作为一个新世纪有思想有文化有道德时刻准备着的屌丝男青年,在现在这样一个社会中,心疼我大慢播抵制大百度的前提下,没事儿上上网逛逛yy看看斗鱼翻翻美女图片那是必不可少的,可是美图虽多翻页费劲!今天我们就搞个爬虫把美图都给扒下来!本次实例有2个:煎蛋上的妹子图,某网站的rosi图。我只是一个学习python的菜鸟,技术不可耻,技术是无罪的!!!
煎蛋:
先说说程序的流程:获取煎蛋妹子图url,得到网页代码,提取妹子图片地址,访问图片地址并将图片保存到本地。ready? 先让我们看看煎蛋妹子网页:
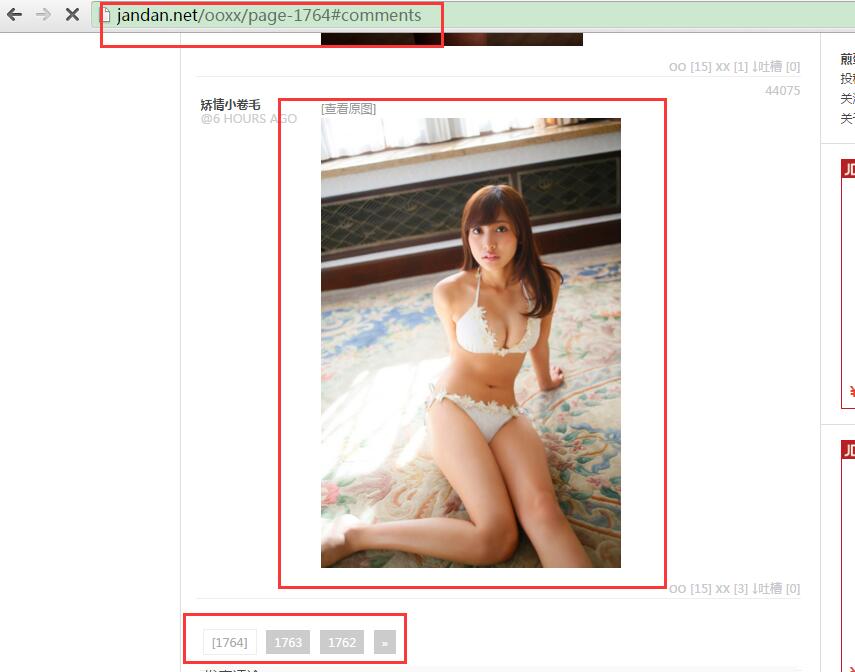
我们得到url为:http://jandan.net/ooxx/page-1764#comments 1764就是页码, 首先我们要得到最新的页码,然后向前寻找,然后得到每页中图片的url。下面我们分析网站代码写出正则表达式!
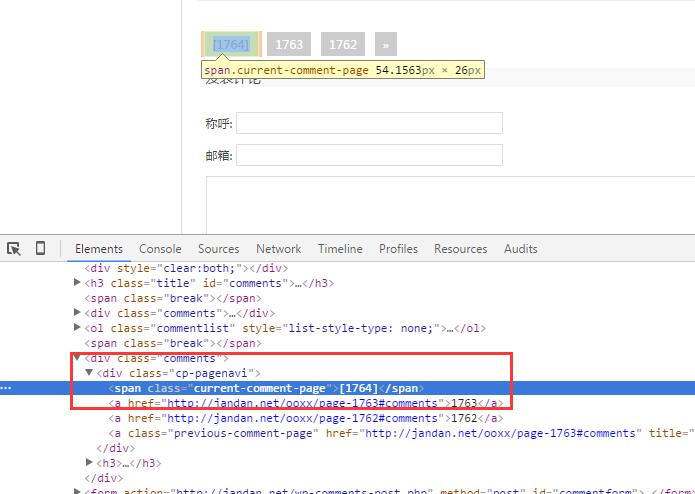
根据之前文章的方法我们写出如下函数getnewpage:
def __getnewpage(self):
pagecode = self.get(self.__url)
type = sys.getfilesystemencoding()
pattern = re.compile(r’
.*?\[(.*?)\]’,re.s)
newpage = re.search(pattern,pagecode.decode(“utf-8”).encode(type))
print pagecode.decode(“utf-8”).encode(type)
if newpage != none:
return newpage.group(1)
return 1500
def start(self):
isexists=os.path.exists(self.__floder)#检测是否存在目录
print isexists
if not isexists:
os.mkdir(self.__floder)
os.chdir(self.__floder)
page = int(self.__getnewpage())
for i in range(self.__pageindex,page):
self.__getallpicurl(i)
if __name__ == ‘__main__’:
jd = jiandan()
jd.start()
jiandan