工厂方法(factory method)模式又称为虚拟构造器(virtual constructor)模式或者多态工厂(polymorphic factory)模式,属于类的创建型模式。在工厂方法模式中,父类负责定义创建对象的公共接口,而子类则负责生成具体的对象,这样做的目的是将类的实例化操作延迟到子类中完成,即由子类来决定究竟应该实体化哪一个类。
在简单工厂模式中,一个工厂类处于对产品类进行实例化的中心位置上,它知道每一个产品类的细节,并决定何时哪一个产品类应当被实例化。简单工厂模式的优点是能够使客户端独立于产品的创建过程,并且在系统中引入新产品时无需对客户端进行修改,缺点是当有新产品要加入到系统中时,必须对工厂类进行修改,以加入必要的处理逻辑。简单工厂模式的致命弱点就是处于核心地位的工厂类,因为一旦它无法确定要对哪个类进行实例化时,就无法使用该模式,而工厂方法模式则可以很好地避免这一问题。
考虑这样一个应用程序框架(framework),它可以用来浏览各种格式的文档,如txt、doc、pdf、html等,设计时为了让软件的体系结构能够尽可能地通用,定义了application和document这两个抽象父类,客户必须通过它们的子类来处理某一具体类型的文档。例如,要想利用该框架来编写一个pdf文件浏览器,必须先定义pdfapplication和pdfdocument这两个类,它们应该分别继承于application和document。
application的职责是对document进行管理,并且在需要时创建它们,比如当用户从菜单中选择open或者new的时候,application就要负责创建一个document的实例。显而易见,被实例化的特定document子类是与具体应用相关的,因此application无法预测哪个document的子类将被实例化,它只知道一个新的document何时(when)被创建,但并不知道哪种(which)具体的document将被创建。此时若仍坚持使用简单工厂模式会出现一个非常尴尬的局面:框架必须实例化类,但它只知道不能被实例化的抽象类。
解决的办法是使用工厂方法模式,它封装了哪一个document子类将被创建的信息,并且能够将这些信息从框架中分离出来。如图1所示,application的子类重新定义了application的抽象方法createdocument(),并返回某个恰当的document子类的实例。我们称createdocument()是一个工厂方法(factory method),因为它非常形象地描述了类的实例化过程,即负责”生产”一个对象。
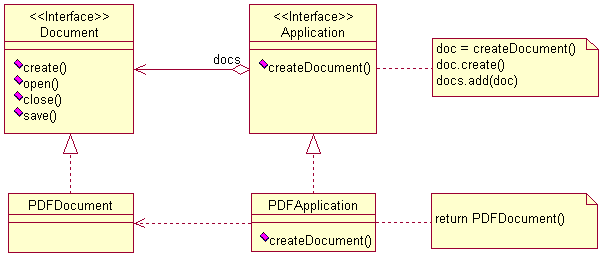
简单说来,工厂方法模式的作用就是可以根据不同的条件生成各种类的实例,这些实例通常属于多个相似的类型,并且具有共同的父类。工厂方法模式将这些实例的创建过程封装了起来,从而简化了客户程序的编写,并改善了软件体系结构的可扩展性,使得将来能够以最小的代价加入新的子类。工厂方法这一模式适合在如下场合中运用:
当无法得知必须创建的对象属于哪个类的时候,或者无法得知属于哪个类的对象将被返回的时候,但前提是这些对象都符合一定的接口标准。
当一个类希望由它的子类来决定所创建的对象的时候,其目的是使程序的可扩展性更好,在加入其他类时更具弹性。
当创建对象的职责被委托给多个帮助子类(helper subclass)中的某一个,并且希望将哪个子类是代理者这一信息局部化的时候。
需要说明的是,使用工厂方法模式创建对象并不意味着一定会让代码变得更短(实事上往往更长),并且可能需要设计更多的辅助类,但它的确可以灵活地、有弹性地创建尚未确定的对象,从而简化了客户端应用程序的逻辑结构,并提高了代码的可读性和可重用性。
拿一个动物工厂来举例说明
class animal(object):
def eat(self, food):
raise notimplementederror()
class dog(animal):
def eat(self, food):
print ‘狗吃’, food
class cat(animal):
def eat(self, food):
print ‘猫吃’, food
class animalfactory(object):
def create_animal(self):
raise notimplementederror()
class dogfactory(animal):
def create_animal(self):
return dog()
class catfactory(animalfactory):
def create_animal(self):
return cat()
def client():
animal_factory = dogfactory()
animal = animal_factory.create_animal()
animal.eat(‘肉骨头’)
animal_factory = catfactory()
animal = animal_factory.create_animal()
animal.eat(‘鱼骨头’)
下面是简单工厂模式的实现:
class animal(object):
def eat(self, food):
raise notimplementederror()
class dog(animal):
def eat(self, food):
print ‘狗吃’, food
class cat(animal):
def eat(self, food):
print ‘猫吃’, food
def create_animal(name):
if name == ‘dog’:
return dog()
elif name == ‘cat’:
return cat()
def client():
animal = create_animal(‘dog’)
animal.eat(‘肉骨头’)
animal = create_animal(‘cat’)
animal.eat(‘鱼骨头’)
看起来工厂方法模式要复杂很多啊,也没觉得比简单工厂模式有什么好处,为什么还要用工厂方法模式呢? 简单工厂模式的优点很明显,工厂函数封装了逻辑判断,客户端使用负担要小很多。相应的问题也很明显,要增加新的产品类型,就需要修改工厂函数,这违背了开闭原则。 但是工厂方法模式似乎绕了一圈又回到原始时代了,下面写不就行了吗,何必外面套一层factory:
class animal(object):
def eat(self, food):
raise notimplementederror()
class dog(animal):
def eat(self, food):
print ‘狗吃’, food
class cat(animal):
def eat(self, food):
print ‘猫吃’, food
def client():
dog = dog()
dog.eat(‘肉骨头’)
cat = cat()
cat.eat(‘鱼骨头’)
工厂方法模式,对于需要做强类型检查的语言比如java、c++等在组织代码时是有好处的。对于python这种动态语言来说,感觉体现不出太多价值,或许我还没有理解工厂方法模式的真谛。