超文本传输协议http构成了万维网的基础,它利用uri(统一资源标识符)来识别internet上的数据,而指定文档地址的uri被称为url(既统一资源定位符),常见的url指向文件、目录或者执行复杂任务的对象(如数据库查找,internet搜索),而爬虫实质上正是通过对这些url进行访问、操作,从而获取我们想要的内容。对于没有商业需求的我们而言,想要编写爬虫的话,使用urllib,urllib2与cookielib三个模块便可以完成很多需求了。
首先要说明的是,urllib2并非是urllib的升级版,虽然同样作为处理url的相关模块,个人推荐尽量使用urllib2的接口,但我们并不能用urllib2完全代替urllib,处理url资源有时会需要urllib中的一些函数(如urllib.urllencode)来处理数据。但二者处理url的大致思想都是通过底层封装好的接口让我们能够对url像对本地文件一样进行读取等操作。
下面就是一个获取百度页面内容的代码:
import urllib2
connect= urllib2.request(‘http://www.baidu.com’)
url1 = urllib2.urlopen(connect)
print url.read()
短短4行在运行之后,就会显示出百度页面的源代码。它的机理是什么呢?
当我们使用urllib2.request的命令时,我们就向百度搜索的url(“www.baidu.com”)发出了一次http请求,并将该请求映射到connect变量中,当我们使用urllib2.urlopen操作connect后,就会将connect的值返回到url1中,然后我们就可以像操作本地文件一样对url1进行操作,比如这里我们就使用了read()函数来读取该url的源代码。
这样,我们就可以写一只属于自己的简单爬虫了~下面是我写的抓取天涯连载的爬虫:
import urllib2
url1=”http://bbs.tianya.cn/post-16-835537-”
url3=”.shtml#ty_vip_look[%e6%8b%89%e9%a3%8e%e7%86%8a%e7%8c%ab”
for i in range(1,481):
a=urllib2.request(url1+str(i)+url3)
b=urllib2.urlopen(a)
path=str(“d:/noval/天眼传人”+str(i)+”.html”)
c=open(path,”w+”)
code=b.read()
c.write(code)
c.close
print “当前下载页数:”,i
事实上,上面的代码使用urlopen就可以达到相同的效果了:
import urllib2
url1=”http://bbs.tianya.cn/post-16-835537-”
url3=”.shtml#ty_vip_look[%e6%8b%89%e9%a3%8e%e7%86%8a%e7%8c%ab”
for i in range(1,481):
#a=urllib2.request(url1+str(i)+url3)
b=urllib2.urlopen((url1+str(i)+url3)
path=str(“d:/noval/天眼传人”+str(i)+”.html”)
c=open(path,”w+”)
code=b.read()
c.write(code)
c.close
print “当前下载页数:”,i
为什么我们还需要先对url进行request处理呢?这里需要引入opener的概念,当我们使用urllib处理url的时候,实际上是通过urllib2.openerdirector实例进行工作,他会自己调用资源进行各种操作如通过协议、打开url、处理cookie等。而urlopen方法使用的是默认的opener来处理问题,也就是说,相当的简单粗暴~对于我们post数据、设置header、设置代理等需求完全满足不了。
因此,当面对稍微高点的需求时,我们就需要通过urllib2.build_opener()来创建属于自己的opener,这部分内容我会在下篇博客中详细写~
而对于一些没有特别要求的网站,仅仅使用urllib的2个模块其实就可以获取到我们想要的信息了,但是一些需要模拟登陆或者需要权限的网站,就需要我们处理cookies后才能顺利抓取上面的信息,这时候就需要cookielib模块了。cookielib 模块就是专门用来处理cookie相关了,其中比较常用的方法就是能够自动处理cookie的cookiejar()了,它可以自动存储http请求生成的cookie,并向传出http的请求中自动添加cookie。正如我前文所提到的,想要使用它的话,需要创建一个新的opener:
import cookielib, urllib2
cj = cookielib.cookiejar()
opener = urllib2.build_opener(urllib2.httpcookieprocessor(cj))
经过这样的处理后,cookie的问题就解决了~
而想要将cookies输出出来的话,使用print cj._cookies.values()命令后就可以了~
抓取豆瓣同城、登陆图书馆查询图书归还
在掌握了urllib几个模块的相关用法后,接下来就是进入实战步骤了~
(一)抓取豆瓣网站同城活动
豆瓣北京同城活动 该链接指向豆瓣同城活动的列表,向该链接发起request:
# encoding=utf-8
import urllib
import urllib2
import cookielib
import re
cj=cookielib.cookiejar()
opener=urllib2.build_opener(urllib2.httpcookieprocessor(cj))
url=”http://beijing.douban.com/events/future-all?start=0″
req=urllib2.request(url)
event=urllib2.urlopen(req)
str1=event.read()
我们会发现返回的html代码中,除了我们需要的信息之外,还夹杂了大量的页面布局代码:

如上图所示,我们只需要中间那些关于活动的信息。而为了提取信息,我们就需要正则表达式了~
正则表达式是一种跨平台的字符串处理工具/方法,通过正则表达式,我们可以比较轻松的提取字符串中我们想要的内容~
这里不做详细介绍了,个人推荐余晟老师的正则指引,挺适合新手入门的。下面给出正则表达式的大致语法:
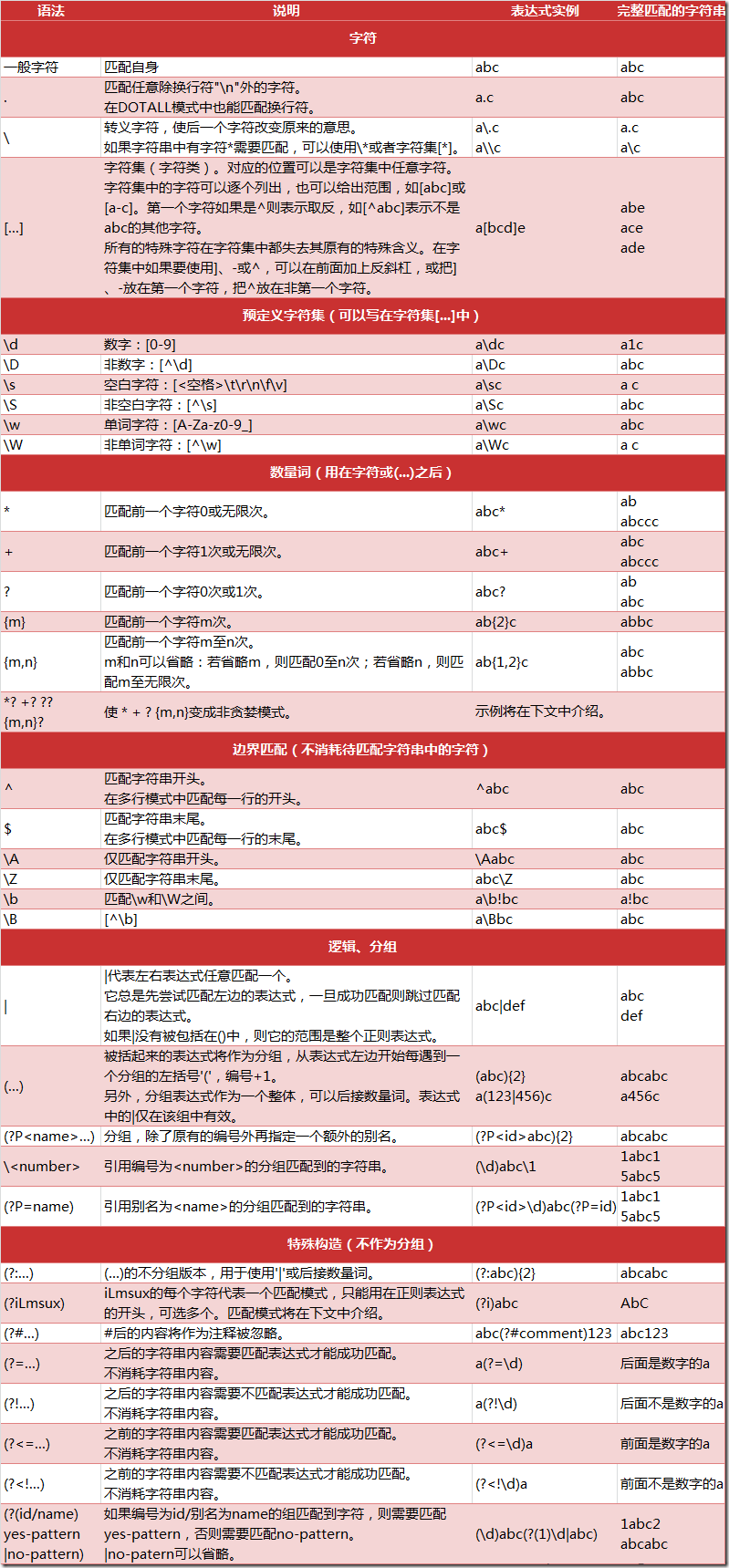
这里我使用捕获分组,将活动四要素(名称,时间,地点,费用)为标准进行分组,得到的表达式如下:
代码如下:
regex=re.compile(r’summary”>([\d\d]*?)[\d\d]*?>([\d\d]*?)([\d\d]*?)’)
这样就可以将几个部分提取出来了。
总体代码如下:
# -*- coding: utf-8 -*-
#—————————————
# program:豆瓣同城爬虫
# author:gislu
# data:2014-02-08
#—————————————
import urllib
import urllib2
import cookielib
import re
cj=cookielib.cookiejar()
opener=urllib2.build_opener(urllib2.httpcookieprocessor(cj))
#正则提取
def search(str1):
regex=re.compile(r’summary”>([\d\d]*?)[\d\d]*?>([\d\d]*?)([\d\d]*?)’)
for i in regex.finditer(str1):
print “活动名称:”,i.group(1)
a=i.group(2)
b=a.replace(”,”)
print b.replace(‘\n’,”)
print ‘活动地点:’,i.group(3)
c=i.group(4).decode(‘utf-8’)
print ‘费用:’,c
#获取url
for i in range(0,5):
url=”http://beijing.douban.com/events/future-all?start=”
url=url+str(i*10)
req=urllib2.request(url)
event=urllib2.urlopen(req)
str1=event.read()
search(str1)
在这里需要注意一下编码的问题,因为我使用的版本还是python2.x,所以在内部汉字字符串传递的时候需要来回转换,比如在最后打印“费用“这一项的时候,必须使用
i.group(4).decode(‘utf-8’) 将group(4元组中的ascii码转换为utf8格式才行,否则会发现输出的是乱码。
而在python中,正则模块re提供了两种常用的全局查找方式:findall 和 finditer,其中findall是一次性处理完毕,比较消耗资源;而finditer则是迭代进行搜索,个人比较推荐使用这一方法。
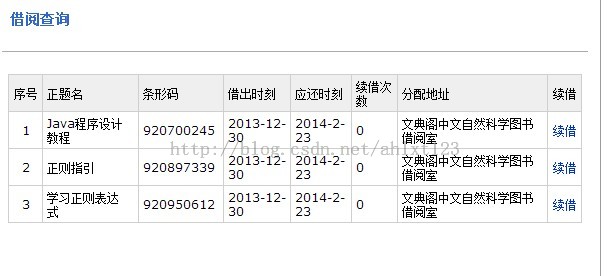
最后得到的结果如下,大功告成~

(二)模拟登陆图书馆系统查询书籍归还情况
既然我们能够通过python向指定网站发出请求获取信息,那么自然也能通过python模拟浏览器进行登陆等操作~
而模拟的关键,就在于我们向指定网站服务器发送的信息需要和浏览器的格式一模一样才行~
这就需要分析出我们想要登陆的那个网站接受信息的方式。通常我们需要对浏览器的信息交换进行抓包~
抓包软件中,目前比较流行的是wireshark,相当强大~不过对于我们新手来说,ie、foxfire或者chrome自带的工具就足够我们使用了~
这里就以本人学校的图书馆系统为例子~
我们可以通过模拟登陆,最后进入图书管理系统查询我们借阅的图书归还情况。首先要进行抓包分析我们需要发送哪些信息才能成功模拟浏览器进行登陆操作。
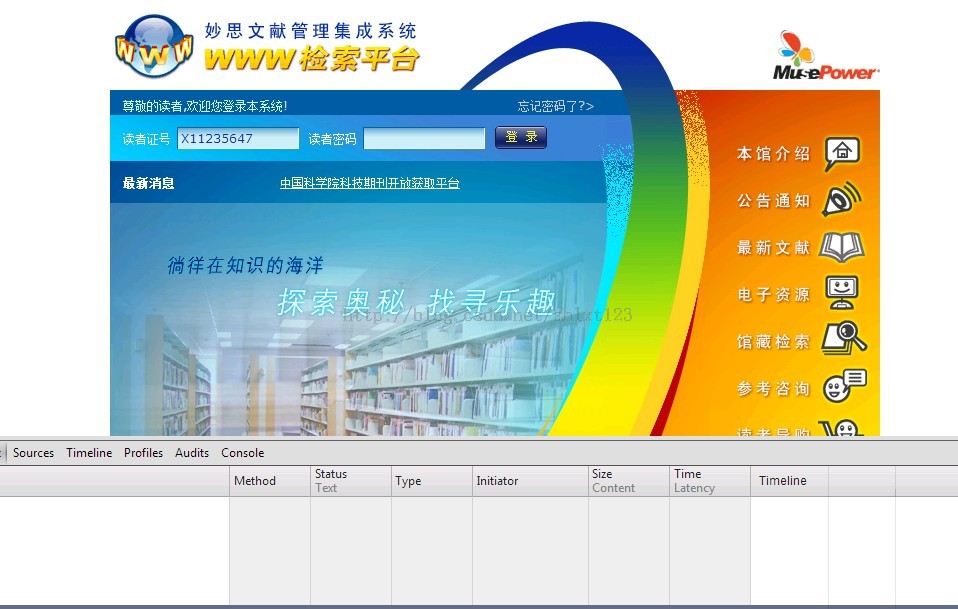
我使用的是chrome浏览器,在登陆页面按f12调出chrome自带的开发工具,选择network项就可以输入学号密码选择登陆了。
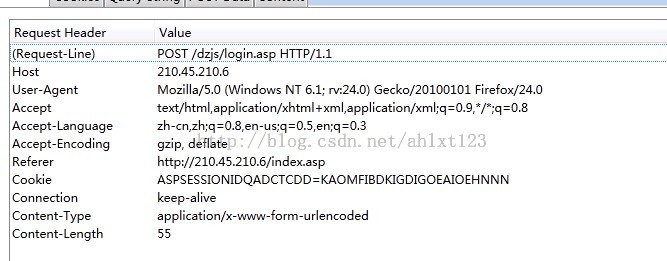
观察登陆过程中的网络活动,果然发现可疑分子了:

分析这个post指令后,可以确认其就是发送登陆信息(账号、密码等)的关键命令。
还好我们学校比较穷,网站做的一般,这个包完全没有加密~那么剩下的就很简单了~记下headers跟post data就ok了~
其中headers中有很多实用的信息,一些网站可能会根据user-agent来判断你是否是爬虫程序从而决定是否允许你访问,而referer则是很多网站常常用来反盗链的,如果服务器接收到的请求中referer与管理员设定的规则不符,那么服务器也会拒绝发送资源。
而post data就是我们在登录过程中浏览器向登陆服务器post的信息了,通常账户、密码之类的数据都包含在里面。这里往往还有一些其他的数据如布局等信息也要发送出去,这些信息通常我们在操作浏览器的时候没有任何存在感,但没了他们服务器是不会响应我们滴。
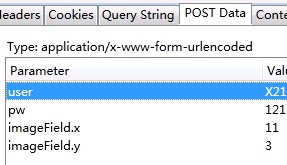
现在postdata 跟headers的格式我们全部知道了~模拟登陆就很简单了:
import urllib
#—————————————
# @program:图书借阅查询
# @author:gislu
# @data:2014-02-08
#—————————————
import urllib2
import cookielib
import re
cj=cookielib.cookiejar()
opener=urllib2.build_opener(urllib2.httpcookieprocessor(cj))
opener.addheaders = [(‘user-agent’,’mozilla/4.0 (compatible; msie 7.0; windows nt 5.1)’)]
urllib2.install_opener(opener)
#登陆获取cookies
postdata=urllib.urlencode({
‘user’:’x1234564′,
‘pw’:’demacialalala’,
‘imagefield.x’:’0′,
‘imagefield.y’:’0′})
rep=urllib2.request(
url=’http://210.45.210.6/dzjs/login.asp’,
data=postdata
)
result=urllib2.urlopen(rep)
print result.geturl()
其中urllib.urlencode负责将postdata自动进行格式转换,而opener.addheaders则是在我们的opener处理器中为后续请求添加我们预设的headers。
测试后发现,登陆成功~~
那么剩下的就是找出图书借还查询所在页面的url,再用正则表达式提取出我们需要的信息了~~
整体代码如下:
import urllib
#—————————————
# @program:图书借阅查询
# @author:gislu
# @data:2014-02-08
#—————————————
import urllib2
import cookielib
import re
cj=cookielib.cookiejar()
opener=urllib2.build_opener(urllib2.httpcookieprocessor(cj))
opener.addheaders = [(‘user-agent’,’mozilla/4.0 (compatible; msie 7.0; windows nt 5.1)’)]
urllib2.install_opener(opener)
#登陆获取cookies
postdata=urllib.urlencode({
‘user’:’x11134564′,
‘pw’:’demacialalala’,
‘imagefield.x’:’0′,
‘imagefield.y’:’0′})
rep=urllib2.request(
url=’http://210.45.210.6/dzjs/login.asp’,
data=postdata
)
result=urllib2.urlopen(rep)
print result.geturl()
#获取账目表
postdata=urllib.urlencode({
‘ncxfs’:’1′,
‘submit1′:’检索’})
aa=urllib2.request(
url=’http://210.45.210.6/dzjs/jhcx.asp’,
data=postdata
)
bb=urllib2.urlopen(aa)
cc=bb.read()
zhangmu=re.findall(‘tdborder4 >(.*?)’,cc)
for i in zhangmu:
i=i.decode(‘gb2312’)
i=i.encode(‘gb2312’)
print i.strip(‘ ‘)
下面是程序运行结果~
