在数据库中存储时,使用 bytes 更精确,可扩展性和灵活性都很高。
输出时,需要做一些适配。
1. 注意事项与测试代码
1.需要考虑 sizeinbytes 为 none 的场景。
2.除以 1024.0 而非 1024,避免丢失精度。
实现的函数为 getsizeinmb(sizeinbytes),通用的测试代码为
def getsizeinmb(sizeinbytes):
return 0
def test(sizeinbytes):
print ‘%s -> %s’ % (sizeinbytes, getsizeinmb(sizeinbytes))
test(none)
test(0)
test(10240000)
test(1024*1024*10)
2. 以 mb 为单位输出 — 返回 float
通常,电子书的大小在 1 – 50mb 之间,输出时统一转为 mb 是不错的选择。
弊端:
1.输出精度过高,比如 10240000 bytes 计算结果为 10240000 -> 9.765625
2.文件大小有限制,小于 1 mb 或 g 级数据不适合该方式展示
优势:
1.适合于用返回值参与计算
def getsizeinmb(sizeinbytes):
return (sizeinbytes or 0) / (1024.0*1024.0)
3. 以 mb 为单位保留 1 位小数 — 返回 str
处于精度问题考虑,可以选择保留 1 位小数。
def getsizeinmb(sizeinbytes):
return ‘%.1f’ % ((sizeinbytes or 0) / (1024.0*1024.0), ) # use 1-dimension tuple is suggested
返回值建议写成 ‘%.1f’ % (number,) 而非 ‘%.1f’ % (number)
二者均能正确执行,但后者容易被误判为执行只有一个参数 number 的函数,导致难以判断的错误。
3. 以 mb 为单位保留至多 1 位小数 — 返回 str
大多数操作系统一般展示至多 1 位小数
def getsizeinmb(sizeinbytes):
sizeinmb = ‘%.1f’ % ((sizeinbytes or 0) / (1024.0*1024.0), ) # use 1-dimension tuple is suggested
return sizeinmb[:-2] if sizeinmb.endswith(‘.0’) else sizeinmb # python2.5+ required
4. 自动选择最佳单位
def getsizeinnicestring(sizeinbytes):
“””
convert the given bytecount into a string like: 9.9bytes/kb/mb/gb
“””
for (cutoff, label) in [(1024*1024*1024, “gb”),
(1024*1024, “mb”),
(1024, “kb”),
]:
if sizeinbytes >= cutoff:
return “%.1f %s” % (sizeinbytes * 1.0 / cutoff, label)
if sizeinbytes == 1:
return “1 byte”
else:
bytes = “%.1f” % (sizeinbytes or 0,)
return (bytes[:-2] if bytes.endswith(‘.0’) else bytes) + ‘ bytes’
算法说明:
1. 从英语语法角度,只有 1 使用单数形式。其他 0/小数 均使用复数形式。涉及 bytes 级别
2. 精度方面,kb 及以上级别,保留 1 位小数。bytes 保留至多 1 位小数。
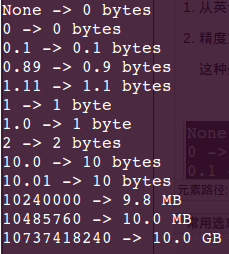
这种处理规则,不适合于小数十分位为 0 的情况,比如 10.0 bytes,10.01 bytes。输入结果均为 10 bytes。
其他情况下,精度均不存在问题。
测试数据与结果如下图
以上内容给大家介绍了基于python实现文件大小输出的相关知识,希望本文分享对大家有所帮助。