种实现,一个是普通elementtree(et),一个是elementtree.iterparse(et_iter)。
本文将对dom、sax、et、et_iter四种方式进行横向对比,通过处理相同文件比较各个算法的用时来评估其效率。
程序中将四种解析方法均写为函数,在主程序中分别调用,来评估其解析效率。
解压后的xml文件内容示例为:
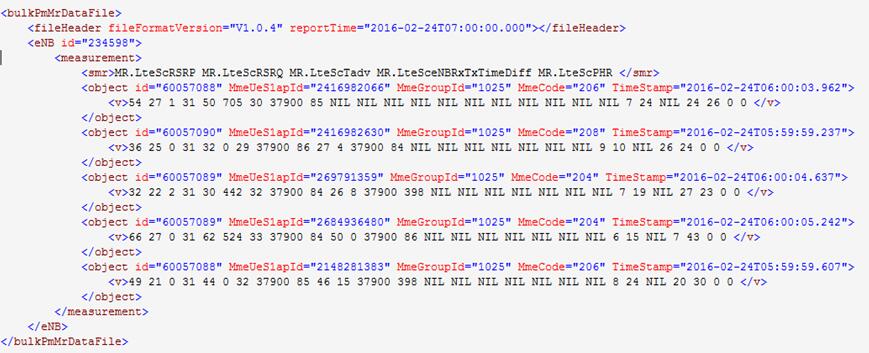
主程序函数调用部分代码为:
print(“文件计数:%d/%d.” % (gz_cnt,paser_num))
str_s,cnt = dom_parser(gz)
#str_s,cnt = sax_parser(gz)
#str_s,cnt = et_parser(gz)
#str_s,cnt = et_parser_iter(gz)
output.write(str_s)
vs_cnt += cnt
在最初的函数调用中函数返回两个值,但接收函数调用值时用两个变量分别调用,导致每个函数都要执行两次,之后修改为一次调用两个变量接收返回值,减少了无效调用。
1、dom解析
函数定义代码:
def dom_parser(gz):
import gzip,cstringio
import xml.dom.minidom
vs_cnt = 0
str_s = ”
file_io = cstringio.stringio()
xm = gzip.open(gz,’rb’)
print(“已读入:%s.\n解析中:” % (os.path.abspath(gz)))
doc = xml.dom.minidom.parsestring(xm.read())
bulkpmmrdatafile = doc.documentelement
#读入子元素
enbs = bulkpmmrdatafile.getelementsbytagname(“enb”)
measurements = enbs[0].getelementsbytagname(“measurement”)
objects = measurements[0].getelementsbytagname(“object”)
#写入csv文件
for object in objects:
vs = object.getelementsbytagname(“v”)
vs_cnt += len(vs)
for v in vs:
file_io.write(enbs[0].getattribute(“id”)+’ ‘+object.getattribute(“id”)+’ ‘+\
object.getattribute(“mmeues1apid”)+’ ‘+object.getattribute(“mmegroupid”)+’ ‘+object.getattribute(“mmecode”)+’ ‘+\
object.getattribute(“timestamp”)+’ ‘+v.childnodes[0].data+’\n’) #获取文本值
str_s = (((file_io.getvalue().replace(‘ \n’,’\r\n’)).replace(‘ ‘,’,’)).replace(‘t’,’ ‘)).replace(‘nil’,”)
xm.close()
file_io.close()
return (str_s,vs_cnt)
程序运行结果:
**************************************************
程序处理启动。
输入目录为:/tmcdata/mro2csv/input31/。
输出目录为:/tmcdata/mro2csv/output31/。
输入目录下.gz文件个数为:12,本次处理其中的12个。
**************************************************
文件计数:1/12.
已读入:/tmcdata/mro2csv/input31/td-lte_mro_nsn_omc_234598_20160224060000.xml.gz.
解析中:
文件计数:2/12.
已读入:/tmcdata/mro2csv/input31/td-lte_mro_nsn_omc_233798_20160224060000.xml.gz.
解析中:
文件计数:3/12.
已读入:/tmcdata/mro2csv/input31/td-lte_mro_nsn_omc_123798_20160224060000.xml.gz.
解析中:
………………………………………
文件计数:12/12.
已读入:/tmcdata/mro2csv/input31/td-lte_mro_nsn_omc_235598_20160224060000.xml.gz.
解析中:
vs行计数:177849,运行时间:107.077867,每秒处理行数:1660。
已写入:/tmcdata/mro2csv/output31/mro_0001.csv。
**************************************************
程序处理结束。
由于dom解析需要将整个文件读入内存,并建立树结构,其内存消耗和时间消耗都比较高,但其优点在于逻辑简单,不需要定义回调函数,便于实现。
2、sax解析
函数定义代码:
def sax_parser(gz):
import os,gzip,cstringio
from xml.parsers.expat import parsercreate
#变量声明
d_enb = {}
d_obj = {}
s = ”
global flag
flag = false
file_io = cstringio.stringio()
#sax解析类
class defaultsaxhandler(object):
#处理开始标签
def start_element(self, name, attrs):
global d_enb
global d_obj
global vs_cnt
if name == ‘enb’:
d_enb = attrs
elif name == ‘object’:
d_obj = attrs
elif name == ‘v’:
file_io.write(d_enb[‘id’]+’ ‘+ d_obj[‘id’]+’ ‘+d_obj[‘mmeues1apid’]+’ ‘+d_obj[‘mmegroupid’]+’ ‘+d_obj[‘mmecode’]+’ ‘+d_obj[‘timestamp’]+’ ‘)
vs_cnt += 1
else:
pass
#处理中间文本
def char_data(self, text):
global d_enb
global d_obj
global flag
if text[0:1].isnumeric():
file_io.write(text)
elif text[0:17] == ‘mr.ltescplrulqci1’:
flag = true
#print(text,flag)
else:
pass
#处理结束标签
def end_element(self, name):
global d_enb
global d_obj
if name == ‘v’:
file_io.write(‘\n’)
else:
pass
#sax解析调用
handler = defaultsaxhandler()
parser = parsercreate()
parser.startelementhandler = handler.start_element
parser.endelementhandler = handler.end_element
parser.characterdatahandler = handler.char_data
vs_cnt = 0
str_s = ”
xm = gzip.open(gz,’rb’)
print(“已读入:%s.\n解析中:” % (os.path.abspath(gz)))
for line in xm.readlines():
parser.parse(line) #解析xml文件内容
if flag:
break
str_s = file_io.getvalue().replace(‘ \n’,’\r\n’).replace(‘ ‘,’,’).replace(‘t’,’ ‘).replace(‘nil’,”) #写入解析后内容
xm.close()
file_io.close()
return (str_s,vs_cnt)
程序运行结果:
**************************************************
程序处理启动。
输入目录为:/tmcdata/mro2csv/input31/。
输出目录为:/tmcdata/mro2csv/output31/。
输入目录下.gz文件个数为:12,本次处理其中的12个。
**************************************************
文件计数:1/12.
已读入:/tmcdata/mro2csv/input31/td-lte_mro_nsn_omc_234598_20160224060000.xml.gz.
解析中:
文件计数:2/12.
已读入:/tmcdata/mro2csv/input31/td-lte_mro_nsn_omc_233798_20160224060000.xml.gz.
解析中:
文件计数:3/12.
已读入:/tmcdata/mro2csv/input31/td-lte_mro_nsn_omc_123798_20160224060000.xml.gz.
解析中:
…………………………………..
文件计数:12/12.
已读入:/tmcdata/mro2csv/input31/td-lte_mro_nsn_omc_235598_20160224060000.xml.gz.
解析中:
vs行计数:177849,运行时间:14.386779,每秒处理行数:12361。
已写入:/tmcdata/mro2csv/output31/mro_0001.csv。
**************************************************
程序处理结束。
sax解析相比dom解析,运行时间大幅缩短,由于sax采用逐行解析,对于处理较大文件其占用内存也少,因此sax解析是目前应用较多的一种解析方法。其缺点在于需要自己实现回调函数,逻辑较为复杂。
3、et解析
函数定义代码:
def et_parser(gz):
import os,gzip,cstringio
import xml.etree.celementtree as et
vs_cnt = 0
str_s = ”
file_io = cstringio.stringio()
xm = gzip.open(gz,’rb’)
print(“已读入:%s.\n解析中:” % (os.path.abspath(gz)))
tree = et.elementtree(file=xm)
root = tree.getroot()
for elem in root[1][0].findall(‘object’):
for v in elem.findall(‘v’):
file_io.write(root[1].attrib[‘id’]+’ ‘+elem.attrib[‘timestamp’]+’ ‘+elem.attrib[‘mmecode’]+’ ‘+\
elem.attrib[‘id’]+’ ‘+ elem.attrib[‘mmeues1apid’]+’ ‘+ elem.attrib[‘mmegroupid’]+’ ‘+ v.text+’\n’)
vs_cnt += 1
str_s = file_io.getvalue().replace(‘ \n’,’\r\n’).replace(‘ ‘,’,’).replace(‘t’,’ ‘).replace(‘nil’,”) #写入解析后内容
xm.close()
file_io.close()
return (str_s,vs_cnt)
程序运行结果:
**************************************************
程序处理启动。
输入目录为:/tmcdata/mro2csv/input31/。
输出目录为:/tmcdata/mro2csv/output31/。
输入目录下.gz文件个数为:12,本次处理其中的12个。
**************************************************
文件计数:1/12.
已读入:/tmcdata/mro2csv/input31/td-lte_mro_nsn_omc_234598_20160224060000.xml.gz.
解析中:
文件计数:2/12.
已读入:/tmcdata/mro2csv/input31/td-lte_mro_nsn_omc_233798_20160224060000.xml.gz.
解析中:
文件计数:3/12.
已读入:/tmcdata/mro2csv/input31/td-lte_mro_nsn_omc_123798_20160224060000.xml.gz.
解析中:
…………………………………….
文件计数:12/12.
已读入:/tmcdata/mro2csv/input31/td-lte_mro_nsn_omc_235598_20160224060000.xml.gz.
解析中:
vs行计数:177849,运行时间:4.308103,每秒处理行数:41282。
已写入:/tmcdata/mro2csv/output31/mro_0001.csv。
**************************************************
程序处理结束。
相较于sax解析,et解析时间更短,并且函数实现也比较简单,所以et具有类似dom的简单逻辑实现且匹敌sax的解析效率,因此et是目前xml解析的首选。
4、et_iter解析
函数定义代码:
def et_parser_iter(gz):
import os,gzip,cstringio
import xml.etree.celementtree as et
vs_cnt = 0
str_s = ”
file_io = cstringio.stringio()
xm = gzip.open(gz,’rb’)
print(“已读入:%s.\n解析中:” % (os.path.abspath(gz)))
d_enb = {}
d_obj = {}
i = 0
for event,elem in et.iterparse(xm,events=(‘start’,’end’)):
if i >= 2:
break
elif event == ‘start’:
if elem.tag == ‘enb’:
d_enb = elem.attrib
elif elem.tag == ‘object’:
d_obj = elem.attrib
elif event == ‘end’ and elem.tag == ‘smr’:
i += 1
elif event == ‘end’ and elem.tag == ‘v’:
file_io.write(d_enb[‘id’]+’ ‘+d_obj[‘timestamp’]+’ ‘+d_obj[‘mmecode’]+’ ‘+d_obj[‘id’]+’ ‘+\
d_obj[‘mmeues1apid’]+’ ‘+ d_obj[‘mmegroupid’]+’ ‘+str(elem.text)+’\n’)
vs_cnt += 1
elem.clear()
str_s = file_io.getvalue().replace(‘ \n’,’\r\n’).replace(‘ ‘,’,’).replace(‘t’,’ ‘).replace(‘nil’,”) #写入解析后内容
xm.close()
file_io.close()
return (str_s,vs_cnt)
程序运行结果:
**************************************************
程序处理启动。
输入目录为:/tmcdata/mro2csv/input31/。
输出目录为:/tmcdata/mro2csv/output31/。
输入目录下.gz文件个数为:12,本次处理其中的12个。
**************************************************
文件计数:1/12.
已读入:/tmcdata/mro2csv/input31/td-lte_mro_nsn_omc_234598_20160224060000.xml.gz.
解析中:
文件计数:2/12.
已读入:/tmcdata/mro2csv/input31/td-lte_mro_nsn_omc_233798_20160224060000.xml.gz.
解析中:
文件计数:3/12.
已读入:/tmcdata/mro2csv/input31/td-lte_mro_nsn_omc_123798_20160224060000.xml.gz.
解析中:
……………………………………………
文件计数:12/12.
已读入:/tmcdata/mro2csv/input31/td-lte_mro_nsn_omc_235598_20160224060000.xml.gz.
解析中:
vs行计数:177849,运行时间:3.043805,每秒处理行数:58429。
已写入:/tmcdata/mro2csv/output31/mro_0001.csv。
**************************************************
程序处理结束。
在引入了et_iter解析后,解析效率比et提升了近50%,而相较于dom解析更是提升了35倍,在解析效率提升的同时,由于其采用了iterparse这个循序解析的工具,其内存占用也是比较小的。
所以,小伙伴们,请好好利用这几种工具吧。
以上就是本文的全部内容,希望对大家的学习有所帮助。